Spark Catalogs
A Spark Catalog is a component in Apache Spark that manages metadata for tables and databases within a Spark session. It provides functionalities for creating, dropping, and querying tables, along with accessing their schemas and properties.
IOMETE allows users to configure multiple Spark Catalogs for accessing data both within IOMETE systems and from external sources. This setup supports lakehouse queries and Spark jobs, streamlining data retrieval and management across diverse environments
Catalog Overview
To view all configured Spark Catalogs, navigate to the Settings menu item and switch to the Spark Catalogs tab.
In the list below, you'll find the Spark catalog. The default catalog created by the system is called spark_catalog.
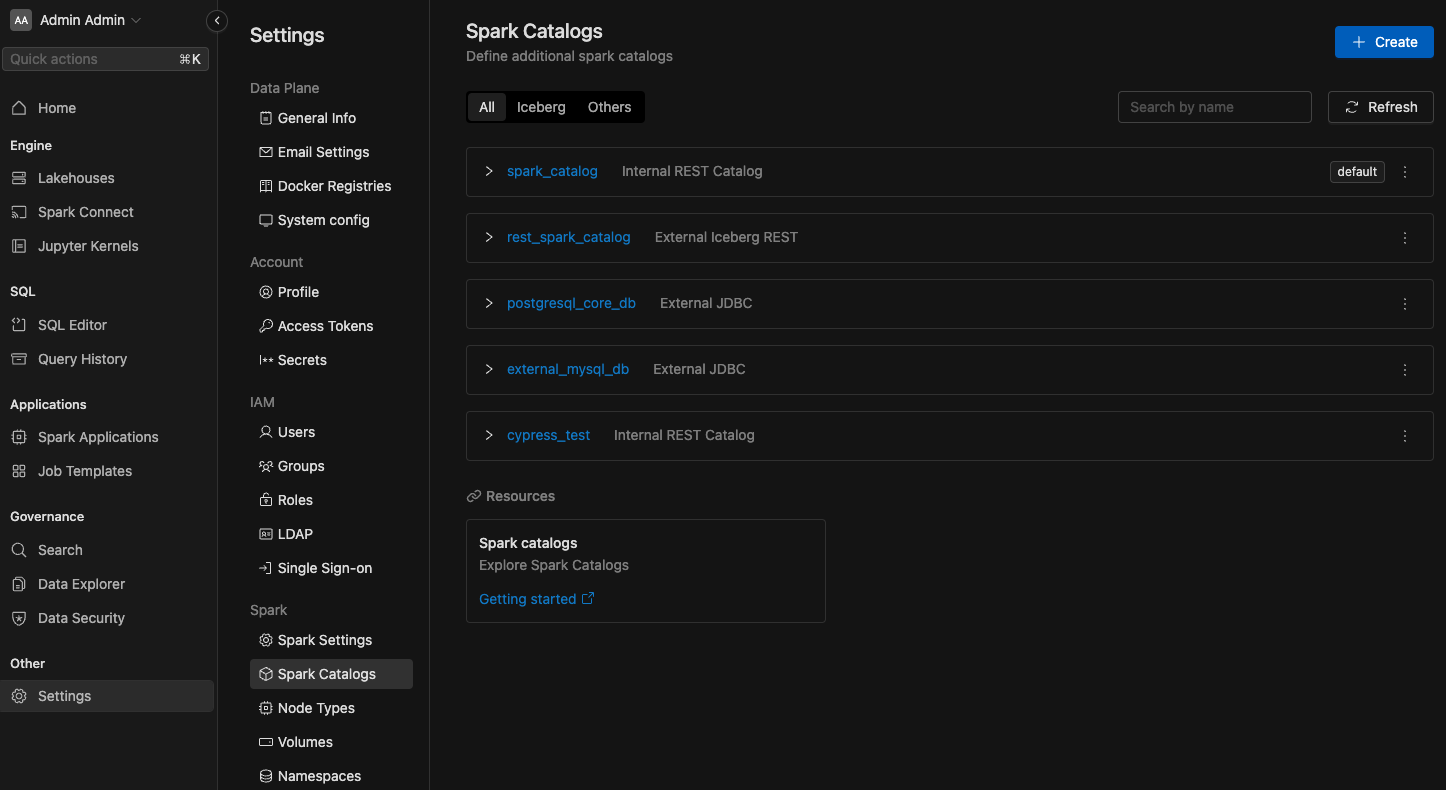
Configuring Managed Catalogs
IOMETE enables the creation of new catalogs that operate as Iceberg REST Catalogs, managed internally by the IOMETE system.
These catalogs are accessible to external tools via the path /catalogs/<catalog name>.
They seamlessly integrate with existing data security rules to enforce role-based access control (RBAC).
For authentication, a session or a PAT token is required.
