What is IOMETE?
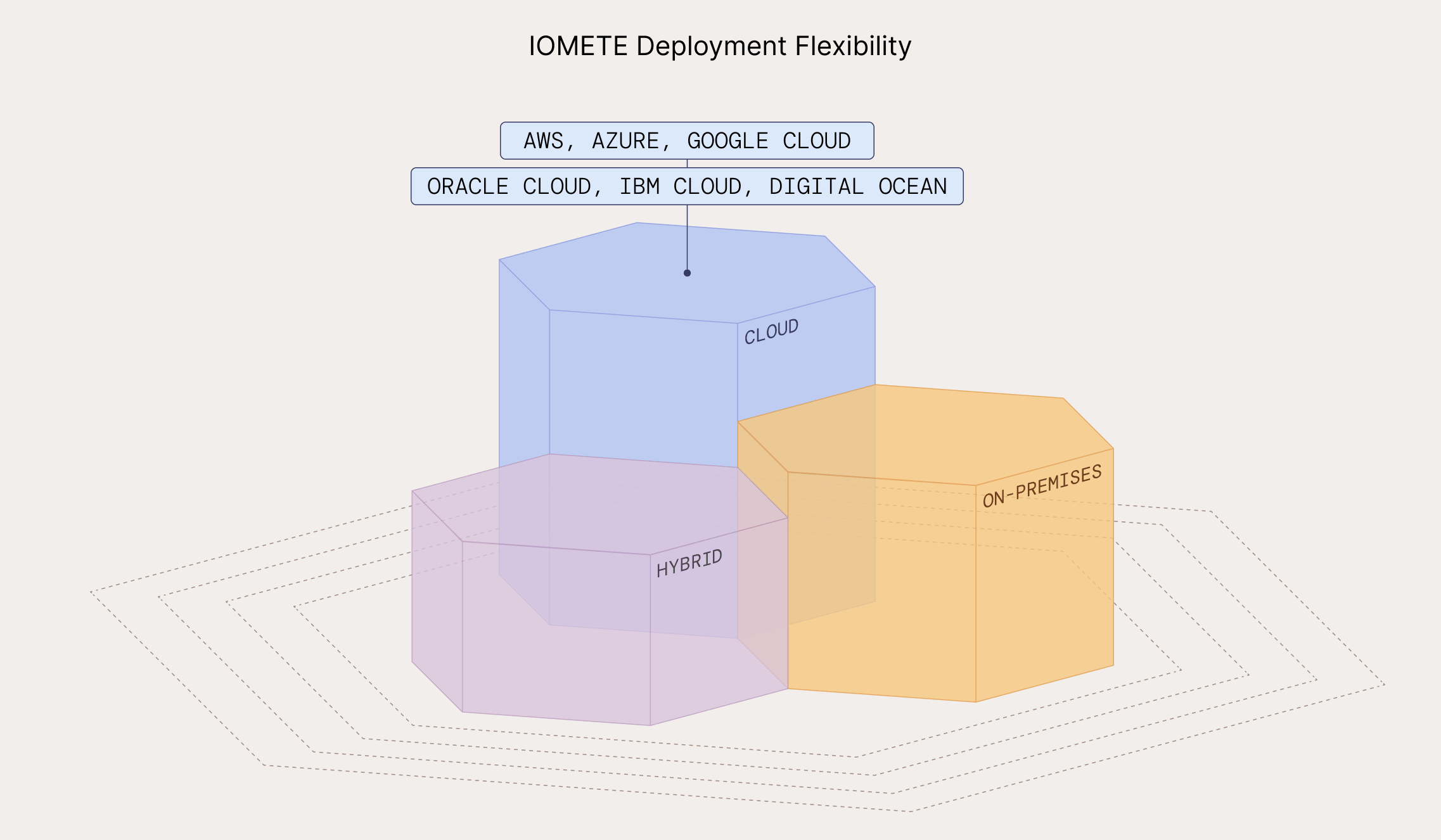
IOMETE is a state-of-the-art, fast, scalable, user-friendly Data Lakehouse Platform for AI and Analytics. It offers flexibility and can be deployed anywhere – on-premises, in the cloud, or in a hybrid environment.
Introduction to IOMETE
IOMETE is a cutting-edge Data Lakehouse Platform that revolutionizes how organizations manage and analyze their data. It has been engineered to deliver exceptional performance and flexibility for AI and analytics workloads. Here's what makes IOMETE stand out:
-
Fast: IOMETE leverages Apache Spark, a high-performance data processing engine, to deliver lightning-fast data analytics and processing capabilities.
