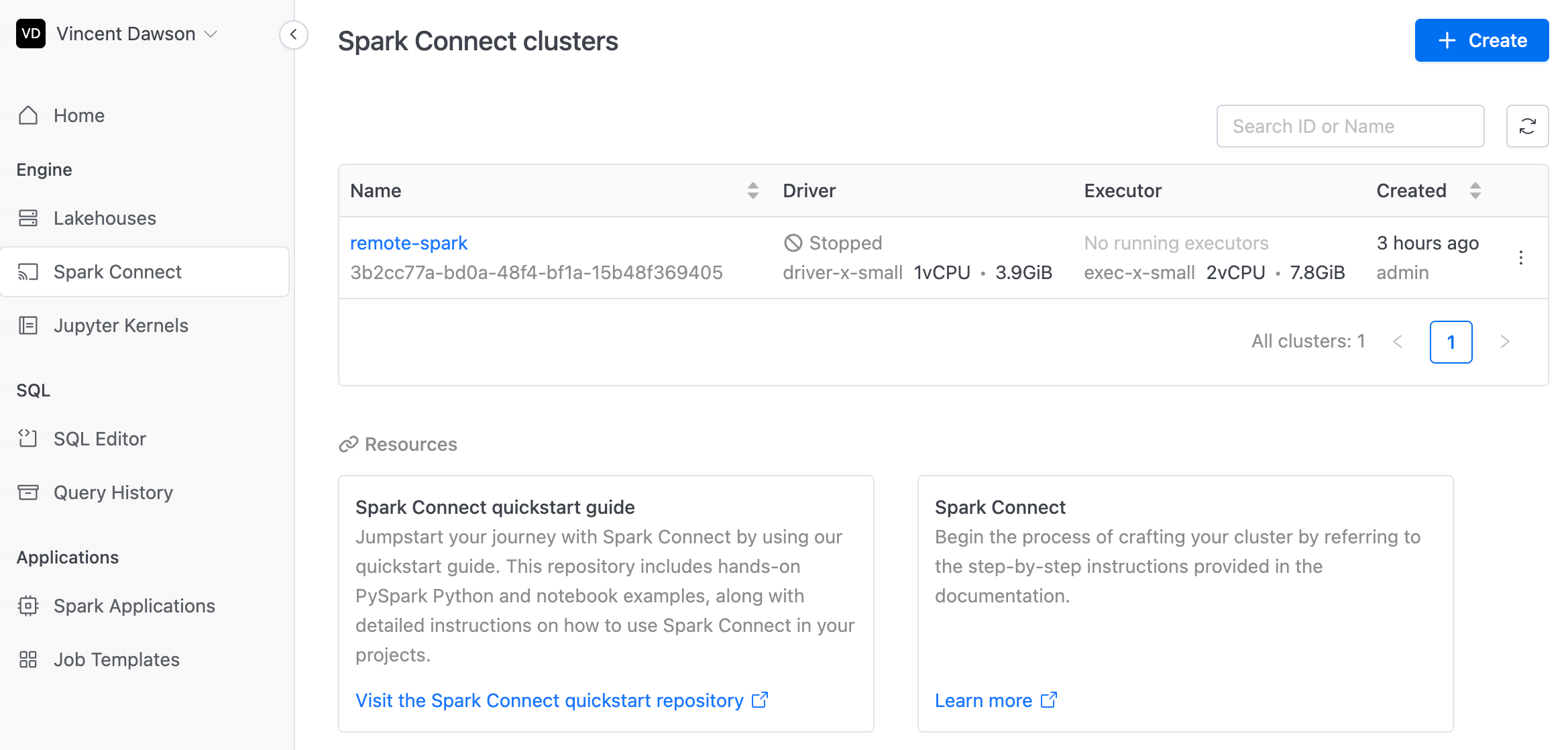
Spark Connect Clusters
In Apache Spark > 3.4, Spark Connect introduced a decoupled client-server architecture that allows remote connectivity to Spark clusters using the DataFrame API and unresolved logical plans as the protocol. The separation between client and server allows Spark and its open ecosystem to be leveraged from everywhere. It can be embedded in modern data applications, in IDEs, Notebooks and programming languages.