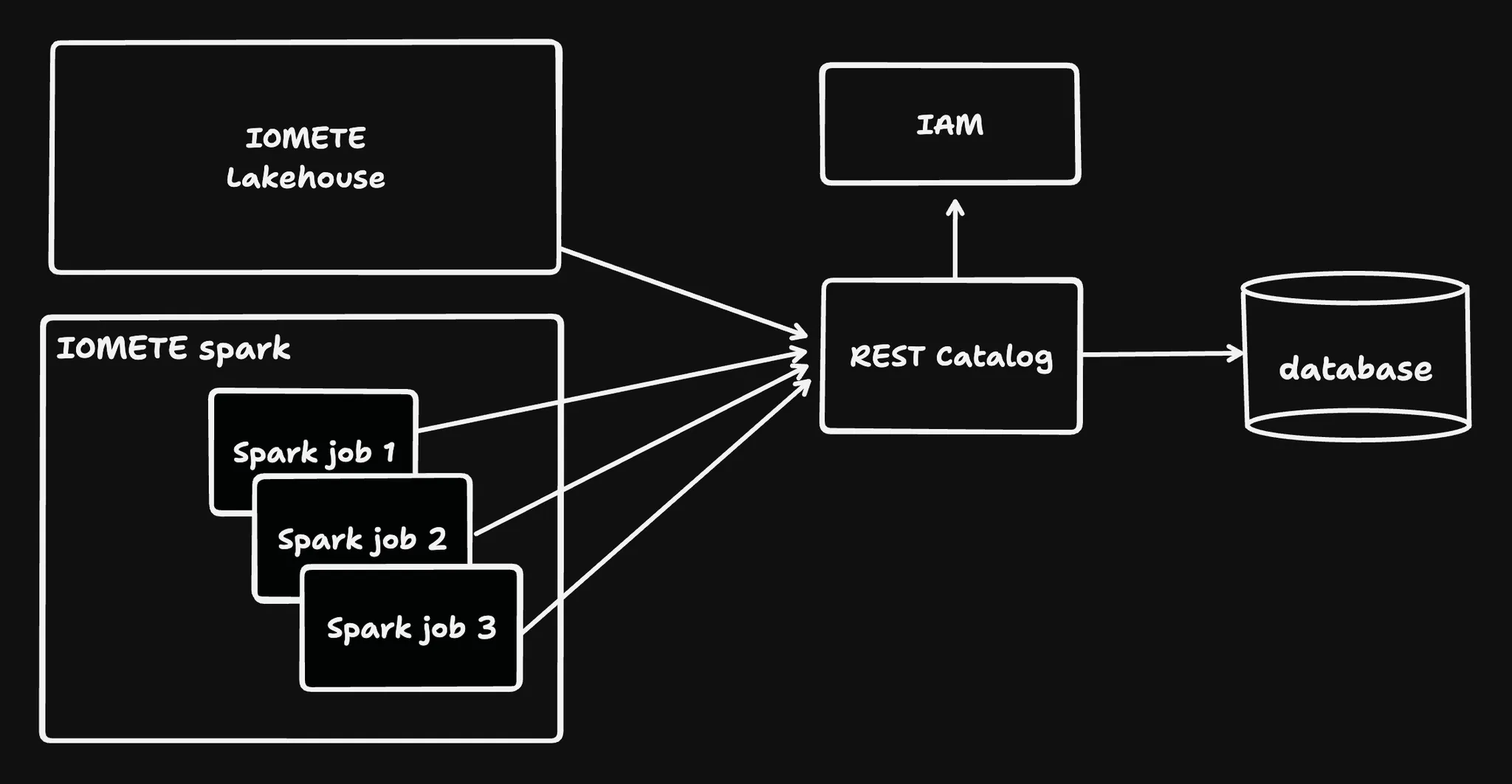
Creating a new Managed Catalog
To add new catalog item, click Create button in the top right corner. You'll see following screen:
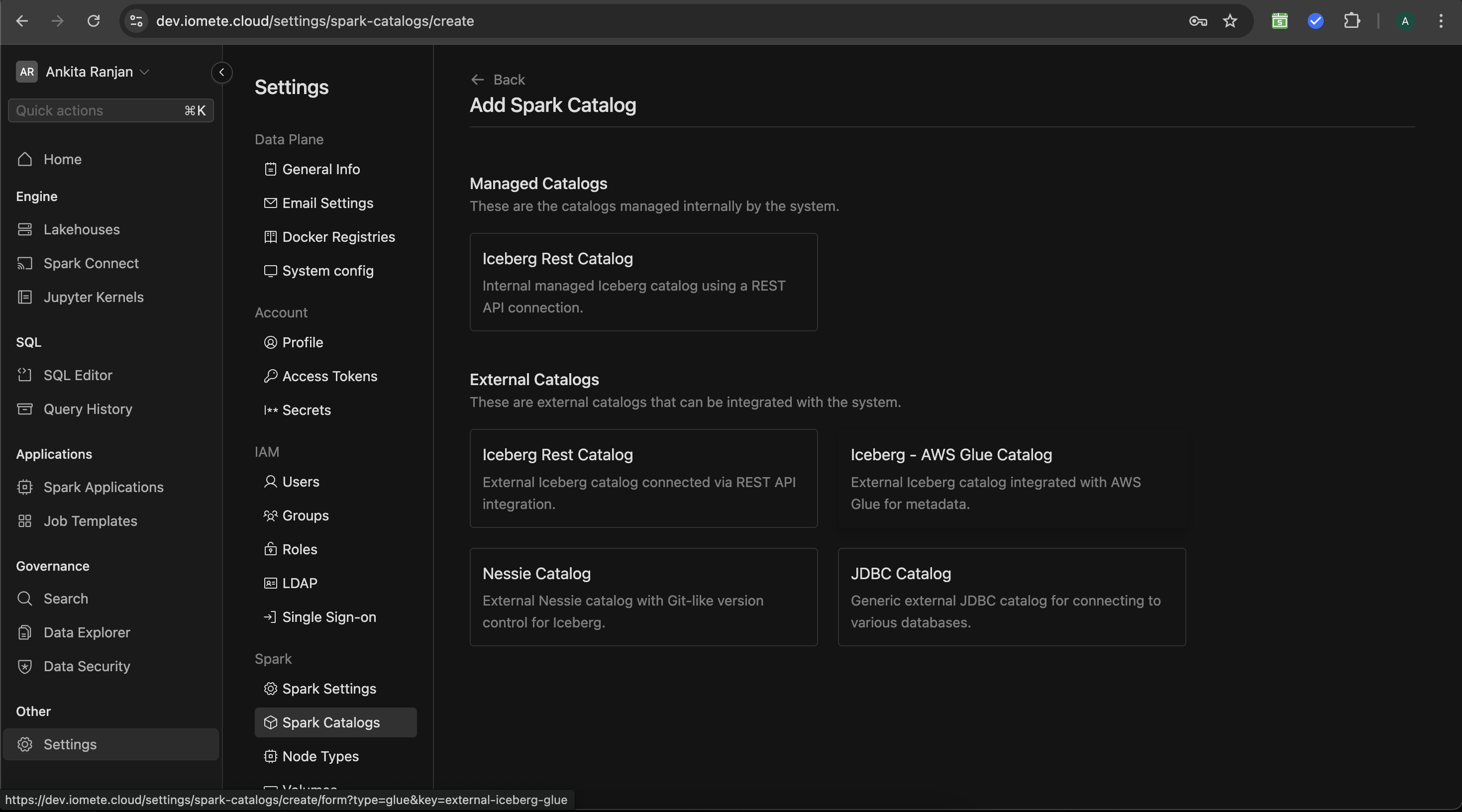
Select Iceberg REST Catalog from the Managed Catalogs section, then following page with inputs will open:
- Name : Name of the catalog
- Warehouse : URL of S3 compatible warehouse (Our platform only supports object stores that are compatible with Amazon S3 APIs)
