Secrets Management
Store passwords, API keys, and credentials securely, then reference them in workloads without exposing sensitive values.
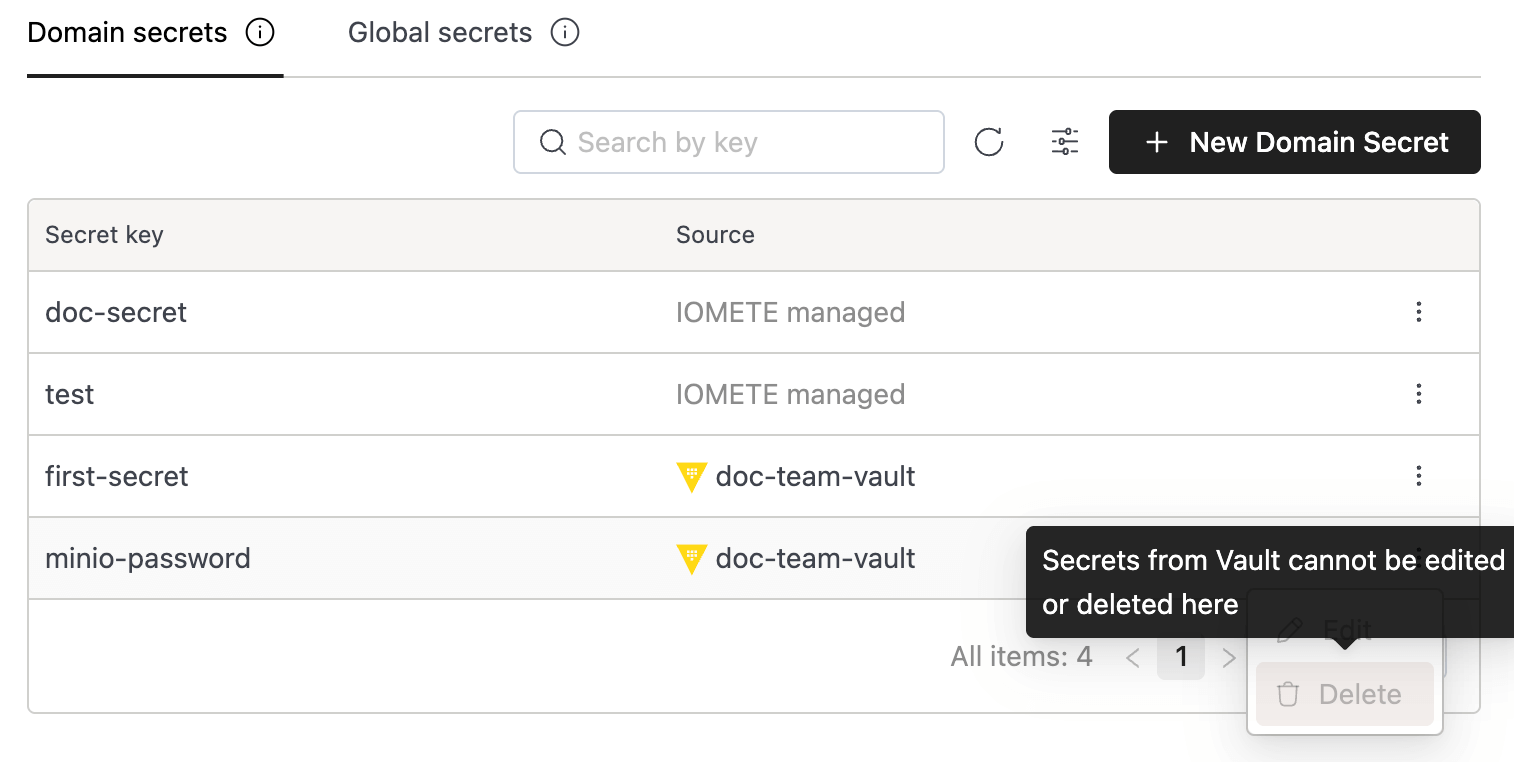
Domain Secrets
Domain Secrets are scoped to a specific domain—only authorized users and workloads within that domain can access them.
