Volumes
IOMETE provides flexibility to customize the Kubernetes Volume types used in Spark workloads. Volumes are a critical part of Spark infrastructure—they power shuffle operations, RDD/DataFrame caching, disk spill, and more.
Because Spark heavily relies on volumes for performance and stability, the speed and reliability of Spark applications or compute clusters are only as strong as the underlying volume configuration.
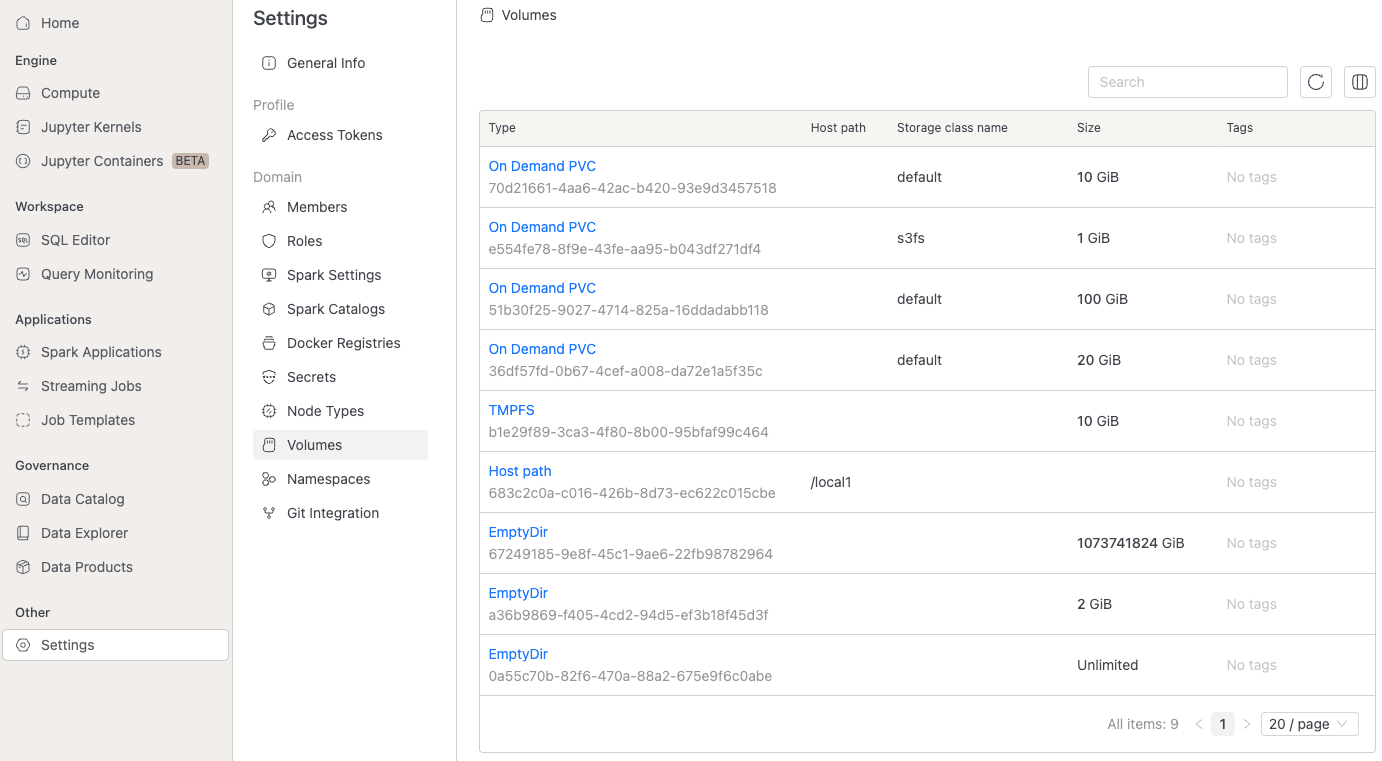
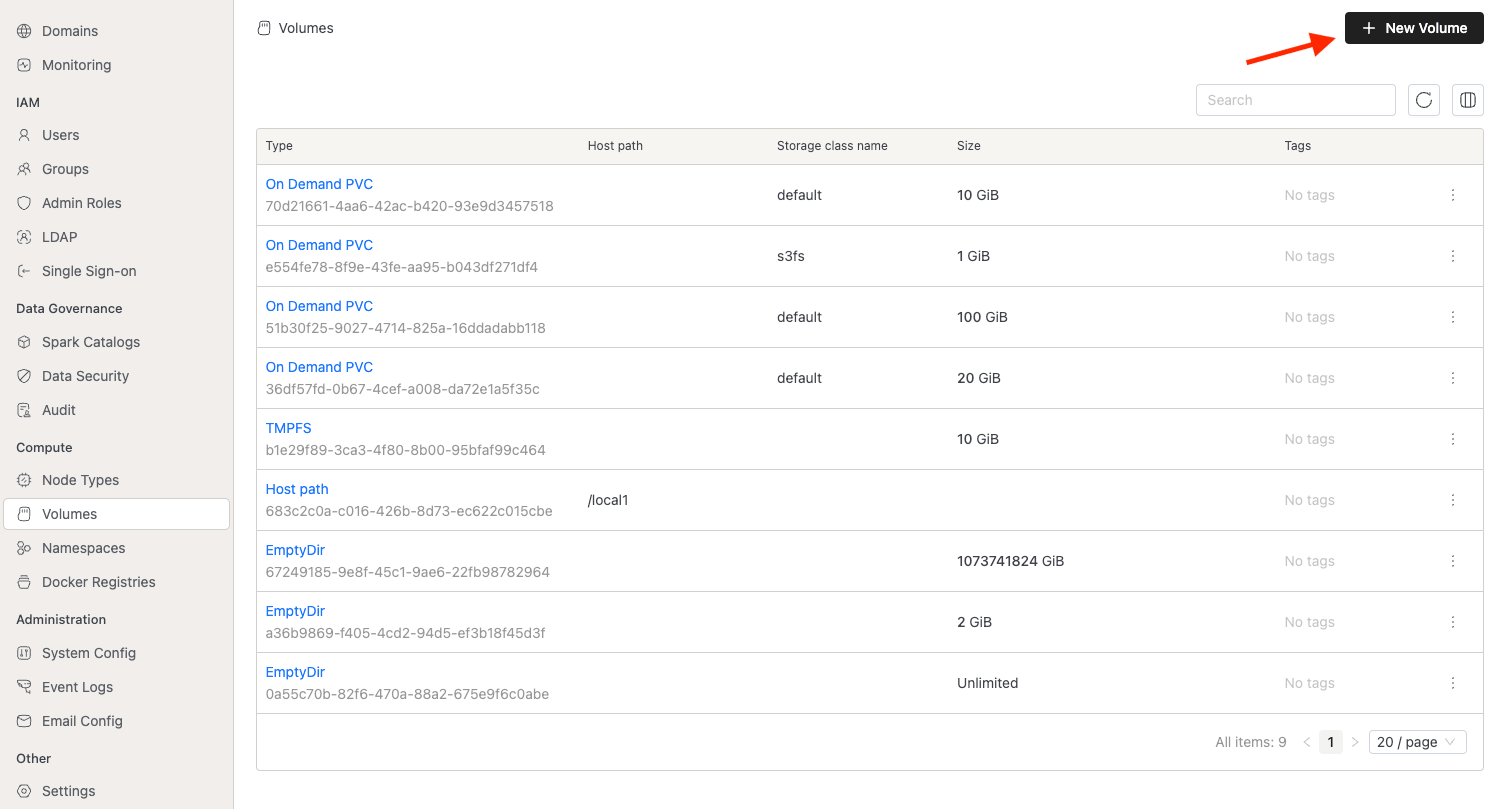
Volume list
To see the available volumes, go to the Settings menu and click on the Volumes tab.