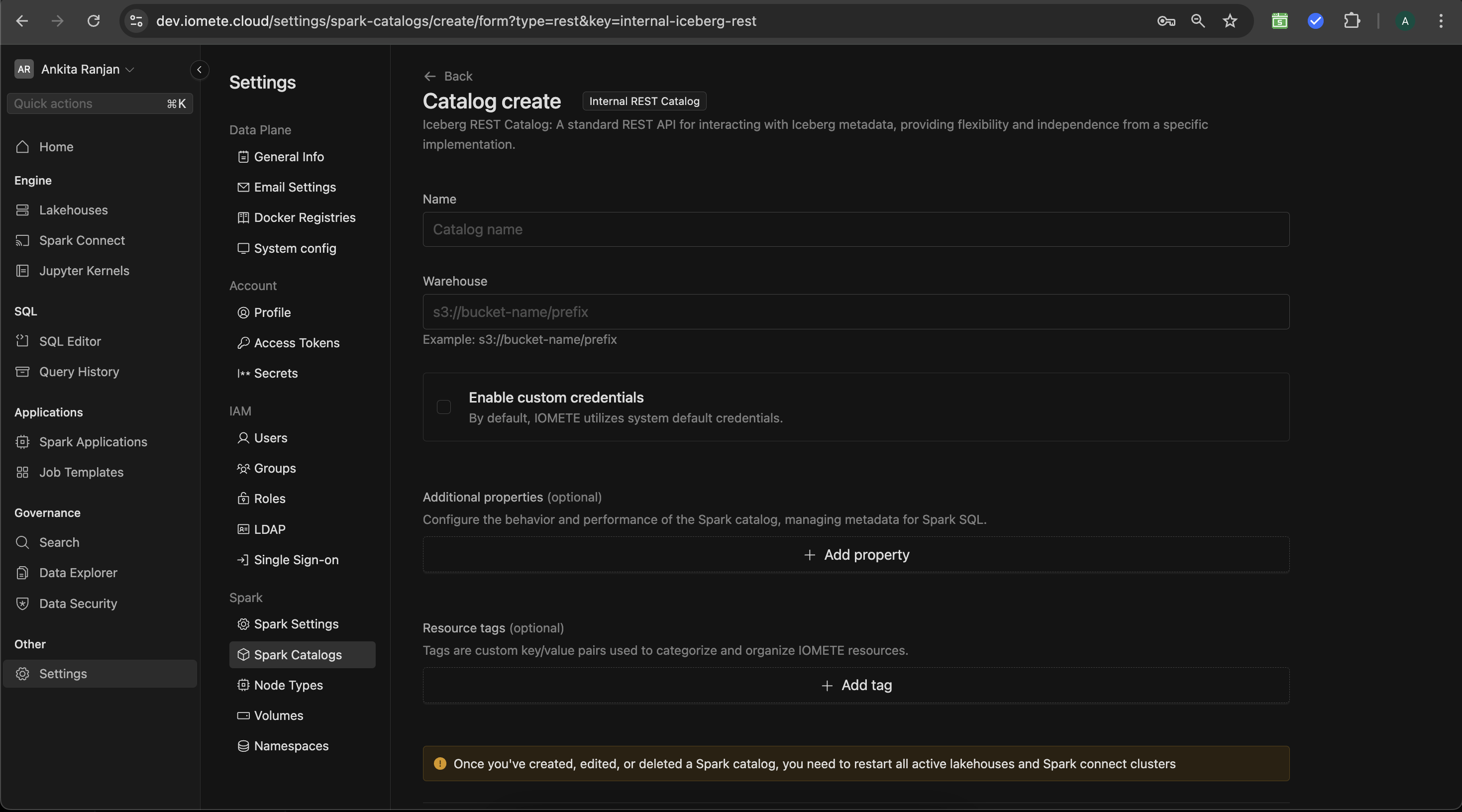
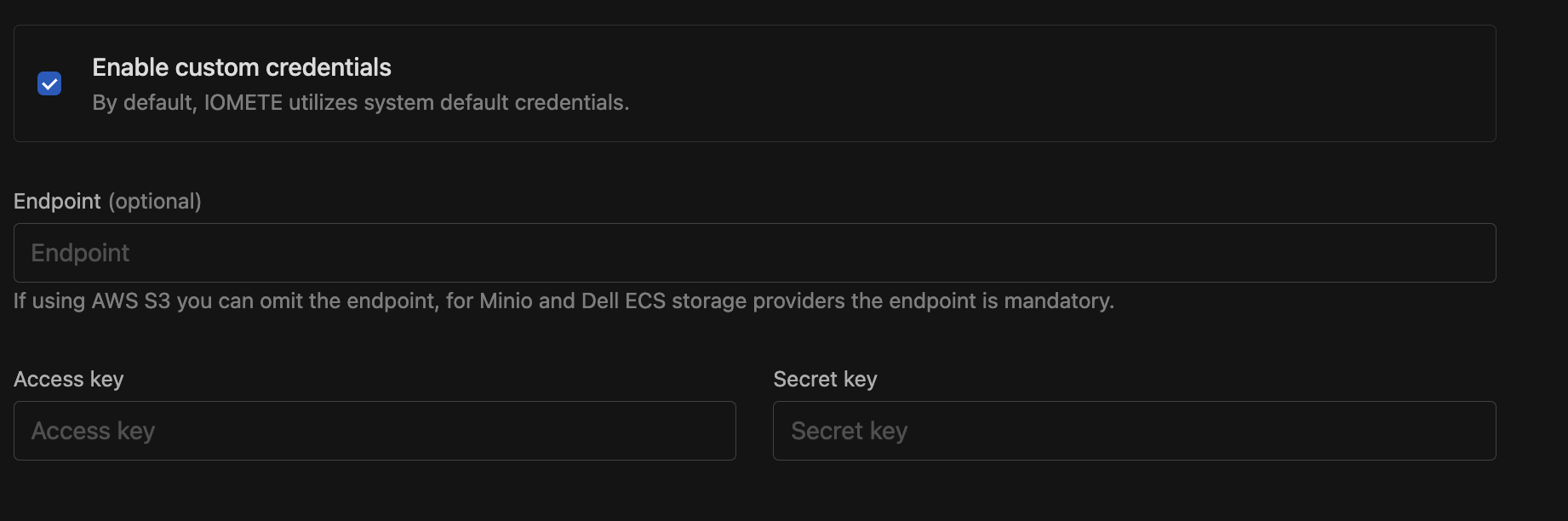
[Optional] Configuring a different S3 Compatible Storage
By default, IOMETE will use the S3 compatible storage and credentials that are configured by your administrator when installing IOMETE.
If you wish to use different credentials or a different storage provider for this catalog,
click on the Enable Custom Credentials checkbox. Then, you'll see additional input fields for your credentials.