Create a new Connect Cluster
1. Go to the Spark Connect and click the Create button
2. Give the new cluster a name under Name.
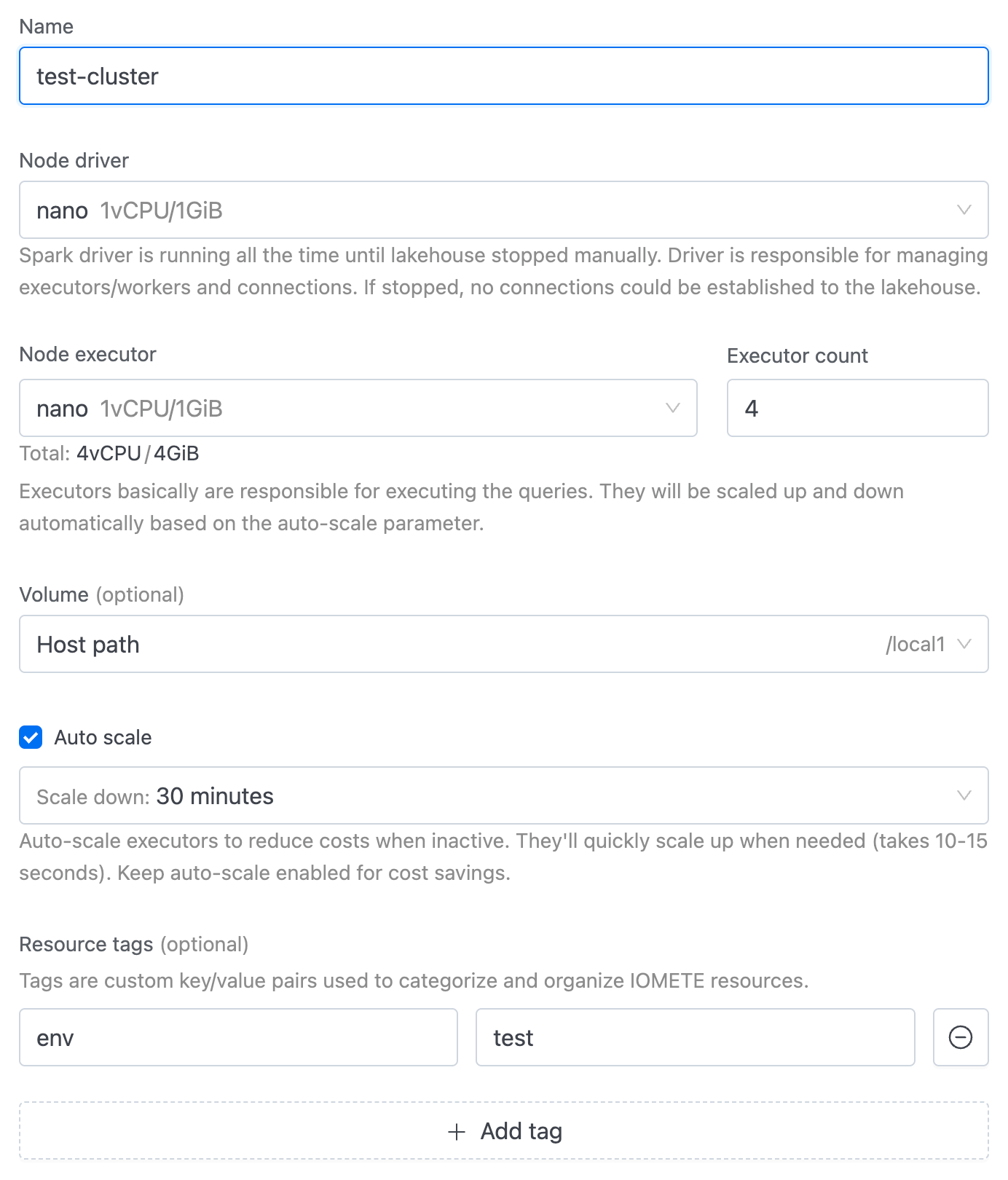
3. Select driver, under the Node driver section. Learn how to create a custom Node type.
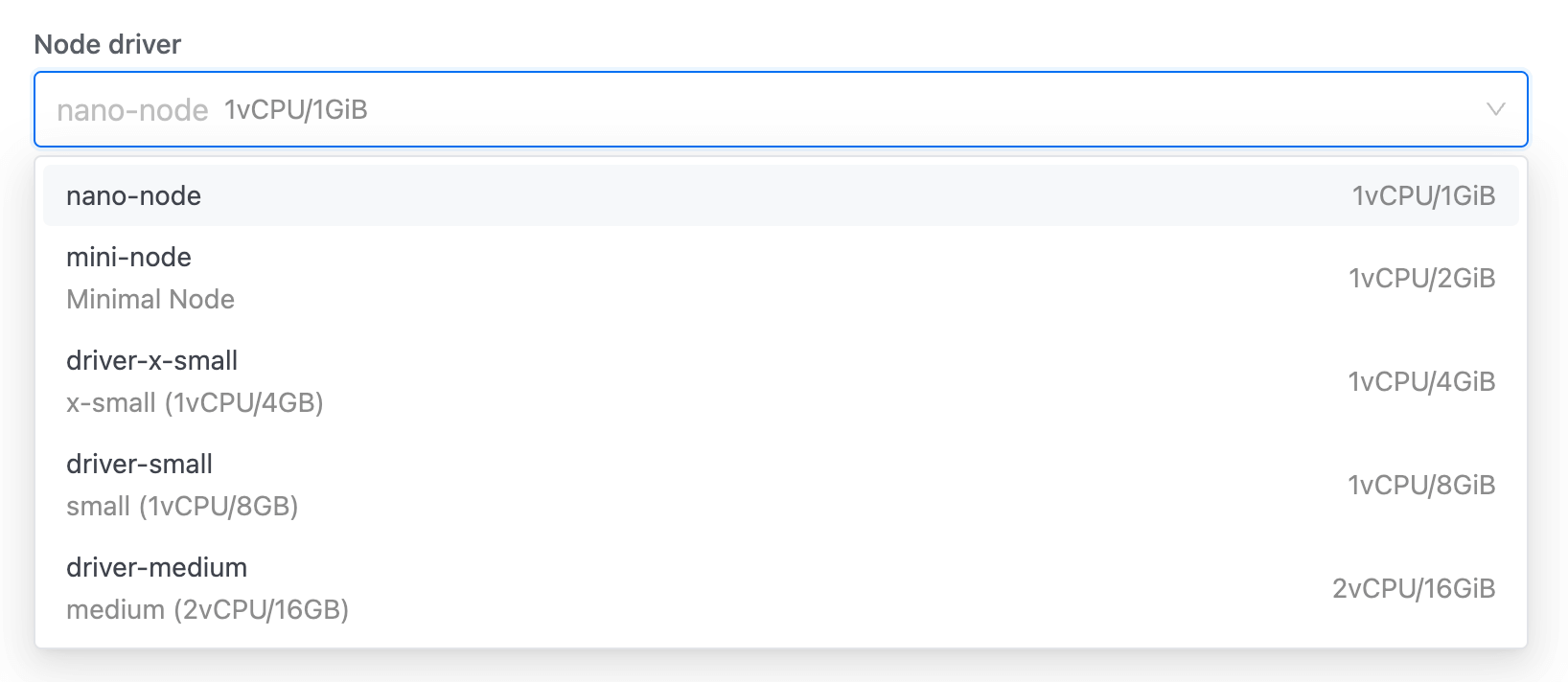
The Node driver runs continuously, managing executors/workers, and connections until manually stopped. If it stops, no new connections to the cluster can be made. It acts as the control center, orchestrating all tasks.
4. Select the type of executor from the Node executor section and enter the number of executors in the Executor count section. Below these inputs, you'll see a real-time preview of Total CPU and memory. This helps you choose the right number and type of executors, ensuring you allocate enough resources for your workload. Read more about spark executors.