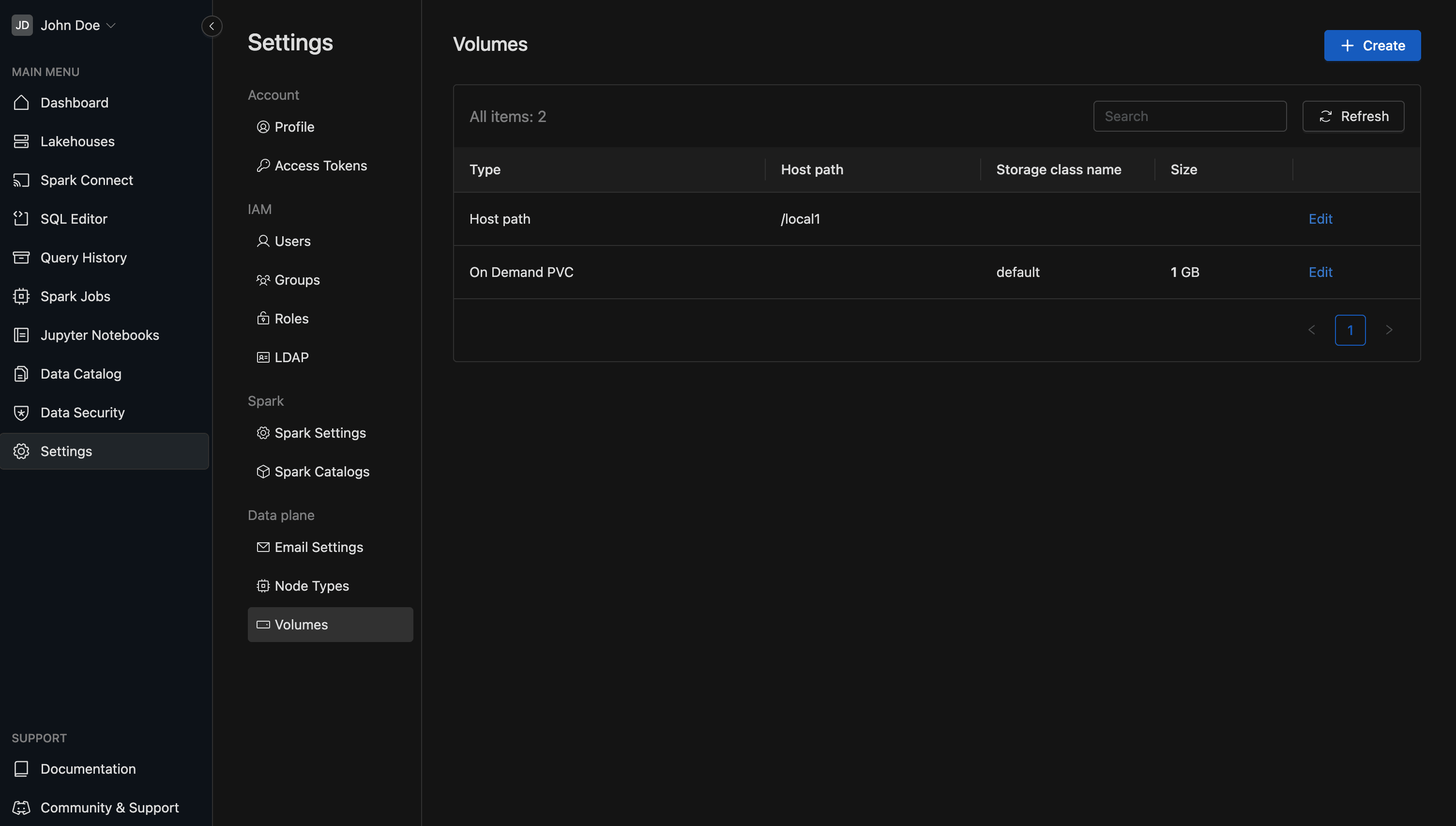
Create volume
Platform admins can create new type of volumes. To create a new volume go to admin console, click the button.
In the Create Volume screen, you can choose from four volume types:
- Host Path: Mounts a directory from the host (node) machine’s filesystem directly into the pod.
- On Demand PVC: Dynamically creates and mounts a persistent volume claim for each pod.