- Endpoint - If using AWS S3 you can omit the endpoint, for Minio and Dell ECS storage providers the endpoint is mandatory.
- Access key
- Secret key
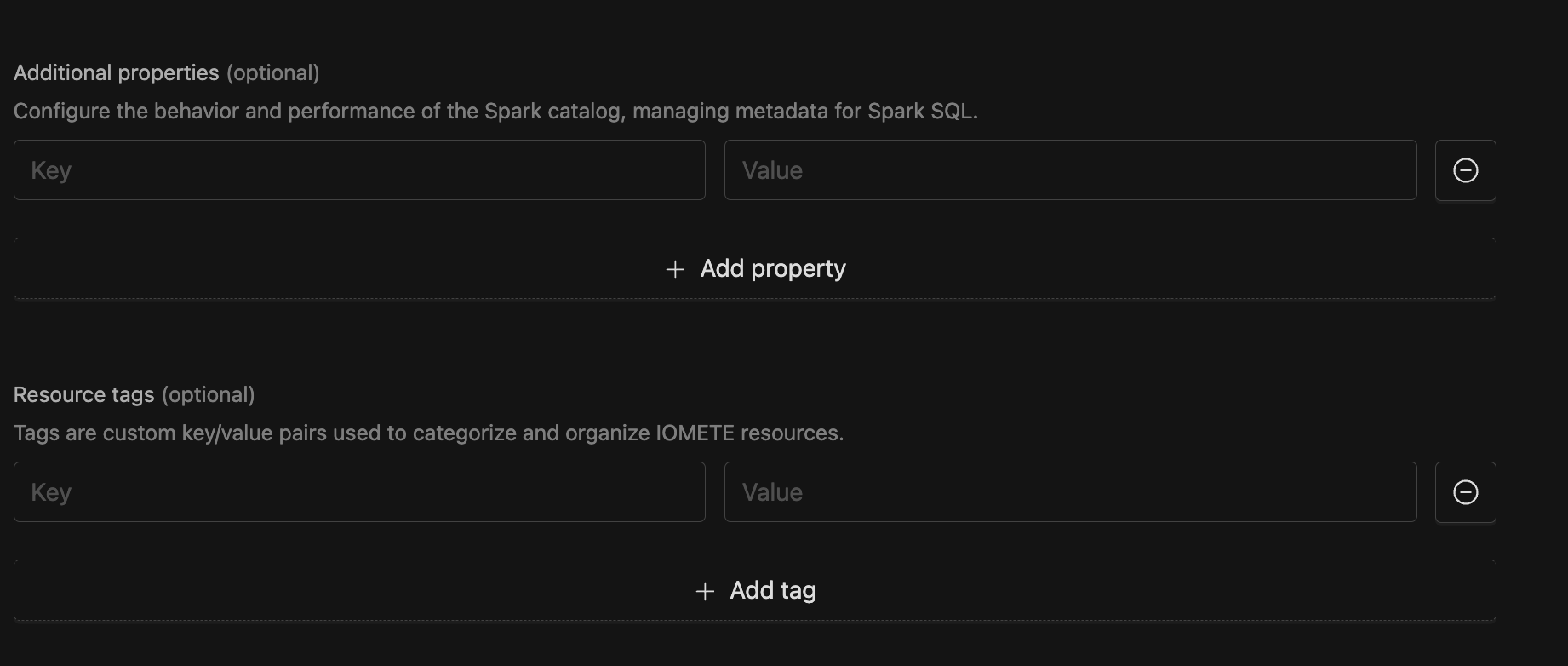
[Optional] Configuring Additional Properties and Resource Tags
You can configure Additional Properties that Catalog Properties that IOMETE will expose for this Catalog. You may also add Resource Tagging.