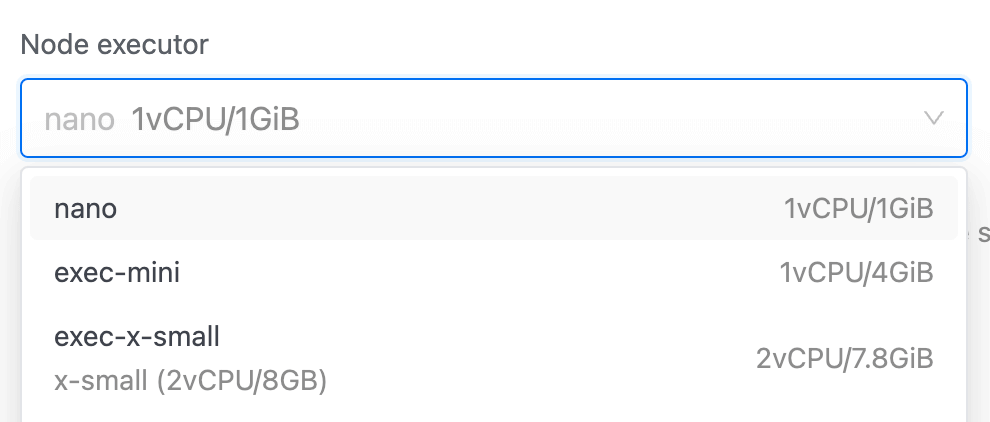
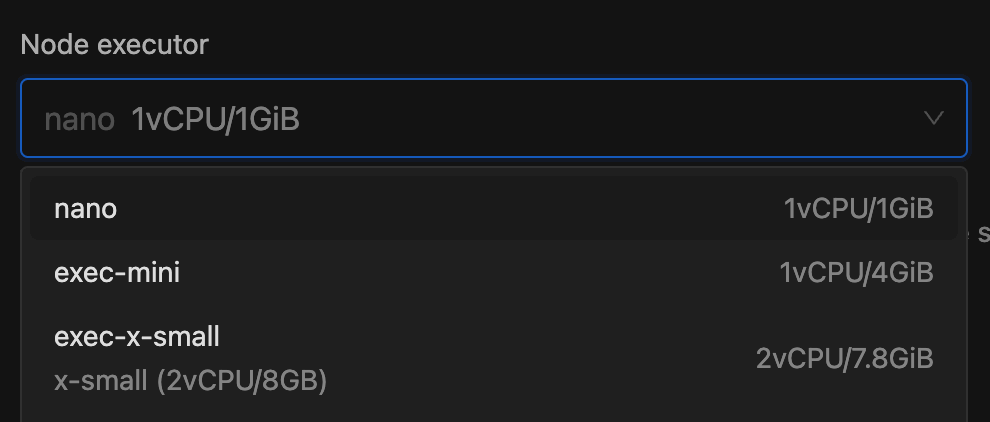
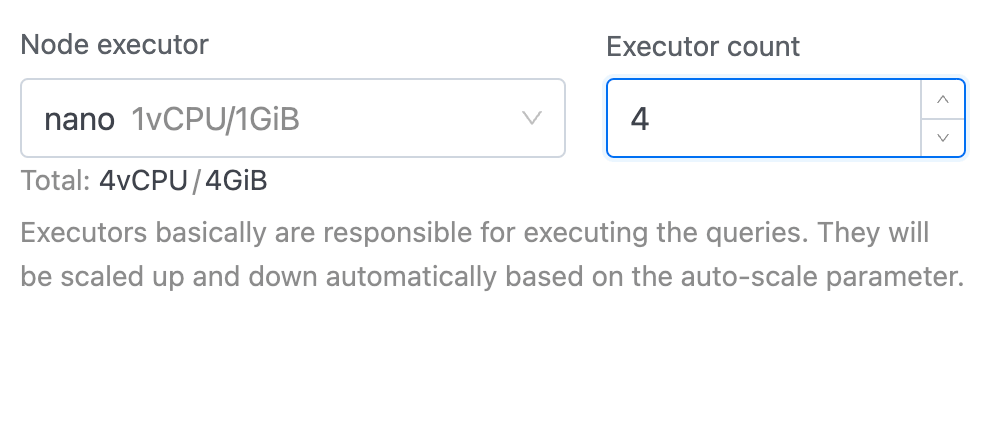
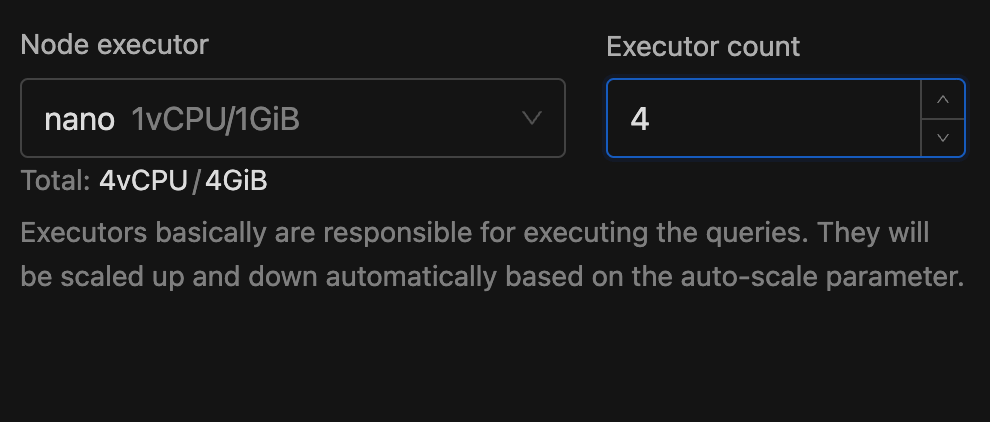
The Node Executor is responsible for executing queries and processing data. It scales automatically based on the auto-suspend