The sovereign data platform.
Your data, your future.
A sovereign data lakehouse, self-hosted in your trusted environment. Built to handle the scale, cost, and privacy challenges of the AI era. Run it on-premise, in your cloud, or hybrid — always under your control.









Yesterday’s platforms were built for the cloud era. IOMETE was built for the AI era.
Data volumes are exploding and privacy and data ownership is more critical than ever. Why limit yourself to public cloud alone?
Why stomach forever growing bills? Why endure vendor lock-in? Why risk data breaches? Yesterday’s data platforms were not created to power tomorrow's AI. Ours was built for it.
IOMETE
Hybrid first
Our platform runs on-premises, in your data centers, in your private cloud, your public cloud or all of the above (hybrid).
Competitors
Public cloud only
Cloud SaaS solutions such as Databricks and Snowflake run on US public clouds only.
IOMETE
Customer-controlled
You remain as free as a bird.
No vendor lock-in, so you keep your future options open.
Competitors
Vendor-controlled
The SaaS vendor controls the infrastructure, software and hardware where the data is stored. This may result in vendor lock-in.
IOMETE
Customer independence
You can implement bespoke security measures and manage all aspects of data protection tailored to your needs.
Competitors
Vendor-dependent
SaaS makes you dependent on external parties for critical aspects of your data security and privacy.
IOMETE
Cost efficient
Reduce storage and compute cost by optimizing your on-premise/cloud mix. Put cloud discounts in your own pocket. Save 2-5x over SaaS/cloud.
Competitors
Expensive
Forever pay the SaaS cloud premium; this gets expensive quickly at petabyte-size.
IOMETE
Customizable
Get an open and flexible platform. Tailor it to your specific needs.
Competitors
One-size-fits-all
SaaS is one-size-fits-all. This may not matter for a startup with a few gigabytes, but is suboptimal for petabyte-scale deployments.
Built for the hybrid era.
Store your data anywhere. Organize it into clear data domains and apply mesh principles for true self-serve. Advanced access controls let you fine-tune permissions down to users, teams, tables, columns, or rows — so every team gets precisely the data they need.

With IOMETE, your team can easily manage massive data sets and turn them into business results.
IOMETE Sovereign Data Platform
Our forward-deployed engineers: Your team, extended.
Sometimes software is only a part of the solution. We can provide FDEs that become an extension of your team.
They bridge the gap between technology and execution, making sure you see results faster.
See what IOMETE can do.

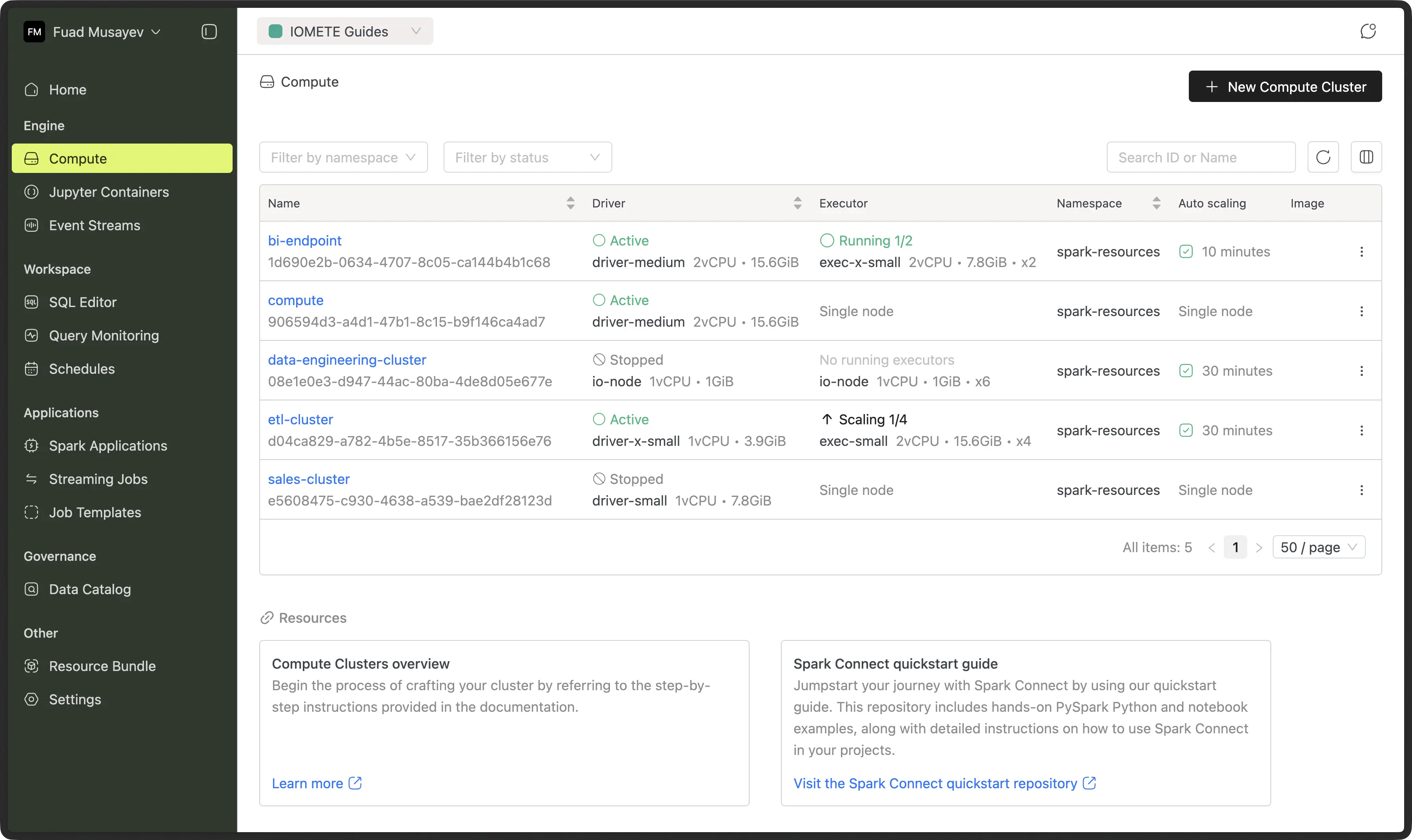
Easily spin up multiple lakehouses tailored to specific needs – separate environments for development, testing, and production workloads, or dedicated lakehouses for different business units, regions, or data domains.
Spark Connect lets you seamlessly run Spark workloads from your preferred development environment. Code in Python, R, or SQL using familiar tools like Jupyter notebooks while leveraging IOMETE’s distributed computing power. Connect, analyze, and process data at scale without leaving your local setup.