- Additional Properties (Optional)
- Customize Spark catalog behavior by adding key-value pairs.
- Click Add property
- Enter Key and Value
- Resource Tags (Optional)
- Organize IOMETE resources with custom tags.
- Click Add tag Enter Key and Value
Validating and Saving
After filling all inputs click Test Connection to test the setup. This will run a series of tests to validate connectivity
and various permissions.
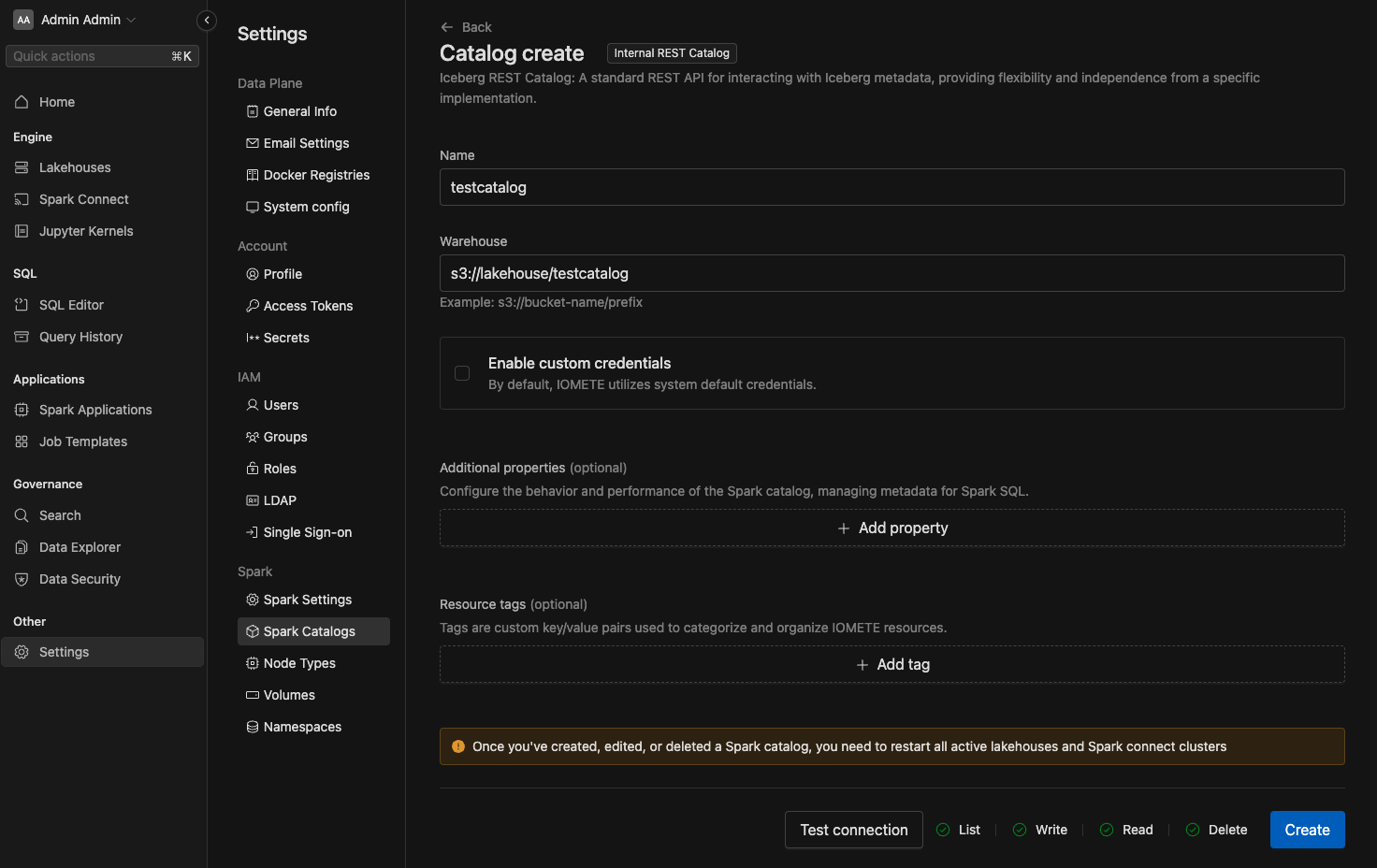
Click Create or Save to save your settings. The new catalog will appear in catalog list.