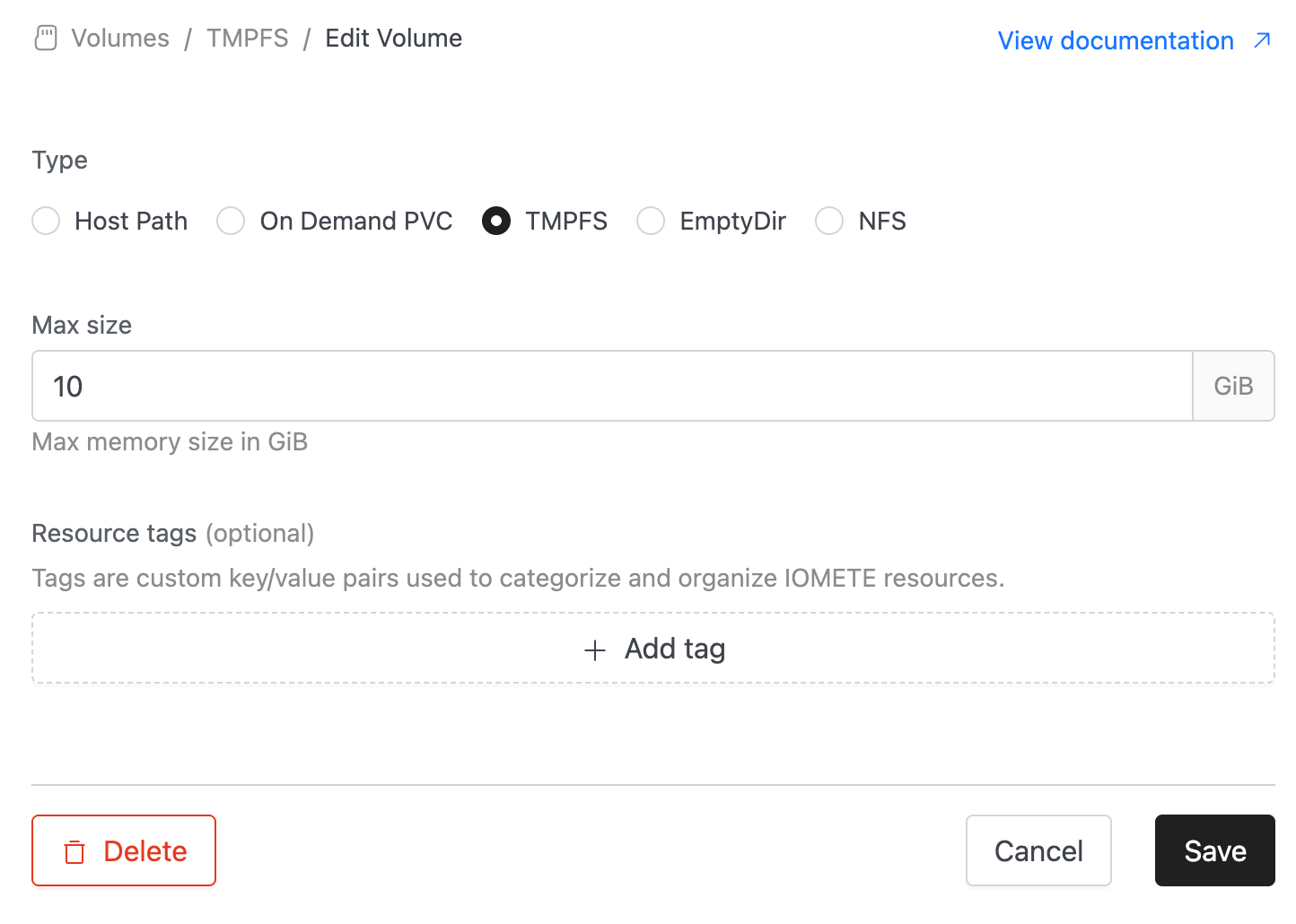
- TMPFS: Provides a temporary, memory-backed filesystem inside the container (fast but ephemeral).
- EmptyDir: Creates a temporary directory on the host (node) machine’s filesystem, which lasts only for the lifetime of the pod.
Host Path
A HostPath volume in Kubernetes is a special type of volume that mounts a file or directory from the host node’s filesystem directly into a pod.
However, HostPath comes with important limitations and risks:
- No storage limits: You cannot enforce quotas on how much space the pod consumes.
- No automatic cleanup: If the application (e.g., a compute cluster or Spark job) terminates without removing its data, those files remain on the node, which can eventually lead to node disk-full issues.