-
Scalable: With IOMETE's cloud-native architecture, you can scale your data processing and storage resources independently, allowing your organization to handle data of any scale seamlessly.
-
User-Friendly: IOMETE offers a user-friendly interface and is compatible with popular BI tools and data science platforms, making it accessible to both technical and non-technical users.
-
Flexible Deployment: You can deploy IOMETE anywhere, whether it's on-premises, in the cloud, or in a hybrid environment, providing you with the flexibility to choose the environment that suits your needs.
Understanding Data Lakehouse
What is a Data Lakehouse?
A data lakehouse is a modern data management architecture that combines the advantages of data lakes and data warehouses. It brings together the scalability of data lakes with the reliability, data quality, ACID transactions, and security features of data warehouses. IOMETE embraces this concept to provide you with a robust platform for managing your data.
Data Lake vs. Data Lakehouse
While a data lake stores structured and unstructured data at scale, a data lakehouse, such as IOMETE, goes a step further by incorporating data warehouse features. This means you can perform operations like ACID transactions, updates, deletes, and merges within your data lakehouse environment.
Data Lakehouse = Data Lake + Data Warehouse
High-Level Architecture
IOMETE utilizes a decoupled compute and storage architecture, which allows for the independent scaling of compute and storage. To put it simply, IOMETE acts as the computation, management, and governance layer that connects to the storage layer. IOMETE's architecture is designed to provide optimal performance and flexibility for data processing.

Let's take a closer look at its components:
Storage Layer
Storage backends
IOMETE supports various storage backends. You can choose the storage backend that best suits your needs.
- Cloud storages:
- AWS S3
- Azure Blob Storage
- Azure Data Lake Storage Gen2
- Google Cloud Storage
- Digital Ocean Spaces,
- S3 Compatible Object Storages
- MinIO
- Dell EMC ECS
- Hadoop HDFS
- Network File Systems (NFS)
- And, even local file systems.
Data formats
IOMETE seamlessly handles structured, semi-structured, and unstructured data formats, ensuring you can work with diverse data types effectively.
Structured data and semi-structured data:
- Apache Parquet
- Apache Avro
- Apache ORC
- JSON
- XML
- CSV
Unstructured (raw) data:
- Images
- Videos
- Audio
- Text
- etc.
Lakehouse Storage formats:
And, IOMETE uses these Lakehouse Storage formats offering you the best integration options for managing your data.
- Apache Iceberg
Compute Layer
IOMETE runs on Kubernetes, providing Compute Clusters that expose SQL endpoints for querying large-scale data. You can connect BI and data science tools such as Tableau and Jupyter to IOMETE via JDBC/ODBC, Spark Connect, or Arrow Flight protocol.
The platform also includes additional services like Spark Jobs, Advanced Data Access Control, Data Catalog, and Jupyter Containers. IOMETE utilizes Apache Spark, a widely adopted open-source data processing engine, known for its speed and versatility.
Key Features
IOMETE offers a wide range of features to enhance your data engineering experience. Here are some key highlights:
-
Query Federation Engine: Seamlessly query data from multiple sources, including relational and NoSQL databases, and flat files without the need for complex ETL pipelines.
-
Data Catalog: Maintain a centralized repository for dataset metadata, promoting collaboration and resource sharing.
-
Central Data Access Control: Manage access control policies for all datasets, including selective masking for sensitive fields, with fine-grained permissions managed through the Identity Service.
-
Integration with External Tools: Easily integrate with external tools, including Apache Airflow and BI tools like Tableau and Power BI.
-
BI Tool Integration: Effortlessly work with major BI tools for comprehensive business intelligence experiences.
-
Collaborative SQL Editor: Write and edit SQL queries in real-time with multiple team members simultaneously.
-
Event Streams: Ingest real-time events via REST API directly into Iceberg tables for immediate analytics.
-
Spark Connect & Arrow Flight: Connect programmatically from BI tools, data apps, and notebooks using Spark Connect or Arrow Flight protocol.
-
Git Integration: Version control your SQL worksheets and queries with Git for change tracking and collaboration.
-
Multi-Domain Support: Organize teams, projects, or environments into separate domains, each with its own resources, members, and roles.
-
Exceptional Performance: Benefit from optimizations and modern technologies that deliver superior performance compared to competitors.
-
Security Features: Ensure data protection with robust authentication, authorization, encryption, and advanced monitoring/logging.