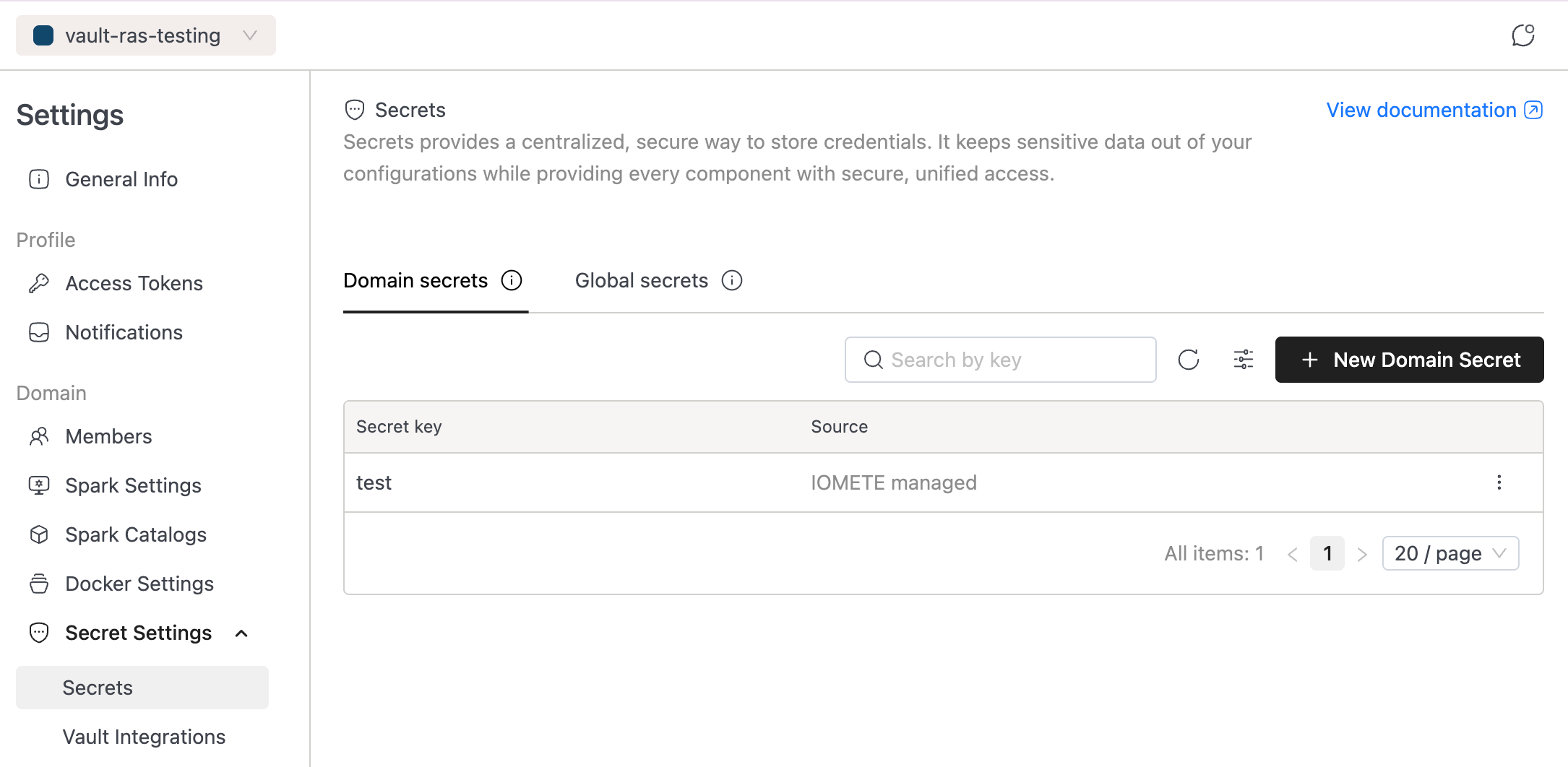
Creating a Domain Secret
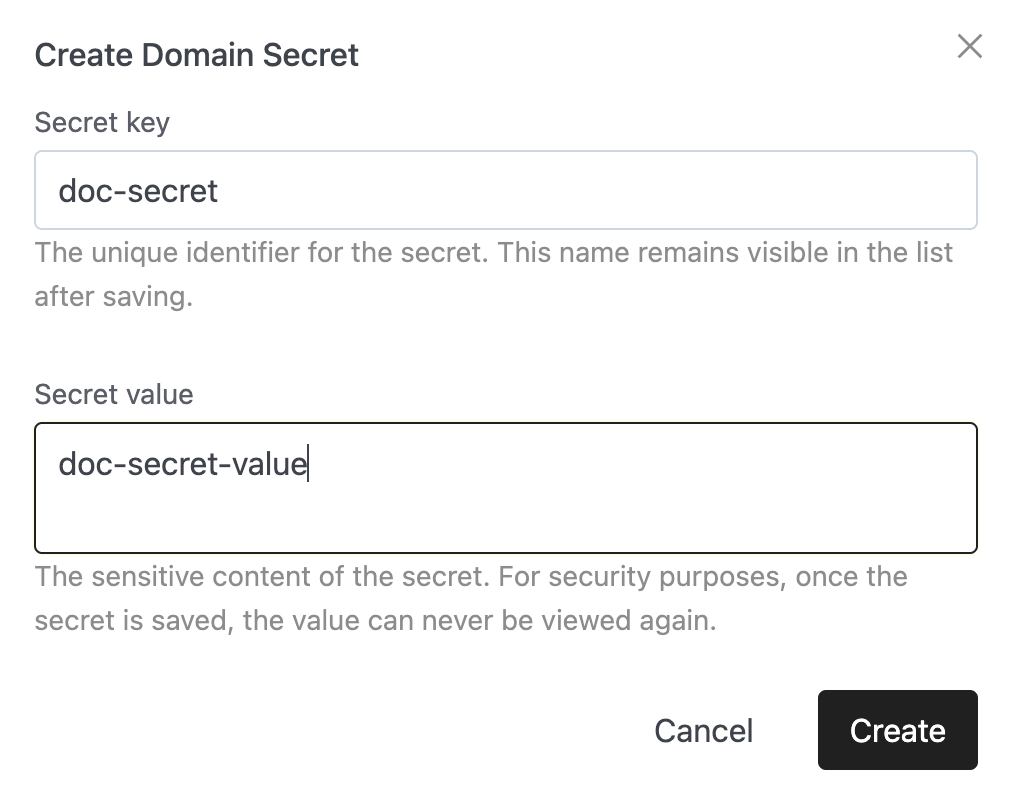
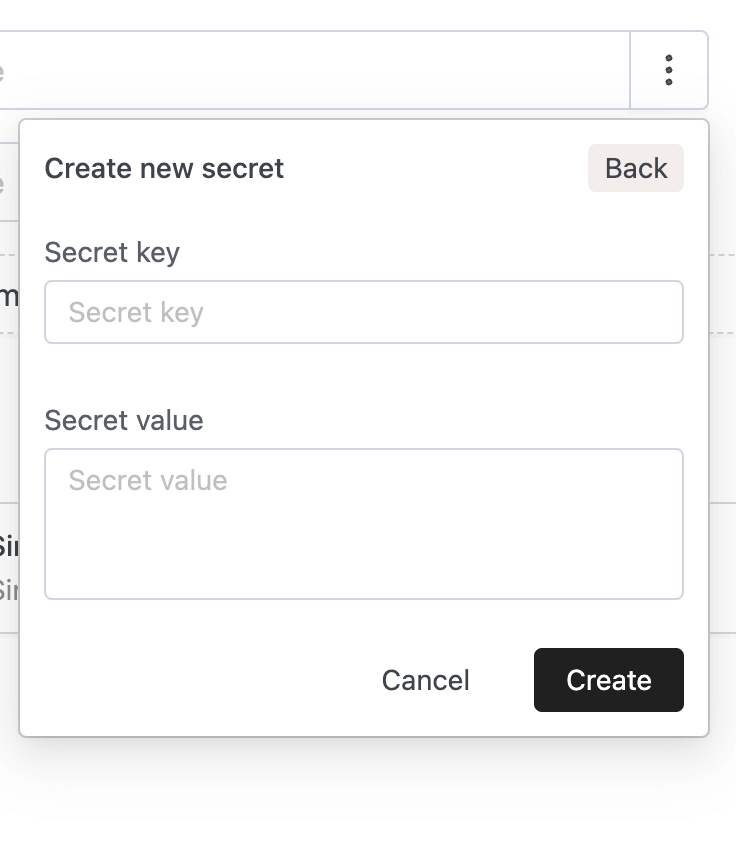
Click the New Domain Secret button. The form requires the following fields:
- Secret key: The name used to reference the secret within this domain.