- Security concerns: Since HostPath exposes parts of the host’s filesystem, misconfiguration or misuse can compromise the node’s integrity.
Because of these drawbacks, for most workloads, it is recommended to use safer alternatives such as EmptyDir, PersistentVolumeClaims (PVCs), or tmpfs.
Configuration:
- Provide directory on host(node) to be mounted to the pods.
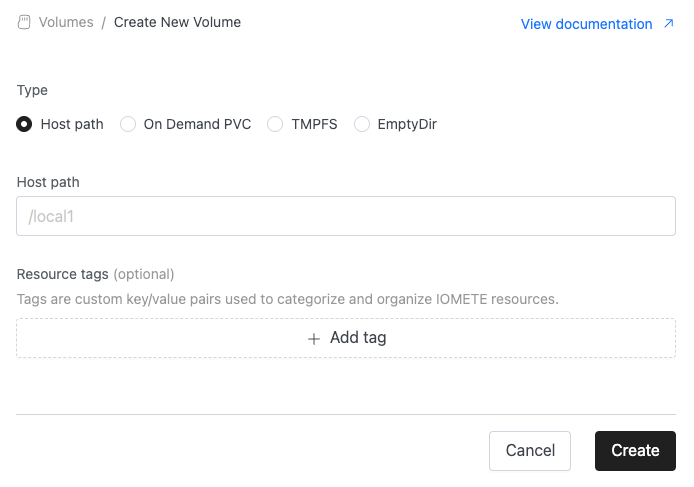
- Resource tags are custom name/value pairs that you can assign to IOMETE resources. These tags enable you to categorize and organize your resources effectively.
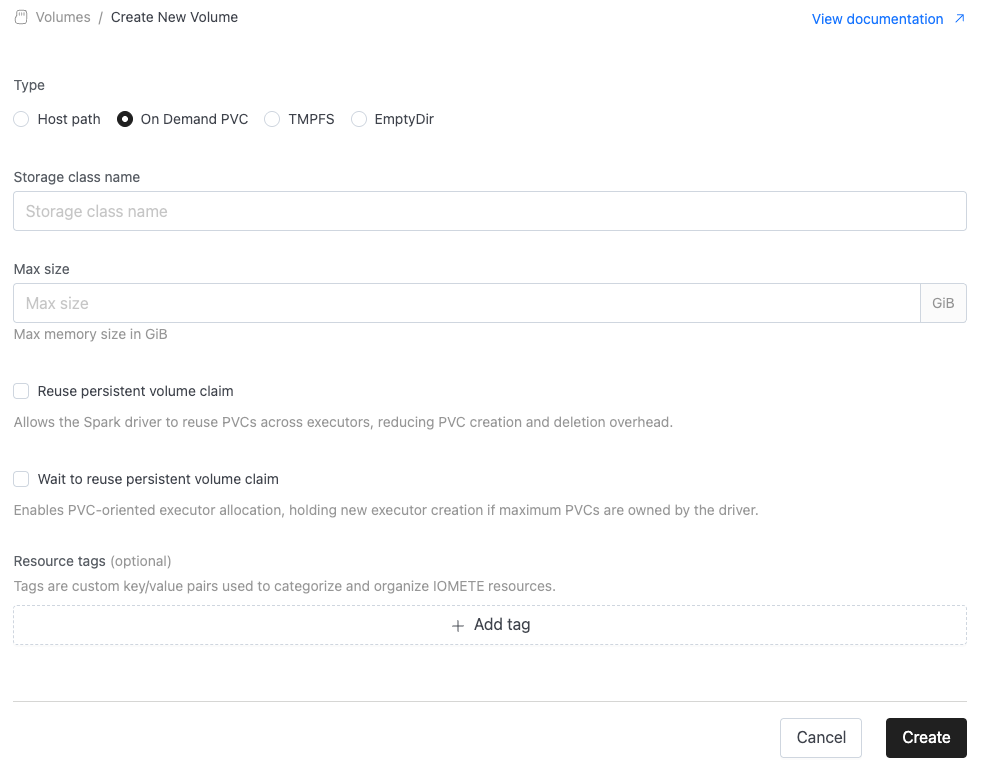
On Demand PVC
An On-Demand PersistentVolumeClaim (PVC) in Kubernetes is a way for pods to request persistent storage that is automatically provisioned by a StorageClass. Instead of pre-creating volumes, the cluster dynamically allocates the required storage from the underlying infrastructure (e.g., local disks, cloud block storage, or CSI drivers) when the PVC is created.