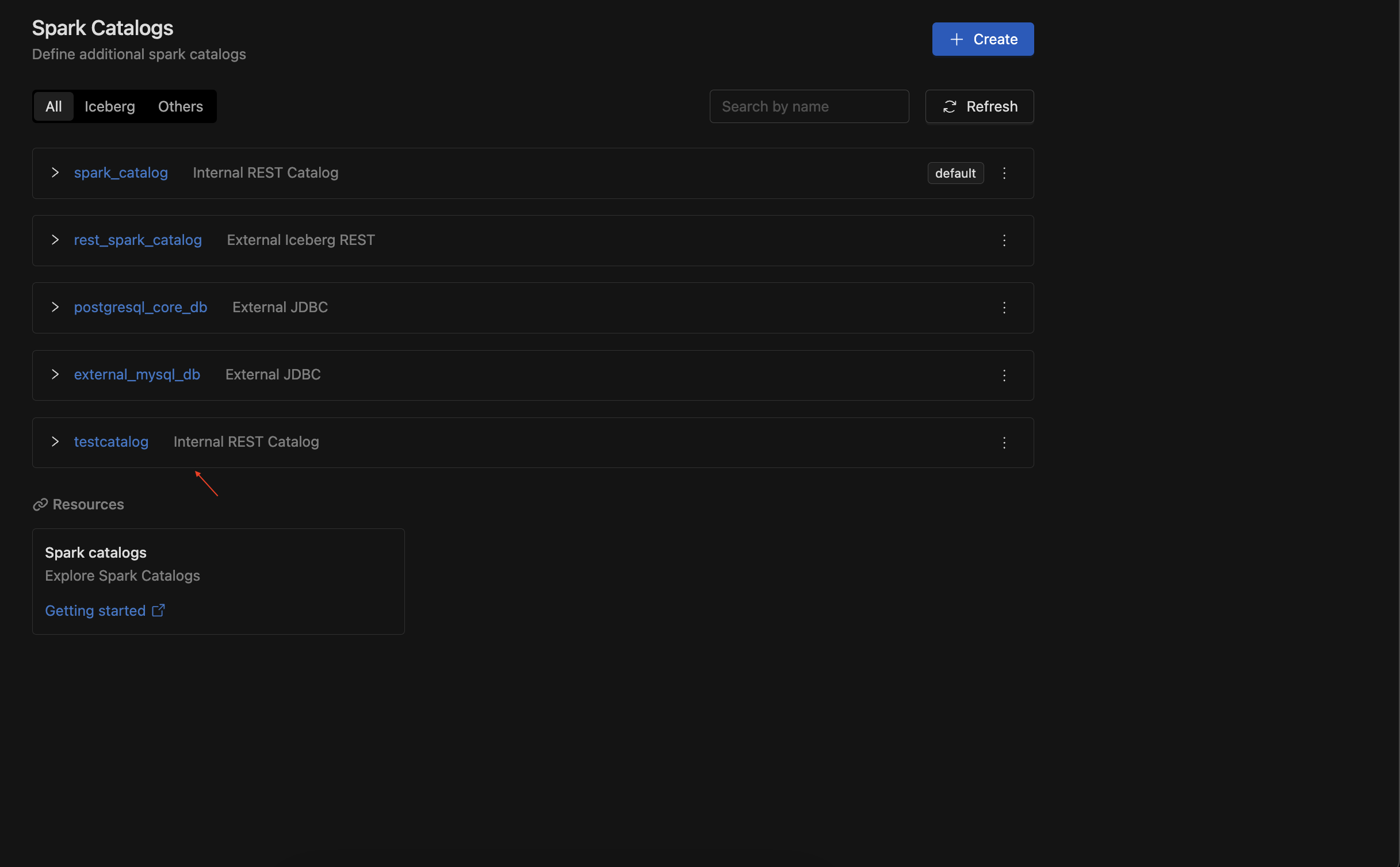
Editing and deleting the default catalog is not permitted; you can only make changes to other catalogs.
Make sure to restart relevant Lakehouses and Spark Connect instances to ensure a newly created Catalog can be used
Configuring External Catalogs
IOMETE can also connect to your existing databases and any Iceberg Catalogs you may already have in operation. This integration allows for seamless data access and management across your current infrastructure, enhancing your data workflows without requiring significant changes.
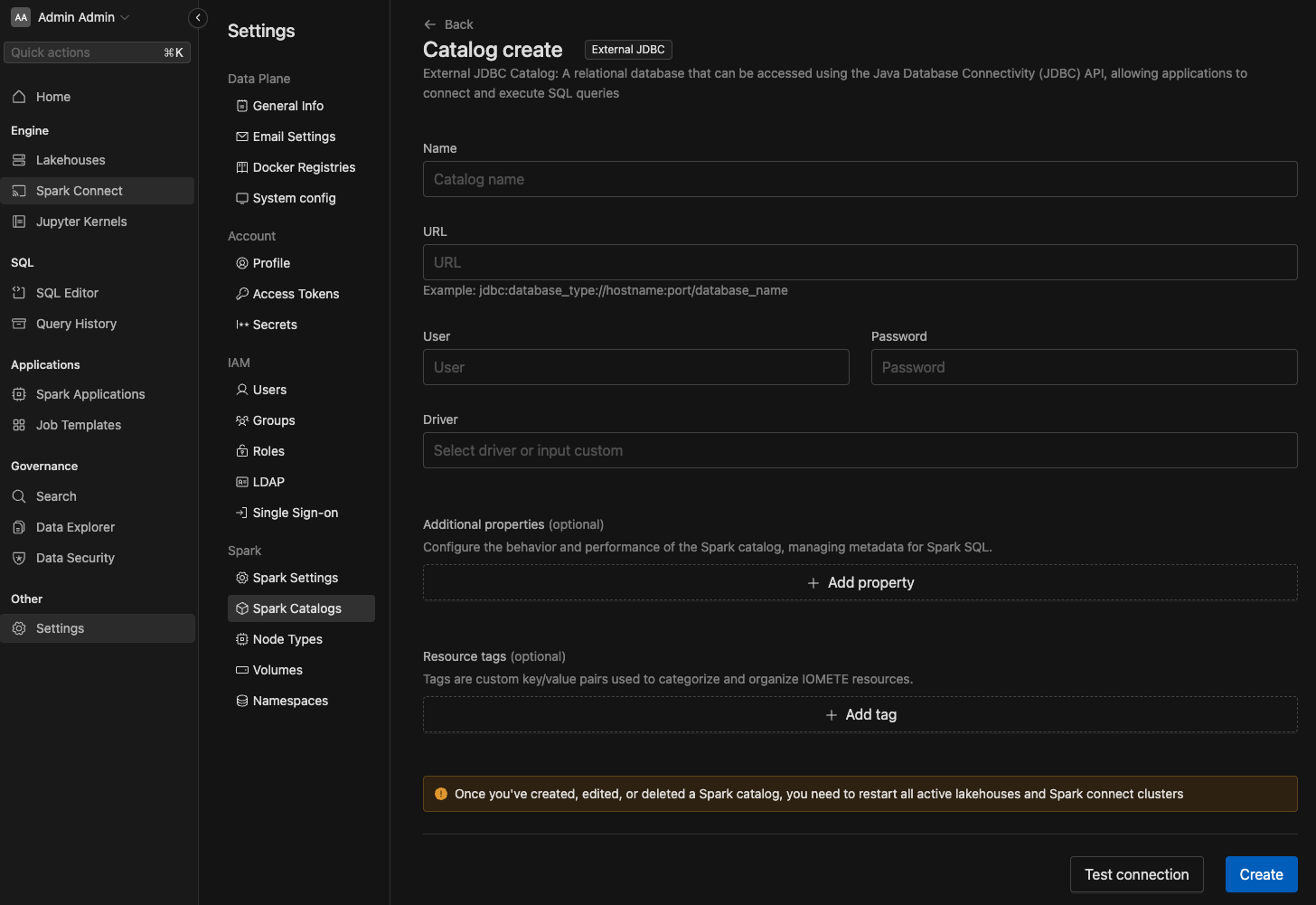
Connecting to JDBC Resources with IOMETE
You can connect IOMETE to any existing JDBC (Java Database Connectivity) resource, which facilitates communication with relational database management systems (RDBMS). This integration enables you to use JDBC resources in various queries and Spark jobs, enhancing your data processing capabilities and allowing for seamless interaction with your existing database systems.
