Architecture Overview
IOMETE is a Data Lakehouse Platform for AI and Analytics built on Apache Spark, Apache Iceberg, and Kubernetes. It deploys as a Helm chart into a Kubernetes cluster and uses object storage (AWS S3, Google Cloud Storage, Azure Blob/ADLS, MinIO, Dell ECS) as its data layer. From a single console, you can manage compute clusters, run Spark jobs, query data with SQL, browse the data catalog, and enforce security policies.
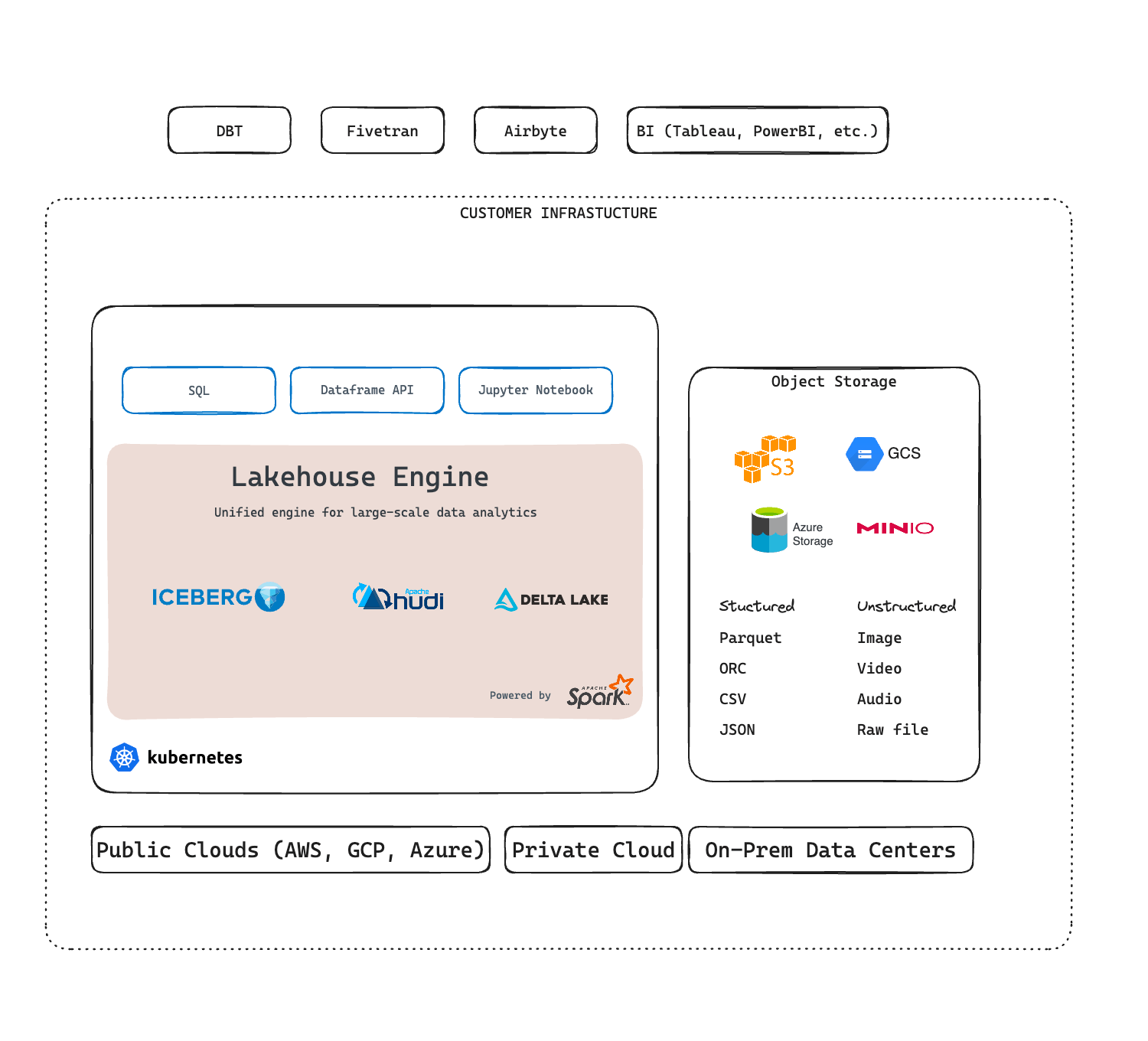
High-Level Architecture
Knowing the overall layout makes it easier to reason about where data lives, how services talk to each other, and what you can scale independently. IOMETE runs on Kubernetes (any cloud provider or on-premises data center), stores data in object storage, and keeps metadata in PostgreSQL. All platform services live inside a single Kubernetes namespace, with optional multi-namespace support for Spark workloads.