On Demand PVC offers several advantages:
- Automatic provisioning: Volumes are created and bound to PVCs on demand, removing the need for manual PersistentVolume(PV) management.
- Storage guarantees: You can define the requested size and access mode, ensuring predictable resource allocation.
- Lifecycle management: Depending on the reclaimPolicy of the StorageClass, volumes can be automatically deleted or retained when the PVC is removed.
- Isolation & safety: Unlike HostPath, each PVC-backed volume is isolated, and quotas can prevent uncontrolled disk usage.
Configuration:
-
Storage class name: Name for storage class. Available list of storage classes can be retrieved with
kubectl get storageclasscommand. -
Max size: Maximum storage capacity requested in a PVC per executor.
TMPFS
TMPFS volumes stores data in the node’s RAM instead of on disk. This means the volume is created when a pod starts and exists only while the pod is running. All data is lost when the pod is removed.
Key characteristics:
- Memory-backed: Data is stored in RAM (tmpfs), offering very fast read/write performance compared to disk.
- Ephemeral: The volume and its contents are automatically deleted when the pod stops or restarts.
- Space limits: By default, usage is limited by the pod’s memory requests/limits, preventing it from consuming all node memory.
- Use cases: Ideal for temporary, high-speed scratch space such as caches, buffers, or intermediate computation results.
For workloads that need fast but ephemeral storage, tmpfs-backed emptyDir provides a safe and efficient option without touching the host’s filesystem or requiring persistent storage.
⚠️ Warning: Since TMPFS uses the container's memory, enabling it for Spark's local storage will increase the memory usage of your Spark pods. To accommodate this, you may need to adjust the memory overhead allocated to Spark's driver and executor pods by configuring
spark.{driver,executor}.memoryOverheadFactor. This ensures that your Spark workloads have enough memory to handle both their regular tasks and the additional overhead introduced by using TMPFS.
Configuration:
- Max size: The maximum storage limit for the volume, specified in units such as
GiB.
This value acts as an upper bound, not a reservation — the actual available storage depends on the node’s memory capacity.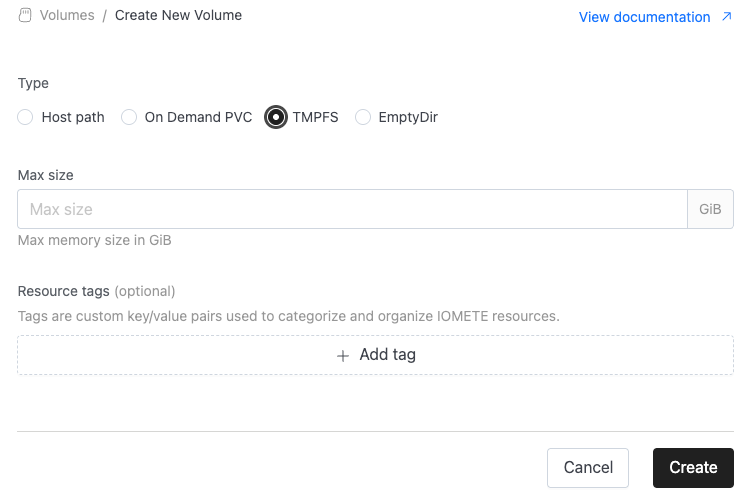
EmptyDir
EmptyDir is a temporary storage space that Kubernetes creates when a pod is assigned to a node. The volume initially starts empty and is deleted automatically when the pod is removed. By default, data is stored on the node’s backing storage (e.g., local SSD, HDD, or node filesystem).
Key characteristics:
- Ephemeral: The data lives only for the lifetime of the pod. Once the pod is deleted or rescheduled, all contents are lost.
- Disk-backed: Data is written to the node’s disk, making it slower than TMPFS but suitable for larger temporary data.
- Storage capacity: The size is limited by the available disk space on the node. Per-pod usage limit can be defined.