To set up this connection, you must provide:
- Name : Name of the catalog
- URL: The JDBC URL
- Username: A valid username to connect with to the JDBC Resource
- Password: The password associated with the Username
- Driver: The JDBC driver for your database
Connecting to an existing Iceberg Catalog
IOMETE can connect to any of the existing Iceberg Catalogs you might already have
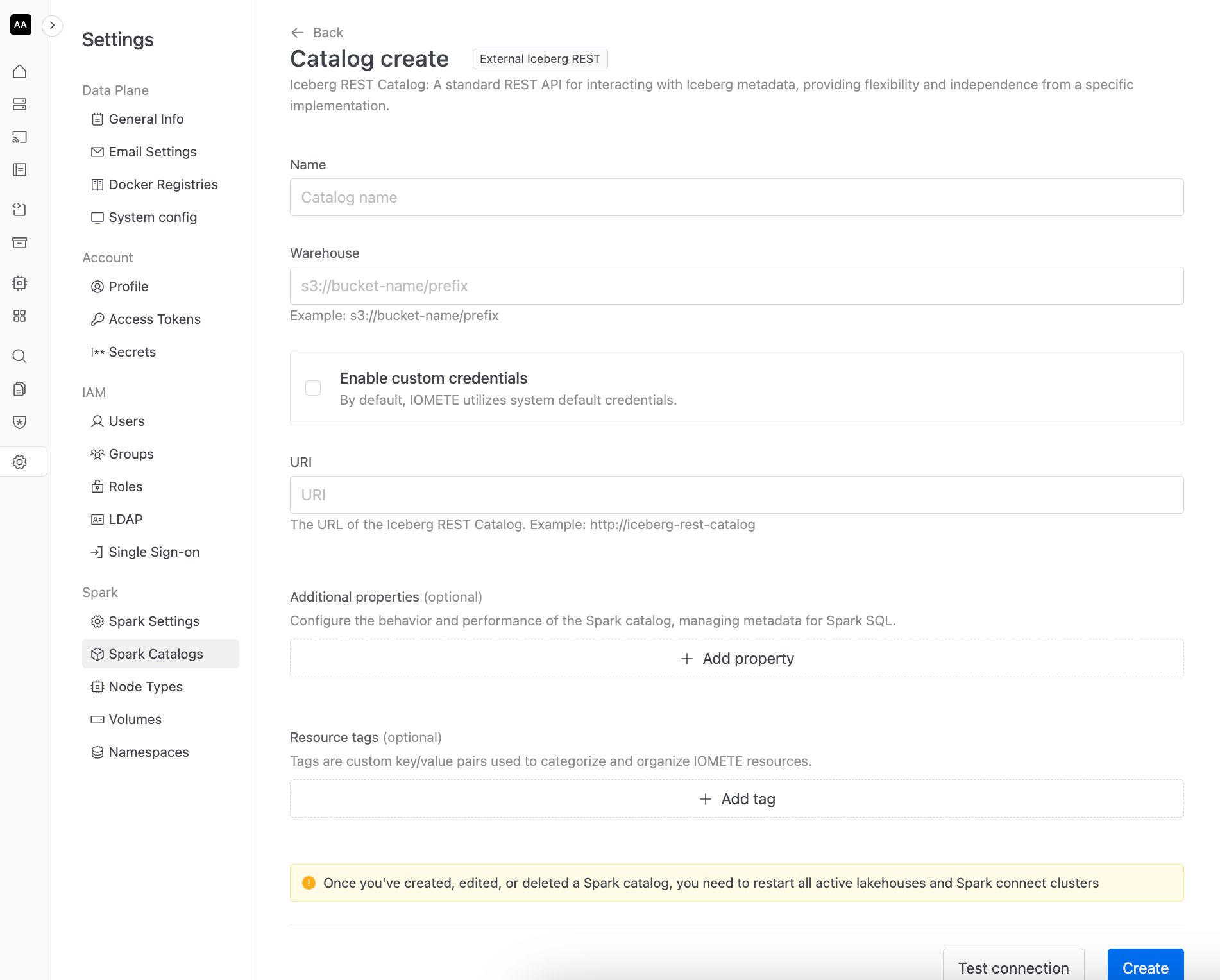
Follow the instructions on each of screens to configure the catalog. For example if you would like to configure a pre-existing REST Catalog, like Polaris or Unity Catalog, you would need to provide:
-
Name : Name of the catalog
-
Warehouse : URL of S3 compatible warehouse (Our platform only supports data warehouses that are compatible with Amazon S3 APIs for storage)
-
URI: the HTTP(S) URL of the REST Catalog
-
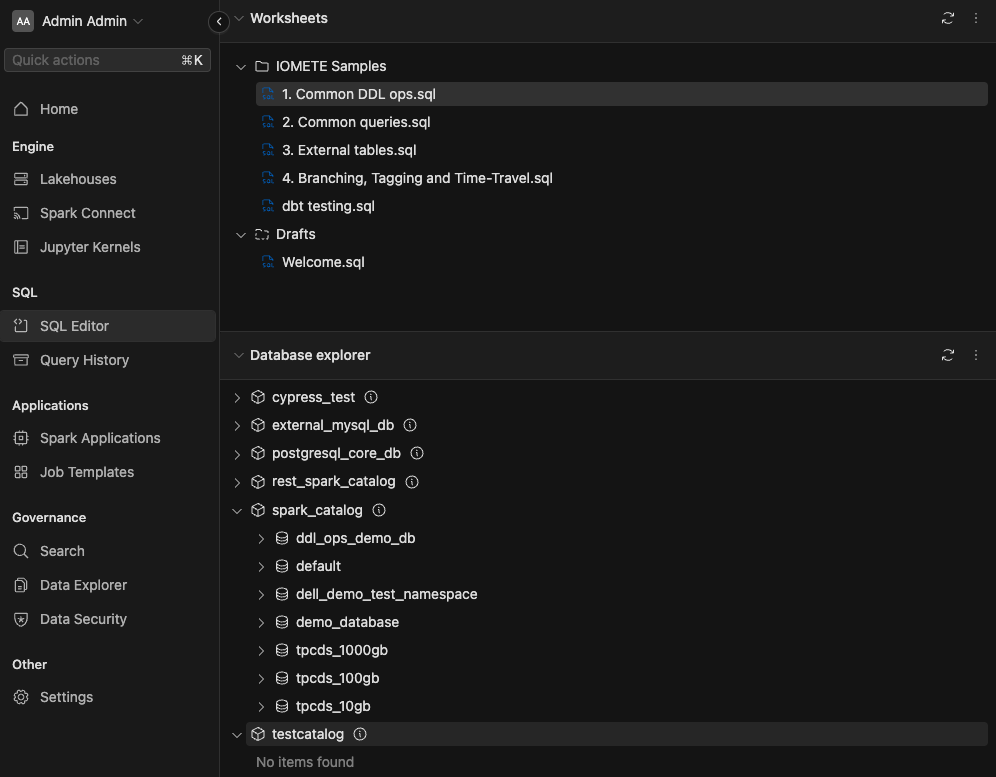
New Catalog in SQL Editor.
After c SQL Editor to view the Spark catalog that has been created.
Check out the SQL Editior section in the left panel. If you don't see the created catalog, please refresh by using the button.
In the given image, we have already created some databases and tables inside the catalog.
Connecting to the IOMETE REST Catalog from External Applications
IOMETE exposes the Iceberg REST URL at the subpath /catalogs/<catalog name> on the same domain as the IOMETE console.
For instance, you wish to query a catalog named my_catalog if your console is available on https://console.iomete.internal, then
you can utilize tools like cURL, Postman, or others to send requests to https://console.iomete.internal/catalogs/my_catalog/v1/config.
All REST endpoints are compliant with the Iceberg REST OpenAPI specification.