- Secret value: The sensitive content of the secret. For security purposes, once the secret is saved, the value can never be viewed again.
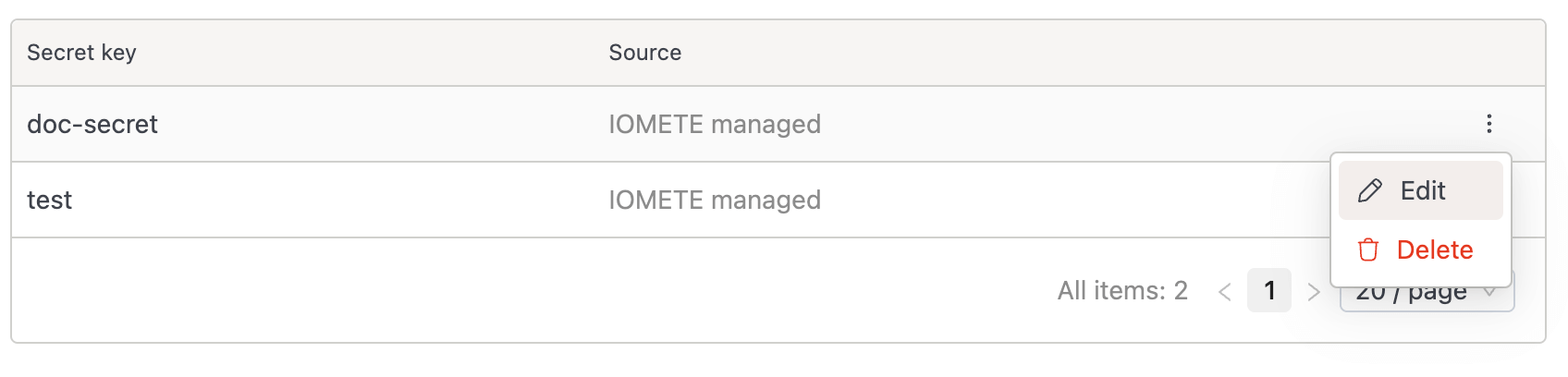
After clicking Create, the secret will appear in the list with the following details:
- Secret key
- Source:
IOMETE managed(Kubernetes) orVault - Actions: Use the button on the right to Edit or Delete.
Before deleting a secret, ensure it is no longer in use. Deleting an active secret may cause jobs or actions to fail.
Vault Integrations (HashiCorp Vault)
Vault integrations let you reuse secrets you already manage in HashiCorp Vault, so workloads can reference them without copying values into IOMETE. This integration is read-only. Manage Vault data with your existing HashiCorp tools.
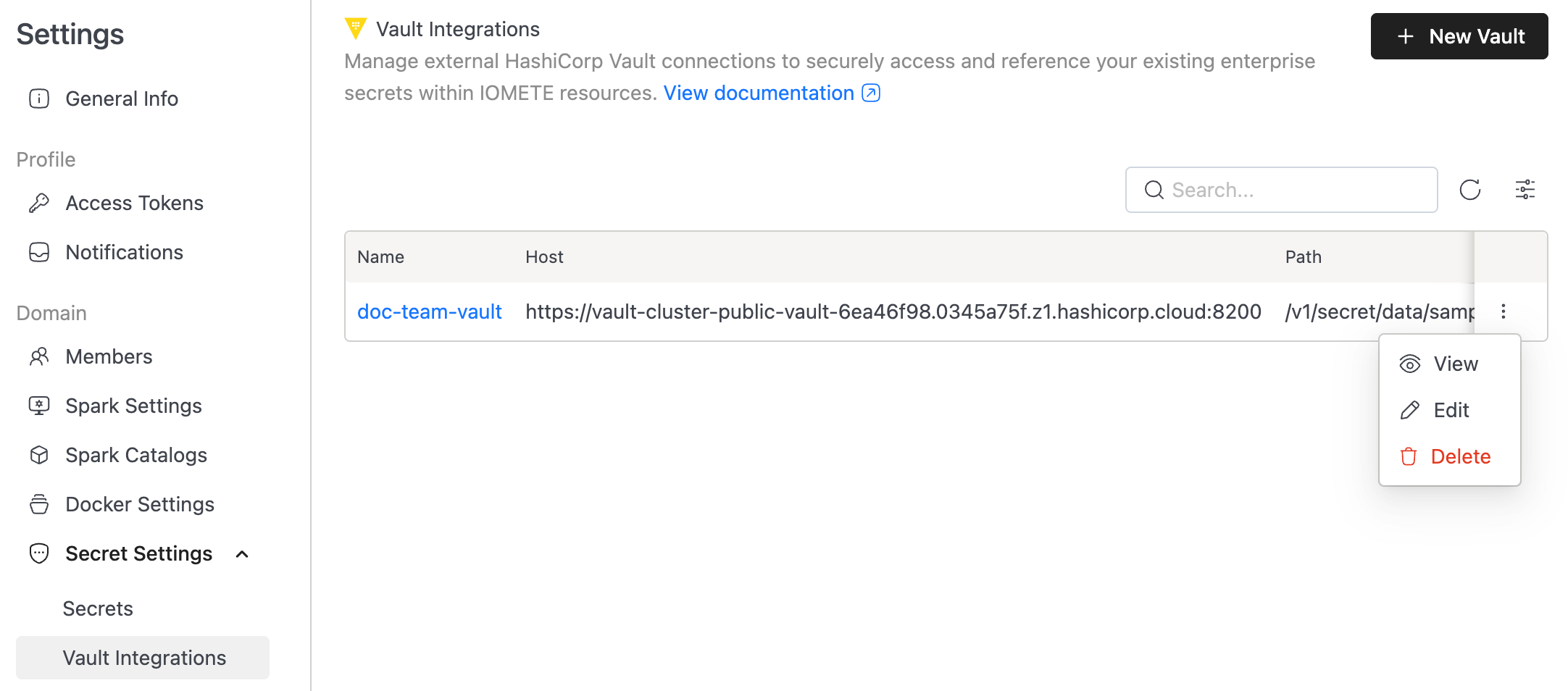
Navigate to Settings → Secret Settings → Vault Integrations.