parameter, ensuring efficient resource usage.
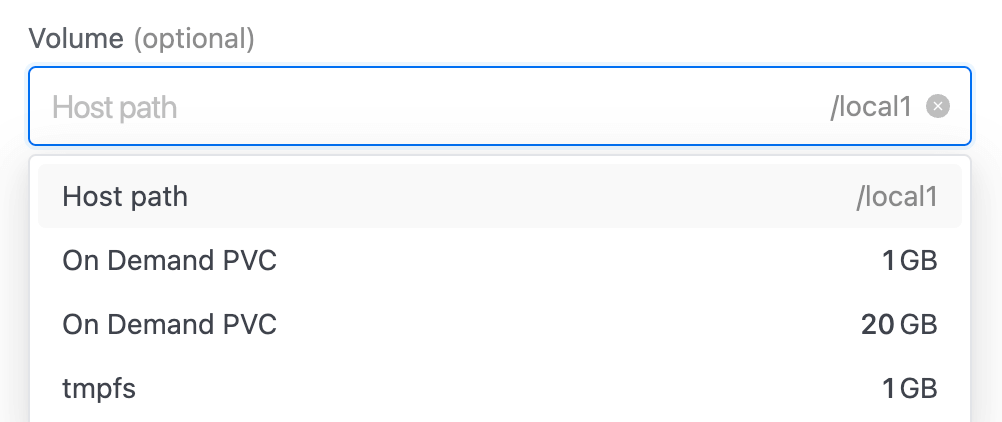
5. Select volume, under the Volume section. Read more about volumes.

6. Set Auto suspend under Auto suspend section. By clicking checkbox in the left side we can disabled Auto suspend functionality.