- Use cases: Good for temporary files, caching, scratch space, or intermediate results that do not need to survive beyond the pod’s lifecycle.
⚠️ Warning: Since
EmptyDirvolumes use the node’s local storage, excessive consumption can fill the node’s disk and cause other workloads to fail. Always monitor ephemeral storage usage or configure pod-level ephemeral storage limits.
Configuration:
-
Max size: The maximum storage limit for the volume, specified in units such as
GiB.
This value acts as an upper bound, not a reservation — the actual available storage depends on the node’s capacity.
If omitted, the volume can grow without a defined limit (constrained only by the node’s available storage). -
Scheduler reserved: Turns Max size from a soft limit into an actual reservation.
By default, Max size is only enforced after the fact: the kubelet evicts a pod that exceeds it, but the Kubernetes scheduler does not consider it when placing pods, so executors can land on a node that doesn’t have that much free disk. With Scheduler reserved enabled, IOMETE also sets anephemeral-storageresource request of Max size on each Spark executor pod — the scheduler then only places executors on nodes with enough allocatable local storage and reserves that capacity for the pod at placement time.
A positive Max size is required when this option is enabled. The option is off by default, and existing volumes keep the soft-limit-only behavior.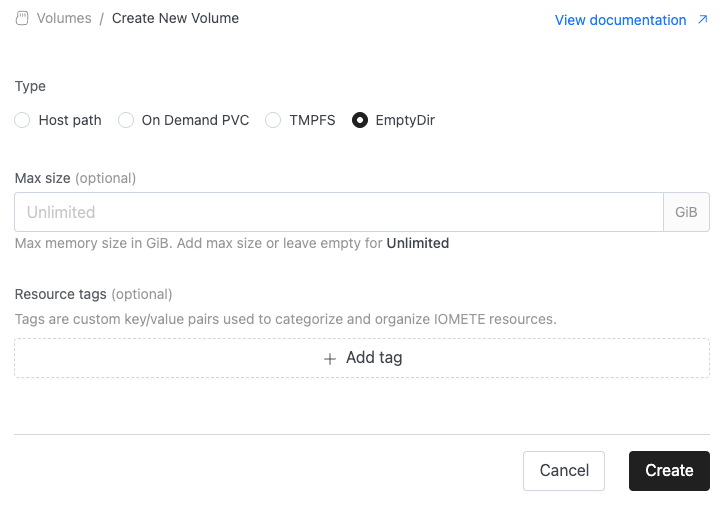
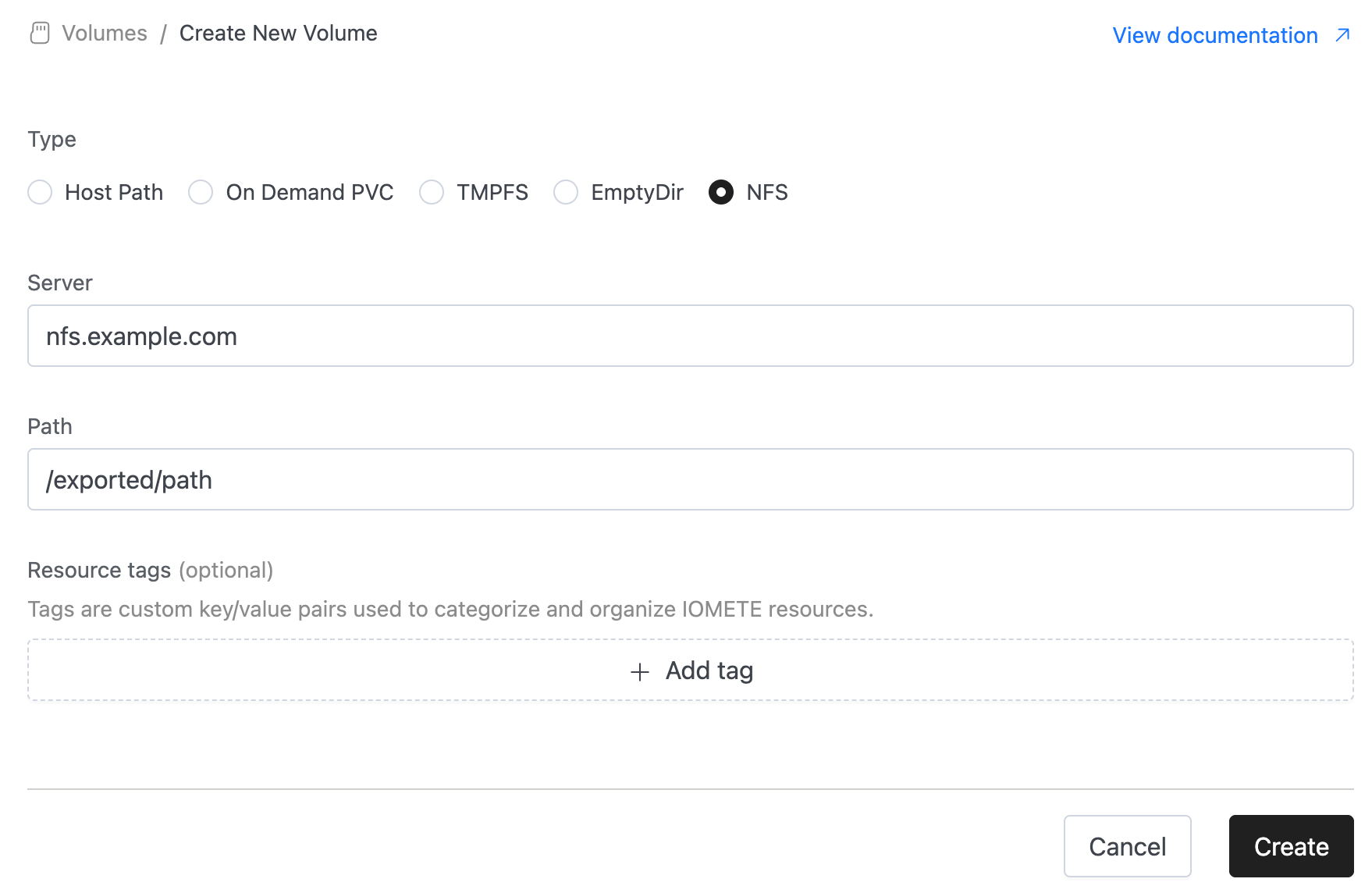
NFS
An NFS (Network File System) volume allows pods to mount shared storage hosted on an NFS server. Multiple pods across different nodes can access the same data simultaneously, making it ideal for shared workloads.