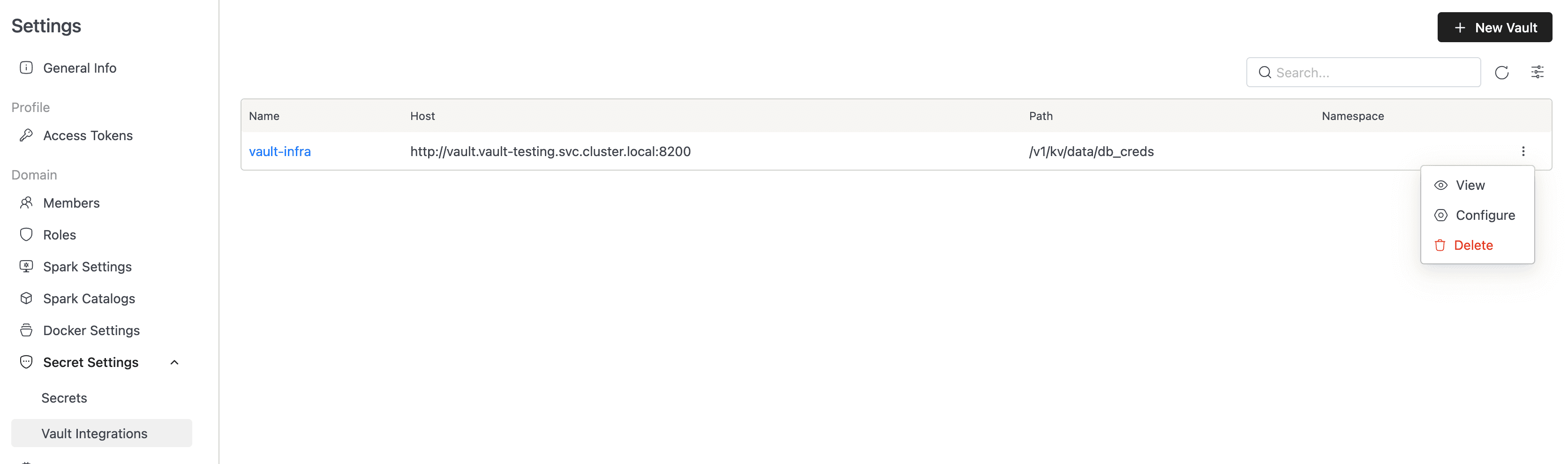
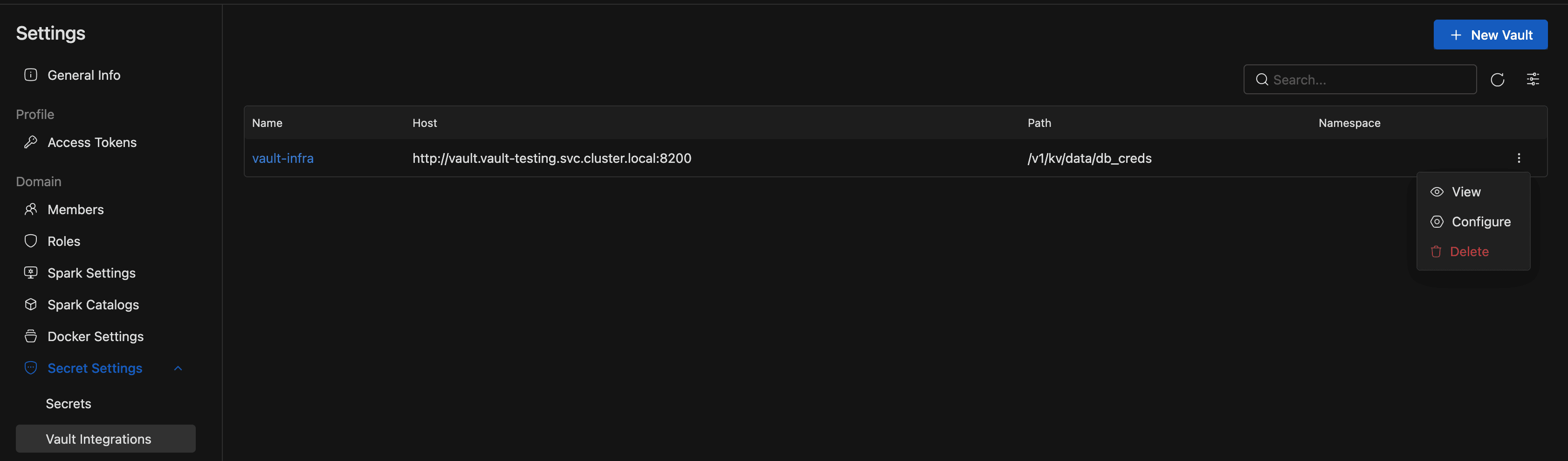
Viewing Vault Configurations
The Vault Integrations list shows the Vault connections you can access in the current domain. Each row includes:
- Name: The Vault configuration name. Click it to open the details page.
- Host: The Vault base URL.
- Path: The KV v2 API path IOMETE reads from.
- Namespace: The HashiCorp namespace, when one is configured.
- Actions: Open the action menu to View, Configure, or Delete the integration.
The details page shows the configuration ID, Name, Host, HashiCorp namespace, Bundle, Path, and Auth method.