The architecture breaks into three tiers:
- Infrastructure layer: Kubernetes cluster and object storage
- Platform services: Microservices that manage metadata, security, catalog, SQL, and orchestration
- Workloads: Spark-based compute (clusters, jobs, notebooks, event streams) that you create on demand
Platform Services
The IOMETE Console is backed by a set of microservices, each responsible for a specific domain. Because they're independent, you can update and scale them separately. All of them run as containerized Kubernetes Deployments exposed through ClusterIP Services.
IOMETE Gateway
All traffic enters the platform through a single Nginx reverse proxy. API calls, UI assets, Spark Connect, Arrow Flight, and WebSocket connections all flow through the Gateway, which routes each request to the right backend service based on URI pattern. The Gateway also proxies gRPC for Spark Connect and Arrow Flight, so BI tools and data applications can reach compute clusters directly.
Core Service
The Core Service owns platform-wide settings and cross-cutting concerns:
- Data plane and system configuration
- Authentication and access tokens
- Authorization checks
- Node type and volume management
- Spark settings
- S3 browser for object storage exploration
- Spark History Server proxy (the Spark History UI is accessible through this service)
- Integration settings (notifications, external services)
Cluster Service
This is the largest service by API surface because it manages every Spark-based resource:
- Compute clusters: create, start, stop, delete
- Spark batch and streaming jobs: submission, monitoring, scheduling
- Jupyter containers: lifecycle management
- Docker registries and image management
- Namespace and secrets management
- Event stream definitions
Identity Service
Controls who can access the platform and what they're allowed to see or change:
- User and group management
- Role management and member assignment
- LDAP, SAML, and OIDC integrations for single sign-on
- Apache Ranger policy management for data security (row-level filtering, column masking)
- Bundle-based authorization
SQL Service
Provides the backend for the SQL Editor, where most day-to-day querying happens:
- SQL query execution and result management
- Worksheets, workspaces, and folder organization
- Git integration for version-controlled SQL
- Query history and monitoring
- Database explorer for schema and catalog browsing
- Dashboards and scheduling
Catalog Service
The backend for the Data Catalog. Teams use it to discover and govern data:
- Full-text search and browsing (backed by Typesense)
- Table metadata and descriptions
- Classification tags and governance policies
- Access permissions
Iceberg REST Catalog Service
Implements the Apache Iceberg REST Catalog specification so that external tools and Spark engines can access Iceberg table metadata. Every data request passes through Apache Ranger policy enforcement, so access control stays consistent no matter how data is queried.
Health Check Service
Monitors all platform services and reports their status through the API. Checks run every 10 seconds, the service retains 48 hours of history, and status changes push to the console in real time.
Spark Infrastructure
Spark is the execution engine behind every query and job in IOMETE. The components below manage how Spark workloads get created, submitted, and tracked.
Spark Operator
A Kubernetes operator that manages Spark workloads through three components:
- Controller: watches for SparkApplication CRDs and manages the lifecycle of Spark pods
- Webhook: validates and mutates SparkApplication resources on submission
- Submit Service: handles submission of Spark applications to Kubernetes, with configurable parallelization and queueing
Spark Connect (Internal)
An internal Spark cluster used for metadata extraction and database explorer operations. It isn't user-facing. Instead, it powers features like schema browsing in the SQL Editor and Data Catalog.
Spark History Server
Reads Spark event logs from object storage and displays job history and performance details. You can access it through the IOMETE Console via the Core Service proxy.
Workloads
Unlike platform services, workloads don't ship with the Helm chart. The Spark Operator creates them dynamically when you provision resources through the Console or API.
Compute Clusters
These are SQL-accessible Spark clusters. Each one runs a Spark driver pod that exposes:
- HiveServer2 (port 10000): JDBC/ODBC connections from BI tools, dbt, and other SQL clients
- Spark Connect (port 15002): gRPC protocol for programmatic access
- Arrow Flight (port 33333): high-performance gRPC data transfer (when enabled)
See Compute Clusters for details.
Spark Jobs
Batch and streaming Spark applications. You can submit Scala or PySpark jobs, schedule them with the Job Orchestrator, and monitor execution through the console. See Spark Jobs.
Jupyter Containers
Dedicated JupyterLab environments for interactive data exploration, ETL prototyping, and ML development. Each container runs as a separate pod inside the cluster and is accessible through the Gateway with full WebSocket support. See Jupyter Containers.