Connect to IOMETE’s lakehouses through interactive Jupyter notebooks. Run Python, R, or SQL code against your data using familiar notebook interfaces, with built-in kernels that handle distributed processing seamlessly.

Write, analyze, and optimize SQL queries with IOMETE's built-in editor. Features intelligent autocompletion, query history, and visual explain plans to help you write efficient queries against your lakehouse data.

Track and review all previously executed queries with detailed runtime statistics, execution plans, and performance metrics. Easily reuse successful queries and troubleshoot performance bottlenecks.

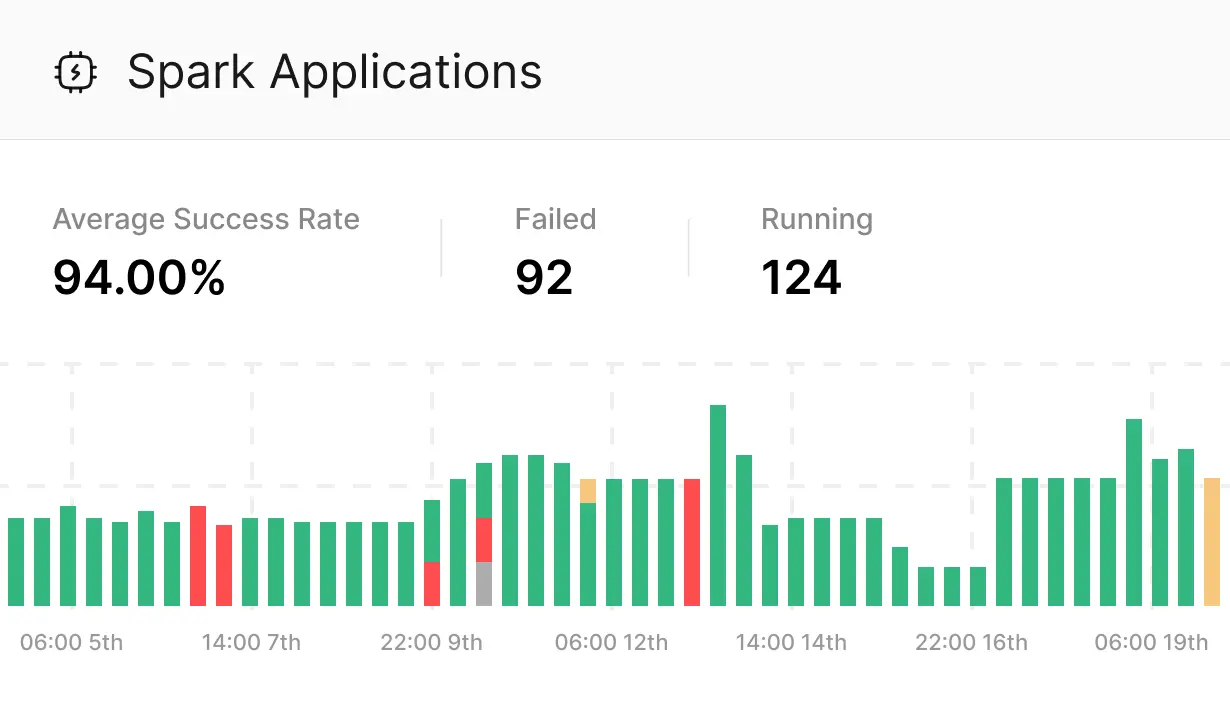
Deploy and manage custom Spark applications through IOMETE’s interface. Monitor resources, track performance metrics, and schedule jobs with built-in orchestration capabilities, all while maintaining full control over your Spark environment.
Process real-time data streams from sources like Apache Kafka, Amazon Kinesis, and Apache Pulsar to gain immediate insights and trigger actions.
Save and reuse your data processing workflows, making it easy to standardize and automate your data pipelines.