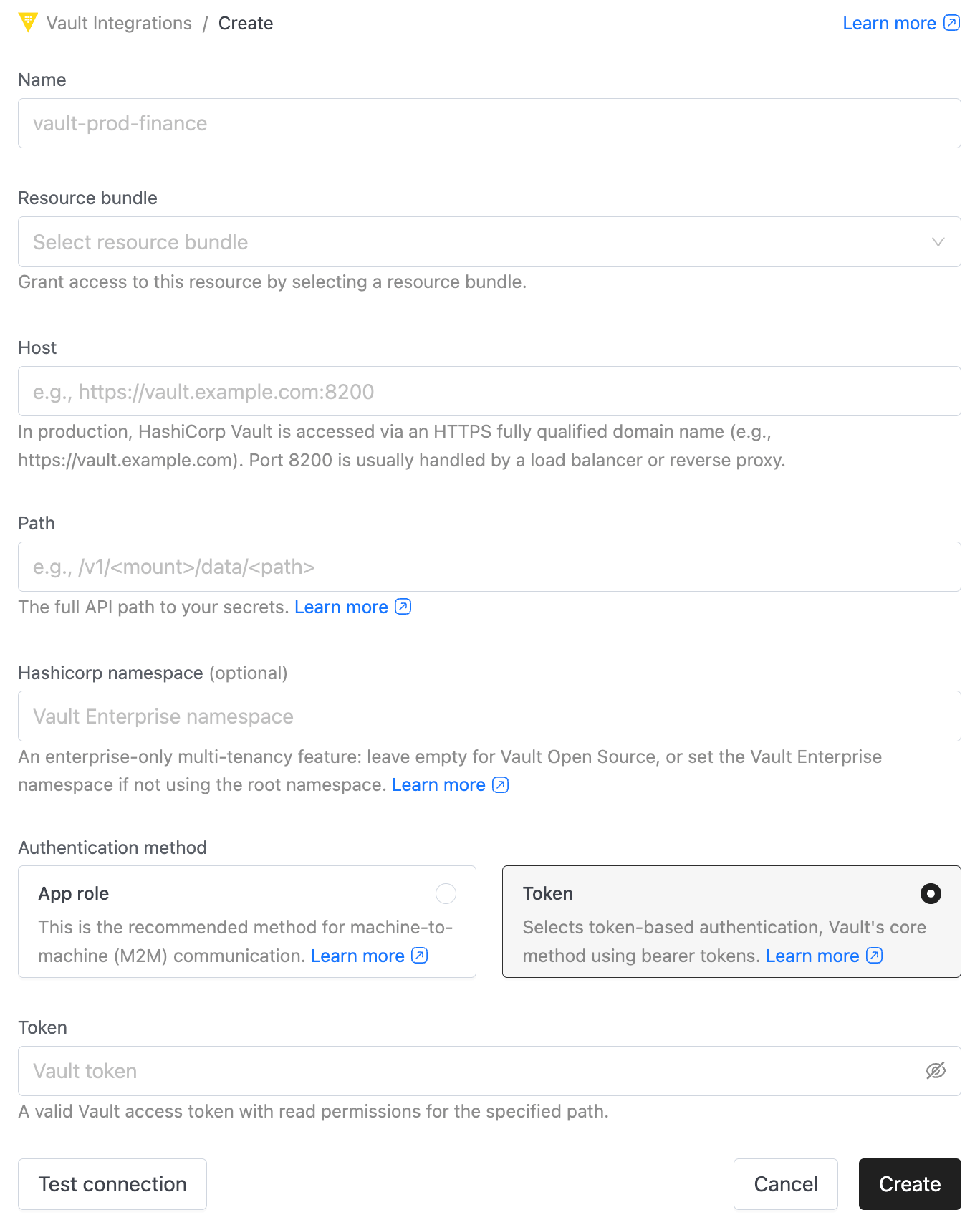
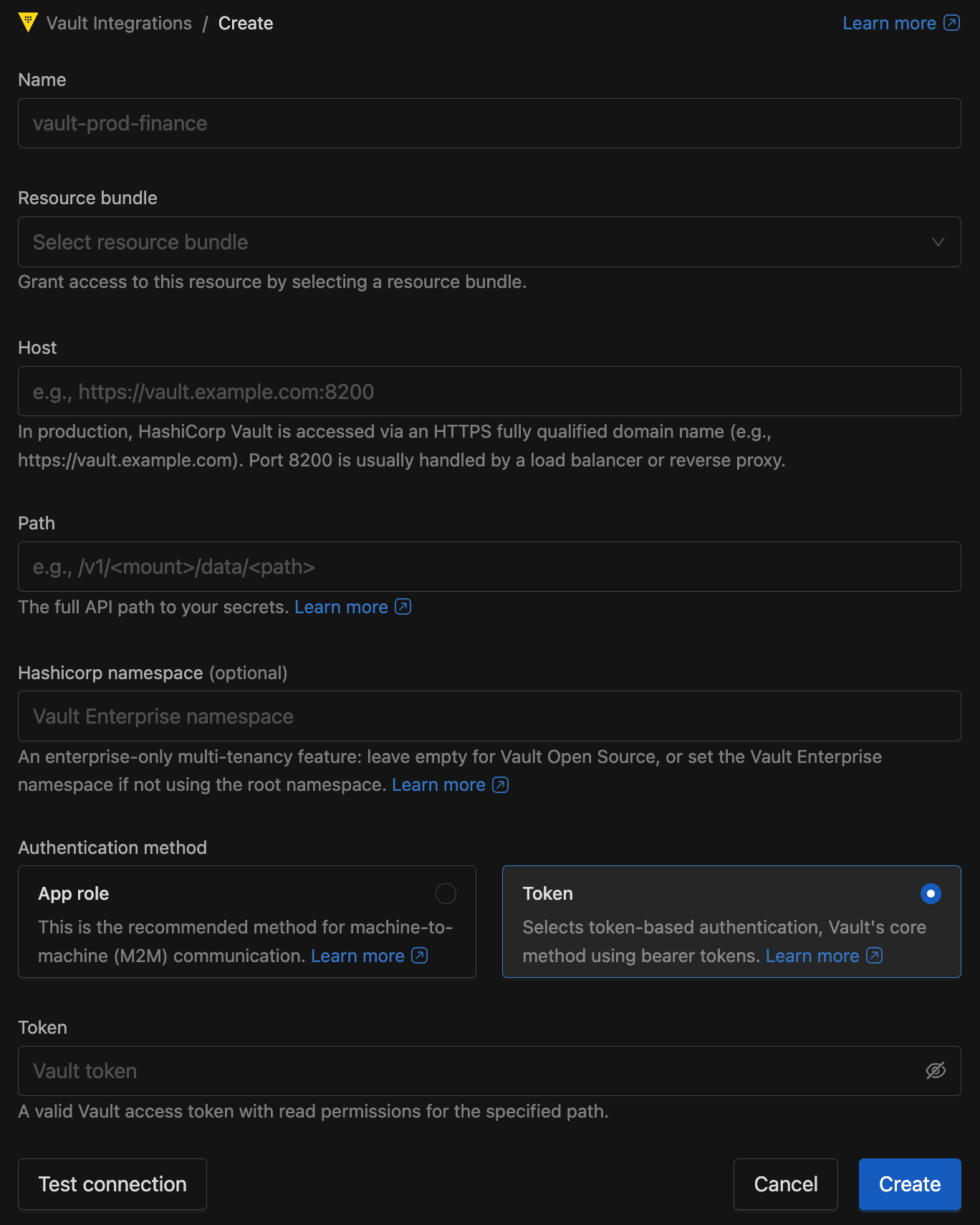
Creating a Vault Configuration
Click + New Vault to create a Vault configuration.