Event Streams
Real-time data ingestion endpoints powered by Papyrus, a Rust-based ingestion engine. Each event stream receives HTTP POST requests and writes data to Iceberg tables. This is an optional feature that an administrator must enable. See Event Streams.
Security Architecture
IOMETE handles security at multiple layers. Authentication confirms your identity, authorization decides what you can do, and Apache Ranger policies control which rows and columns you can see.
Authentication
The Identity Service handles authentication directly and supports three modes:
- Built-in authentication: username/password with secure token management
- LDAP integration: connects to your existing directory service
- SSO via SAML or OIDC: integrates with your organization's identity provider
The login flow follows a redirect-based OIDC pattern: the console redirects to the Identity Service, which issues tokens after successful login.
Authorization
Authorization operates at three levels:
- Platform-level: The Core Service checks whether you can perform platform operations like creating compute clusters or managing settings.
- Data-level (Apache Ranger): The Iceberg REST Catalog enforces Ranger policies on every data access request. Ranger policies are managed through the Identity Service and control row-level filtering, column masking, and table-level permissions.
- Resource Access Service (RAS): A granular permission model that assigns per-resource permissions (VIEW, UPDATE, MANAGE) to compute clusters, Spark jobs, workspaces, and namespaces.
See Data Security, Roles, and Resource Access Service for details on configuring security policies.
Storage and Data Layer
Everything IOMETE stores (table data, Spark event logs, SQL results, worksheets) goes into object storage. Compute and storage are fully decoupled.
Object Storage
IOMETE supports multiple storage backends. The URI scheme depends on the provider:
| Storage Provider | URI Scheme |
|---|---|
| MinIO | s3a:// |
| Dell ECS | s3a:// |
| AWS S3 | s3a:// |
| Google Cloud Storage | gs:// |
| Azure Blob Storage (Gen1) | wasbs:// |
| Azure Data Lake Storage (Gen2) | abfs:// |
Database
All services share a single PostgreSQL server. The platform automatically creates separate databases for each service (Hive Metastore, Ranger policies, Iceberg catalog, and each microservice), so there's no manual database provisioning required.
Real-Time Communication
Several features depend on pushing updates to the browser without a page refresh:
- Socket Service: a WebSocket relay that pushes real-time events (health check updates, job status changes) to the console
- Collaboration Service: lets multiple users edit SQL in real time using CRDT-based conflict resolution (optional, feature-flagged)
- NATS: JetStream messaging for cross-pod synchronization of collaborative editing sessions (optional)
Job Orchestration
If you need scheduled, dependency-aware Spark job execution, the Job Orchestrator (powered by Prefect) adds workflow scheduling:
- Prefect Server: orchestration engine that manages workflow state
- Prefect Worker: runs scheduled Spark jobs (deployed per-namespace)
- Metrics Exporter: exposes Prometheus metrics for job orchestration monitoring
See Job Orchestrator for configuration details.
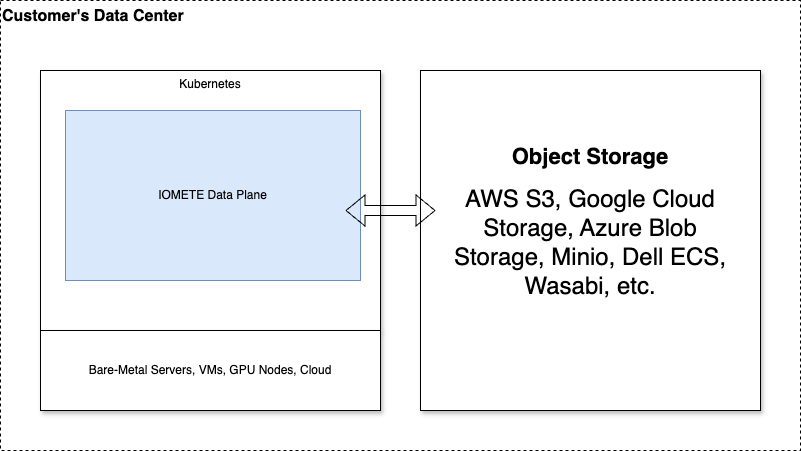
Deployment Architecture
Understanding the deployment topology helps you plan infrastructure, estimate resource needs, and configure the Helm chart for your environment.
For details on how IOMETE is deployed on Kubernetes (including the Helm chart structure, service inventory, feature flags, and infrastructure requirements), see the Deployment Architecture reference.
For step-by-step installation instructions, see the On-Premises Deployment Guide.