Key characteristics:
- Shared access: Multiple pods can read/write to the same volume concurrently.
- Persistent: Data remains available even when pods are deleted or rescheduled.
- Network-based: Accessible from any node with network connectivity to the NFS server.
- No local disk usage: Doesn't consume node storage, preventing disk-full issues.
Considerations:
- Performance depends on network connectivity and NFS server reliability.
- Requires proper NFS server setup and network permissions.
Configuration:
- Server: The hostname or IP address of your NFS server (e.g.,
nfs.example.com). - Path: The exported directory path on the NFS server to be mounted to pods (e.g.,
/exported/path).
Ensure your NFS server is properly configured with correct export permissions and that Kubernetes nodes can reach the NFS server over the network.
Volume Types Comparison
| Volume Type | Storage | Automatic Cleanup | Perf. | Pod Usage Limit | Risks |
|---|---|---|---|---|---|
| HostPath | Node FS | ❌ | Fast | ❌ | Security, disk leaks |
| EmptyDir | Node FS | ✅ | Fast | ✅ | Node storage full |
| TMPFS | RAM | ✅ | Fastest | ✅ | Pod OOM |
| StorageClass | ✅ | Varies (usually slower than others) | ✅ | Slow/stuck provisioning under high load | |
| NFS | Network | ❌ | Network-dependent | ❌ | Network failures, NFS server downtime |
Using volumes
You can utilize node types in Compute Clusters and Spark Jobs.
Let's navigate to the Cluster create page. Here, you'll find options for Volume which include volume selections.


Delete volume
To delete a volume, locate it in the volumes list, click the "Edit" button, and then click the button below the inputs. Afterward, you'll receive a confirmation message; click "Yes, delete" to confirm the deletion.