- Name: A unique identifier (for example,
vault-prod-finance). Use letters or numbers, and optionally_,-, or.. - Resource bundle: Select a resource bundle to define access control for this integration.
- Host: The Vault base URL (e.g.,
https://vault.example.com:8200). - Path: The KV v2 mount point (e.g.,
/v1/secret/data/production). Note: KV v2 paths typically require the/data/segment. - HashiCorp namespace (Optional): Required for Vault Enterprise users specifying non-root namespaces.
- Authentication method: Choose App role (recommended) or Token.
- Token: Provide a Vault token with read access to the configured path.
- App role: Provide both the Role ID and Secret ID.
Click Test connection to validate the settings, then click Create to save the integration.
Once saved, secret selectors throughout IOMETE will aggregate keys from both Kubernetes and Vault.
Testing a Vault Connection
Use Test connection on the create or update form whenever you want to validate the host, path, namespace, and credentials before saving.
- The check is optional but recommended. It does not save the configuration.
- If the test succeeds, the form shows a green success indicator next to Test connection.
- If the test fails, the form shows a red error indicator. Hover over it to see the returned error message.
Common failures include invalid credentials, missing access to the configured Vault path, or a path that does not match a KV v2 endpoint.
Updating a Vault Configuration
Open the action menu for a Vault integration, then select Configure. You can also open the details page and click Configure there.
You can update the Name, Host, Path, HashiCorp namespace, Authentication method, and credentials. The Resource bundle stays fixed after creation, so if you need different access control you must create a new integration with the correct bundle.
If you change the credentials or path, run Test connection again before you click Update.
Deleting a Vault Configuration
Open the action menu for a Vault integration and select Delete, or delete it from the details page.
Deleting a Vault configuration removes the integration from IOMETE, but it does not delete any secrets from HashiCorp Vault. Make sure no workloads still reference secrets from that Vault configuration before you confirm the deletion.
- Vault Version: Requires HashiCorp Vault KV Secrets Engine v2. Version 1 is not supported.
- Vault secrets are read-only in IOMETE—edit them via your Vault tools.
Vault Access Control
Vault access is controlled via RAS (Resource Authorization System):
| Permission | Capability |
|---|---|
| View | View Vault configuration details |
| Update | Modify or delete Vault configurations |
| Use | List and select Vault-backed secret keys in workloads |
Only domain owners or platform admins can create Vault configurations. After a configuration is created, the assigned resource bundle controls who can View or Update that Vault configuration.
Users need Use permission only when they reference secrets from a Vault configuration in workloads. Without Use permission, keys from that Vault won't appear in secret selector dropdowns.
To list secrets in the secret selector, Use permission on the Vault configuration is required alongside List Secrets domain permission. The List Secrets permission is needed because the selector also lists Kubernetes secrets, which are governed by that permission.
Global Secrets
Global Secrets are read-only credentials available across all domains for platform-wide use. You manage them directly in Kubernetes today. Console editing is planned for a future update.