Data Security and Privacy
Rest assured that IOMETE prioritizes your data security and privacy. The platform operates entirely within your infrastructure, ensuring that no data is sent outside of your organization. This approach guarantees complete security and privacy for your sensitive data.
Multi-Region Support
IOMETE Enterprise Edition offers a control plane and multi-data plane architecture. This means you can deploy IOMETE across multiple regions and manage them from a single control plane. This feature is invaluable for disaster recovery, high availability, and multi-region deployments.
Benefits of Using IOMETE
Unparalleled Performance and Scalability
- Fast Data Processing: Leverages Apache Spark for lightning-fast analytics and data processing.
- Scalability: Cloud-native architecture allows for seamless handling of data at any scale.
User-Friendly and Flexible Deployment
- Intuitive Interface: User-friendly for both technical and non-technical users, enhancing accessibility.
- Versatile Deployment Options: Can be deployed on-premises, in the cloud, or hybrid environments, suiting diverse organizational needs.
Enhanced Data Management and Security
- Robust Data Lakehouse Architecture: Combines the benefits of data lakes and warehouses, offering scalability with reliability and security.
- Comprehensive Data Formats Support: Handles a wide range of data types, from structured to unstructured formats.
- Data Security and Privacy: Operates within your infrastructure, ensuring no data is sent outside, thus prioritizing security and privacy.
Advanced Analytics and Integration Capabilities
- Query Federation Engine: Queries data from multiple sources without complex ETL, streamlining data analytics.
- Broad Tool Integration: Compatible with popular BI tools and data science platforms for extensive analytics and business intelligence.
Efficient Data Governance and Collaboration
- Central Data Access Control: Fine-grained access control policies managed through the Identity Service.
- Data Catalog: Centralized repository for dataset metadata, promoting efficient collaboration and resource sharing.
High Availability and Disaster Recovery
- Multi-Region Support: Enterprise Edition features multi-region deployment for disaster recovery and high availability.
Technological Excellence
- Cutting-Edge Components: Utilizes leading technologies like Apache Spark, Apache Iceberg, and Kubernetes for top-notch performance and elasticity.
- Comprehensive Data Processing Services: Includes services like Spark Jobs, Data Catalog, and Jupyter Containers for a complete data engineering experience.
Glossary
Before diving deeper into IOMETE, familiarize yourself with the key terms and concepts used in the platform:
-
Object Storage: A durable and available object storage system, with MinIO configured for optimal performance.
-
Compute Cluster with Kubernetes: Kubernetes orchestrates IOMETE services, including Compute Clusters and Spark job clusters, providing elasticity and scalability.
-
Lakehouse Platform: Powered by Apache Spark and Apache Iceberg, it offers a robust SQL interface for data exploration and analytics, including ACID-compliant operations, schema evolution, and data versioning.
-
Query Federation Engine: Allows querying data from multiple sources without complex ETL pipelines.
-
Spark Job Service: Facilitates running and monitoring Spark Jobs, including Spark Streaming for real-time data processing.
-
Jupyter Containers: Interactive notebook environments for data exploration, ad-hoc queries, and ML development, running directly on the platform.
-
Data Catalog: A centralized repository for dataset metadata, enhancing collaboration and resource sharing.
-
Central Data Access Control: Manages access control policies across all datasets, including selective masking for sensitive fields, with fine-grained permissions managed through the Identity Service.
-
Collaborative SQL Editor: Features syntax highlighting, auto-completion, and real-time multi-user editing, allowing team members to work on queries simultaneously.
-
Integration with External Tools: Supports integration with tools like Apache Airflow and BI tools, enhancing extensibility and existing infrastructure compatibility.
-
Event Streams: Real-time event ingestion via REST API, storing events directly into Iceberg tables for immediate analytics.
-
Spark Connect & Arrow Flight: Protocols for programmatic access to compute clusters from BI tools, data applications, and notebooks.
-
Git Integration: Version control SQL worksheets and queries with Git for change tracking and team collaboration.
-
Multi-Domain Support: Logical separation of teams, projects, or environments into domains, each with independent resources, members, and roles.
Next Steps
Explore the rest of the Getting Started section to learn more about the platform:
- Architecture Overview - detailed microservices breakdown, service routing, and technology stack
- Platform Tour - navigate the IOMETE console, sidebar menus, and domain vs. admin areas
- Scalability - four scaling layers, autoscaling configuration, and cost optimization
- Support - getting help and contacting the IOMETE team