Easily discover, understand, and trust your data assets with a centralized repository that provides metadata, lineage, and quality information.

Interactively explore and query your data, allowing you to quickly analyze and understand your datasets.

Securely manage and control access to your data at the table, row, column, as well as the user, group, team, and department level, ensuring that only authorized individuals and teams can access the specific data they need.
Protect sensitive data by automatically replacing it with realistic but fictional values, allowing you to safely use data for development, testing, and analytics without compromising privacy.
Use tags to enforce access policies based on data categorization. Organize and categorize your data using custom tags, making it easier to search, filter, and manage your data assets. This helps improve data discovery, data security, and understanding across your organization.

IOMETE lets you organize and govern your data by subject area (e.g. customer, product, finance) to simplify data discovery, access control, and compliance with regulations like GDPR.

Easily connect to your favorite BI tool by using the SQL endpoint.
Easily spin up multiple lakehouses tailored to specific needs – separate environments for development, testing, and production workloads, or dedicated lakehouses for different business units, regions, or data domains.
Spark Connect lets you seamlessly run Spark workloads from your preferred development environment. Code in Python, R, or SQL using familiar tools like Jupyter notebooks while leveraging IOMETE’s distributed computing power. Connect, analyze, and process data at scale without leaving your local setup.
Connect to IOMETE’s lakehouses through interactive Jupyter notebooks. Run Python, R, or SQL code against your data using familiar notebook interfaces, with built-in kernels that handle distributed processing seamlessly.
Write, analyze, and optimize SQL queries with IOMETE's built-in editor. Features intelligent autocompletion, query history, and visual explain plans to help you write efficient queries against your lakehouse data.
Track and review all previously executed queries with detailed runtime statistics, execution plans, and performance metrics. Easily reuse successful queries and troubleshoot performance bottlenecks.
Deploy and manage custom Spark applications through IOMETE’s interface. Monitor resources, track performance metrics, and schedule jobs with built-in orchestration capabilities, all while maintaining full control over your Spark environment.
Process real-time data streams from sources like Apache Kafka, Amazon Kinesis, and Apache Pulsar to gain immediate insights and trigger actions.
Save and reuse your data processing workflows, making it easy to standardize and automate your data pipelines.
Easily discover, understand, and trust your data assets with a centralized repository that provides metadata, lineage, and quality information.
Interactively explore and query your data, allowing you to quickly analyze and understand your datasets.
Securely manage and control access to your data at the table, row, column, as well as the user, group, team, and department level, ensuring that only authorized individuals and teams can access the specific data they need.
Protect sensitive data by automatically replacing it with realistic but fictional values, allowing you to safely use data for development, testing, and analytics without compromising privacy.
Use tags to enforce access policies based on data categorization. Organize and categorize your data using custom tags, making it easier to search, filter, and manage your data assets. This helps improve data discovery, data security, and understanding across your organization.
IOMETE lets you organize and govern your data by subject area (e.g. customer, product, finance) to simplify data discovery, access control, and compliance with regulations like GDPR.
Easily connect to your favorite BI tool by using the SQL endpoint.
The cornerstone of our security strategy is our unique self-hosted architecture.



IOMETE operates entirely within the customer’s trust perimeter, whether on-premises or in the customer’s cloud account. This setup ensures that customers maintain complete control and ownership of their data.
By minimizing data movement, we not only reduce costs but also significantly lower the risk of data leaks or loss, while preventing vendor lock-in. Thanks to IOMETE’s unique self-hosted architecture, it’s impossible for us to lose your data simply because it is stored in your trusted environment.
Read our latest insights.

Interpreting the Gartner® Market Guide for Data Lakehouse Platforms
IOMETE made the 2025 Gartner® Market Guide for Data Lakehouse Platforms — a signal that our independent, self-hosted approach resonates with enterprises that expect data sovereignty.



Starting with IOMETE is simple. Book a demo with us today.
The IOMETE data platform helps you achieve more. Book a personalized demo and experience the impact firsthand.