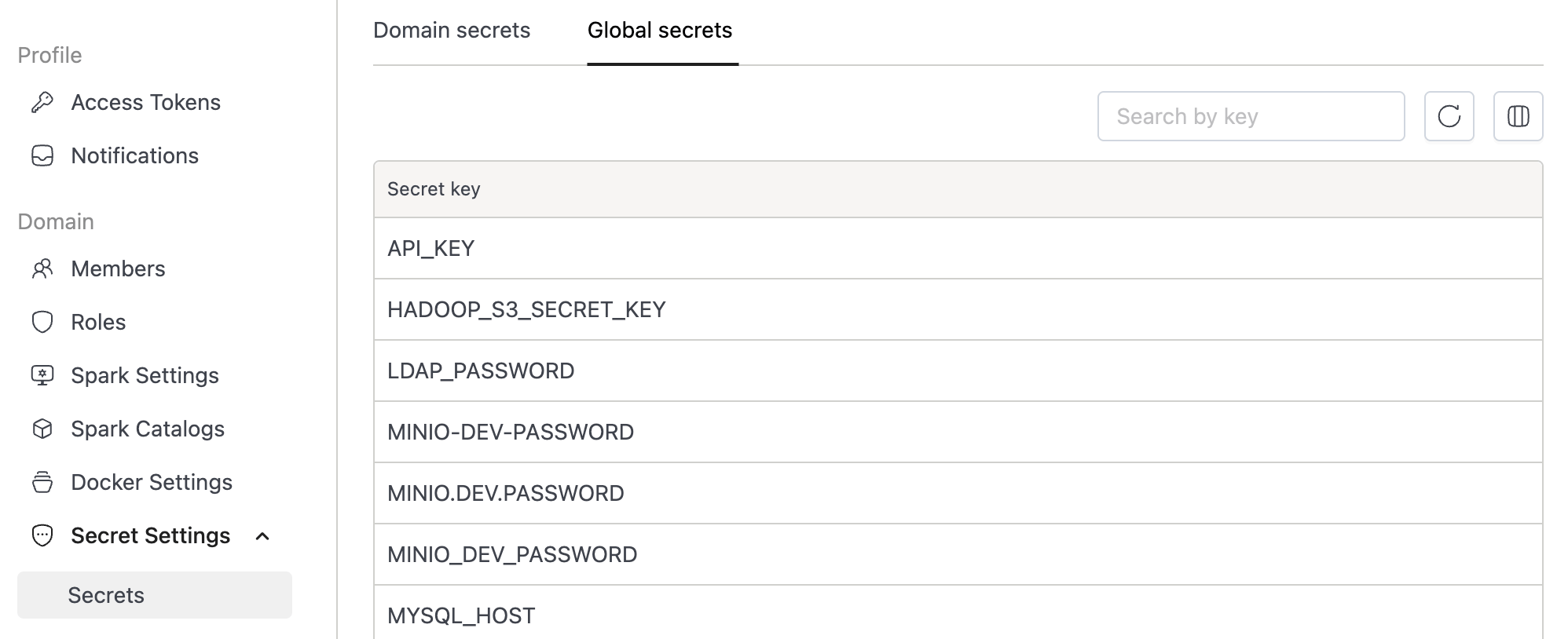
Existing legacy secrets are automatically mapped to the Global scope.
Usage in Workloads
Secrets can be used in:
- Spark & Compute: Environment variables and Spark configuration
- Jupyter Notebooks: Environment variables
- Storage Configs: S3, MinIO, and other cloud credentials
How to Reference a Secret
When configuring environment variables or credentials:
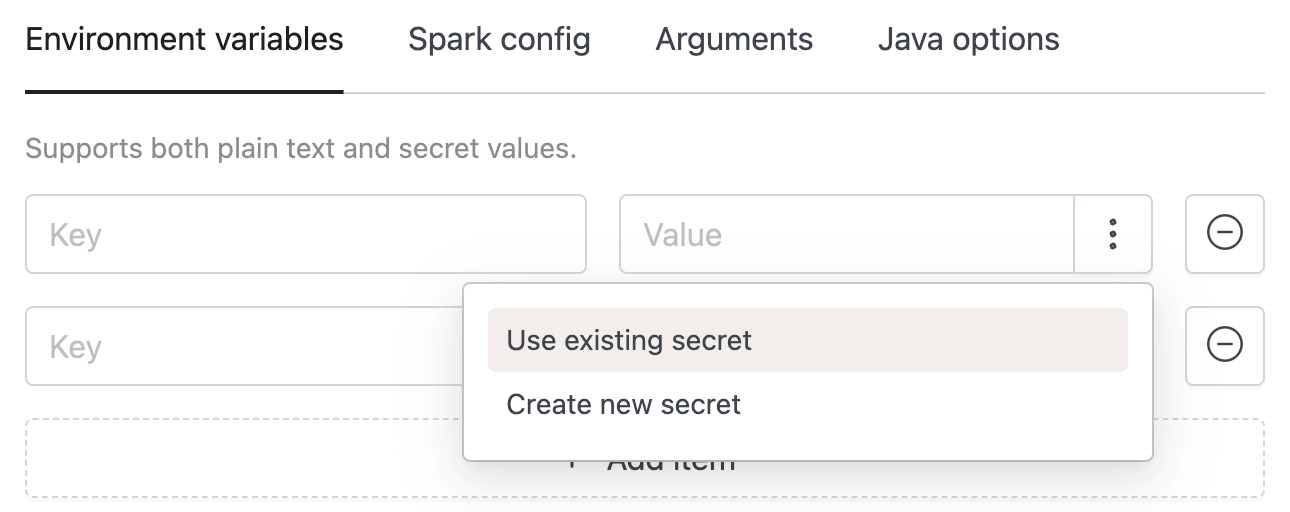
- Click the More options button (
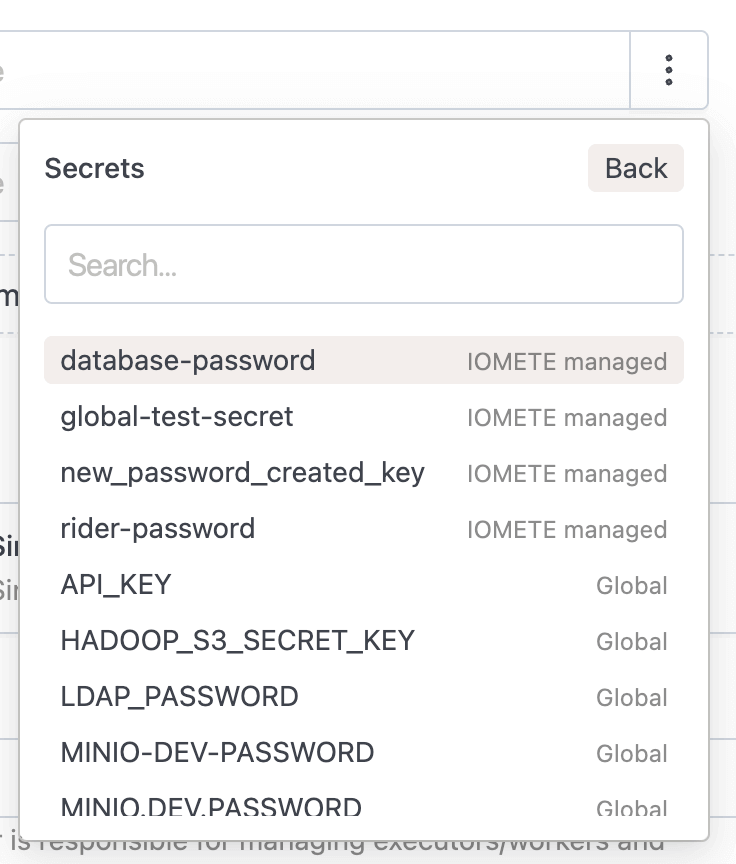
:) on the right side of the input field. - Choose "Use existing secret" to select from stored secrets.