To connect to the REST Catalog via PySpark, the following configuration will enable the connection. Be sure to fill in the required fields. If you are using HTTPS with certificates, you will also need to provide a valid truststore and its associated password.
pyspark \
--conf spark.sql.catalog.spark_catalog.uri="<http|https>://<url running IOMETE console>/catalogs/my_catalog" \
--conf spark.sql.catalog.spark_catalog.token="<(personal) access token>" \
--conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.spark_catalog.warehouse="<path-to-your-s3-compatible warehouse>" \
--conf spark.sql.defaultCatalog=spark_catalog \
--conf spark.sql.catalog.spark_catalog.catalog-impl=org.apache.iceberg.rest.RESTCatalog \
--conf spark.sql.catalog.spark_catalog.s3.endpoint="<s3 compatible storage endpoint>" \
--conf spark.sql.catalog.spark_catalog.s3.client.region="<region for your s3 compatible storage, default it us-east1>" \
--conf spark.sql.catalog.spark_catalog.s3.access-key-id="<access key for your s3 compatible storage>" \
--conf spark.sql.catalog.spark_catalog.s3.secret-access-key="<secret key for your s3 compatible storage>" \
--conf spark.sql.catalog.spark_catalog.s3.path-style-access=true \
--conf "spark.driver.extraJavaOptions=-Djavax.net.ssl.trustStore=<path-to-truststore> -Djavax.net.ssl.trustStorePassword=<truststore password>" \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions \
--packages org.apache.iceberg:iceberg-spark-extensions-3.4_2.12:1.6.1,org.apache.iceberg:iceberg-spark-runtime-3.4_2.12:1.6.1,org.apache.iceberg:iceberg-aws-bundle:1.6.1,software.amazon.awssdk:s3:2.27.21
Please mind that you will require a valid session or PAT token pass authentication. Additionally, the user associated with the token must have the necessary Access Policies on the catalog, namespace, and table you wish to operate on.