- Or select "Create new secret" to define a secret inline; it will be saved to your current domain automatically.
Once selected, the UI displays the secret key and its source (KUBERNETES or VAULT). Values are resolved securely at runtime.
While the selector is the recommended approach, legacy ${secrets.key} placeholders remain supported for backward compatibility.
Secret Backends
IOMETE supports two backends that can be used simultaneously:
- Kubernetes (default): Secrets stored in opaque Secret objects (
iomete-secret-store-{domain}for domain,iomete-secret-storefor global) within the same namespace as the data-plane installation - HashiCorp Vault: Customer-managed, read-only integration
Feature Flag
Enable secrets management in your Helm values:
features:
secretsV2:
enabled: true
API Migration Guide
Secrets V2 replaces inline ${secrets.key} placeholders with structured secret references in API payloads. Existing placeholders continue to work as migration is incremental, so you can update workloads one at a time.
Secret Object
All secret references in API payloads use a secretObject to identify the secret and its backend:
{
"key": "secret_key_in_store",
"source": {
"type": "KUBERNETES | VAULT",
"id": "<domain-name or vault-config-id>"
}
}
| Field | Description |
|---|---|
key | Secret key name in the store |
source.type | KUBERNETES (IOMETE-managed) or VAULT (HashiCorp Vault) |
source.id | Domain name for Kubernetes, or Vault config ID for Vault |
Compute
Endpoint: POST/PUT /api/v2/domains/{domain}/compute
- V1 — Inline Placeholders
- V2 — SecretObject
{
"envVars": {
"DB_PASSWORD": "${secrets.db_password}"
},
"sparkConf": {
"spark.hadoop.fs.s3a.secret.key": "${secrets.warehouse_path}"
}
}
{
"envVars": {
"APP_MODE": "production"
},
"envSecrets": [
{
"key": "DB_PASSWORD",
"secretObject": {
"key": "db_password",
"source": { "type": "KUBERNETES", "id": "secret-domain" }
}
}
],
"sparkConf": {
"spark.executor.memory": "4g"
},
"sparkConfSecrets": [
{
"key": "API_TOKEN",
"secretObject": {
"key": "api_token",
"source": { "type": "VAULT", "id": "vault-config-id" }
}
}
]
}
Spark Jobs
Endpoints:
-
POST/PUT /api/v2/domains/{domain}/spark/jobs -
POST/PUT /api/v2/domains/{domain}/spark/streaming/jobs -
POST/PUT /api/v2/domains/{domain}/sdk/spark/jobs -
All three job types use the same structure under
template.
- V1 — Inline Placeholders
- V2 — SecretObject
{
"template": {
"envVars": {
"API_KEY": "${secrets.api_key}"
},
"sparkConf": {
"spark.hadoop.fs.s3a.access.key": "${secrets.s3_access_key}"
}
}
}
{
"template": {
"envVars": {
"APP_MODE": "production"
},
"envSecrets": [
{
"key": "API_TOKEN",
"secretObject": {
"key": "api_token",
"source": { "type": "VAULT", "id": "vault-config-id" }
}
}
],
"sparkConf": {
"spark.executor.memory": "4g"
},
"sparkConfSecrets": [
{
"key": "spark.hadoop.fs.s3a.access.key",
"secretObject": {
"key": "s3_access_key",
"source": { "type": "KUBERNETES", "id": "secret-domain" }
}
}
]
}
}
Jupyter Containers
Endpoint: POST/PUT /api/v1/domains/{domain}/jupyter-containers
- V1 — Inline Placeholders
- V2 — SecretObject
{
"config": {
"envVars": {
"DB_PASSWORD": "${secrets.db_password}"
}
}
}
{
"config": {
"envVars": {
"APP_MODE": "production"
},
"envSecrets": [
{
"key": "DB_PASSWORD",
"secretObject": {
"key": "db_password",
"source": { "type": "KUBERNETES", "id": "secret-domain" }
}
},
{
"key": "API_TOKEN",
"secretObject": {
"key": "api_token",
"source": { "type": "VAULT", "id": "vault-config-id" }
}
}
]
}
}
Storage Configs
Endpoint: POST/PUT /api/v1/domains/{domain}/storage-configs
- V1 — Inline Placeholders
- V2 — SecretObject
{
"secretKey": "my-plaintext-secret-value"
}
// Using Kubernetes:
{
"storageSecret": {
"key": "s3_secret_key",
"source": { "type": "KUBERNETES", "id": "secret-domain" }
}
}
// Using Vault:
{
"storageSecret": {
"key": "s3_secret_key",
"source": { "type": "VAULT", "id": "vault-config-id" }
}
}
When both secretKey and storageSecret are provided, storageSecret takes precedence. You can keep secretKey as a fallback during migration.
Migration Checklist
Before you start:
- Ensure
features.secretsV2.enabled: trueis set in your Helm values. - Create secrets in the target domain or global scope before workloads reference them.
During migration:
- Update workloads one at a time — V1 and V2 references can coexist.
- Existing
${secrets.key}placeholders continue to work, no forced cutover. - Legacy secrets appear under the Global scope.
- Use structured secret references for all new configurations.
Security
- No plaintext storage: Databases store only references—values are fetched at runtime.
- Protected credentials: Vault credentials stored in dedicated Kubernetes secrets, never exposed via APIs.
- Scoped access: Domain secrets guarded by domain permissions; Vault access enforced through RAS.
- Rotation: Update secrets in Kubernetes or Vault, then redeploy workloads.
Rotate secrets regularly. Never commit secret values to version control.