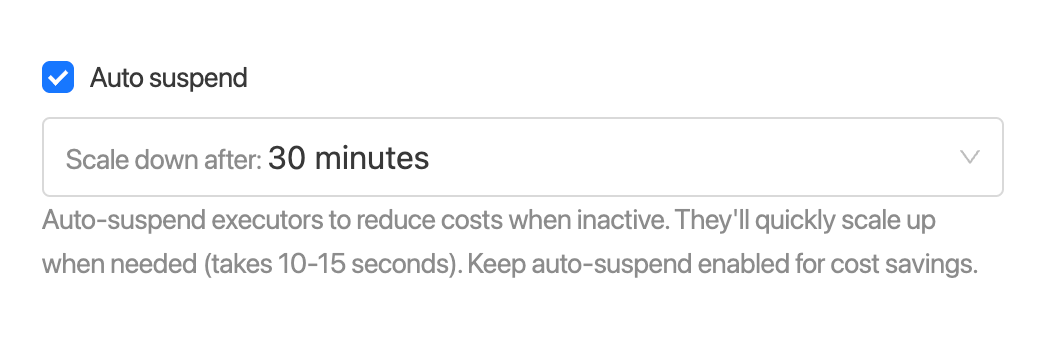
Executors will be scaled down after the specified time of inactivity. Executors will be scaled up automatically on demand (Scale up time around 10-15 seconds). It is recommended to keep auto-suspend on to minimize monthly costs.
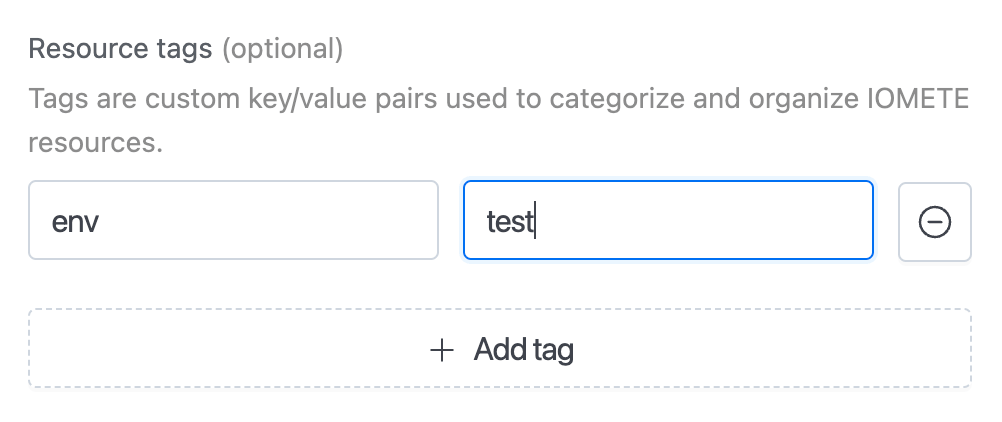
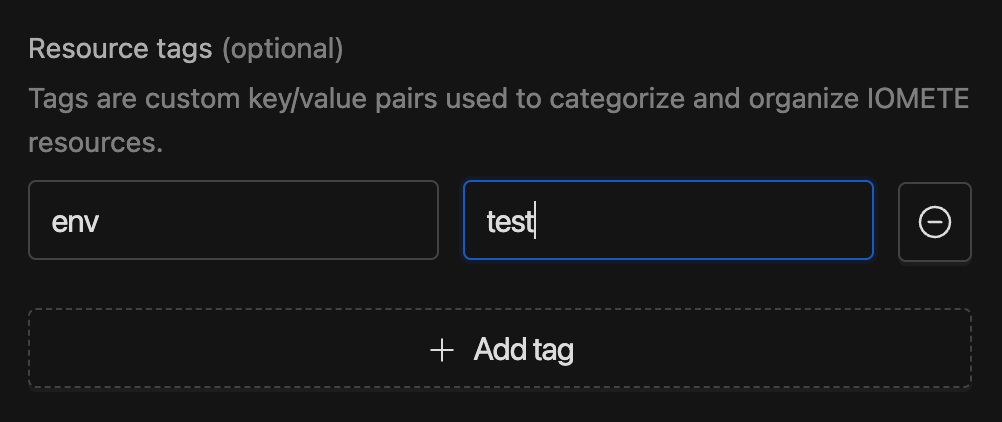
7. Resource tags are custom key/value pairs designed to help categorize and organize IOMETE resources. They provide a flexible and convenient way to manage resources by associating them with meaningful metadata.
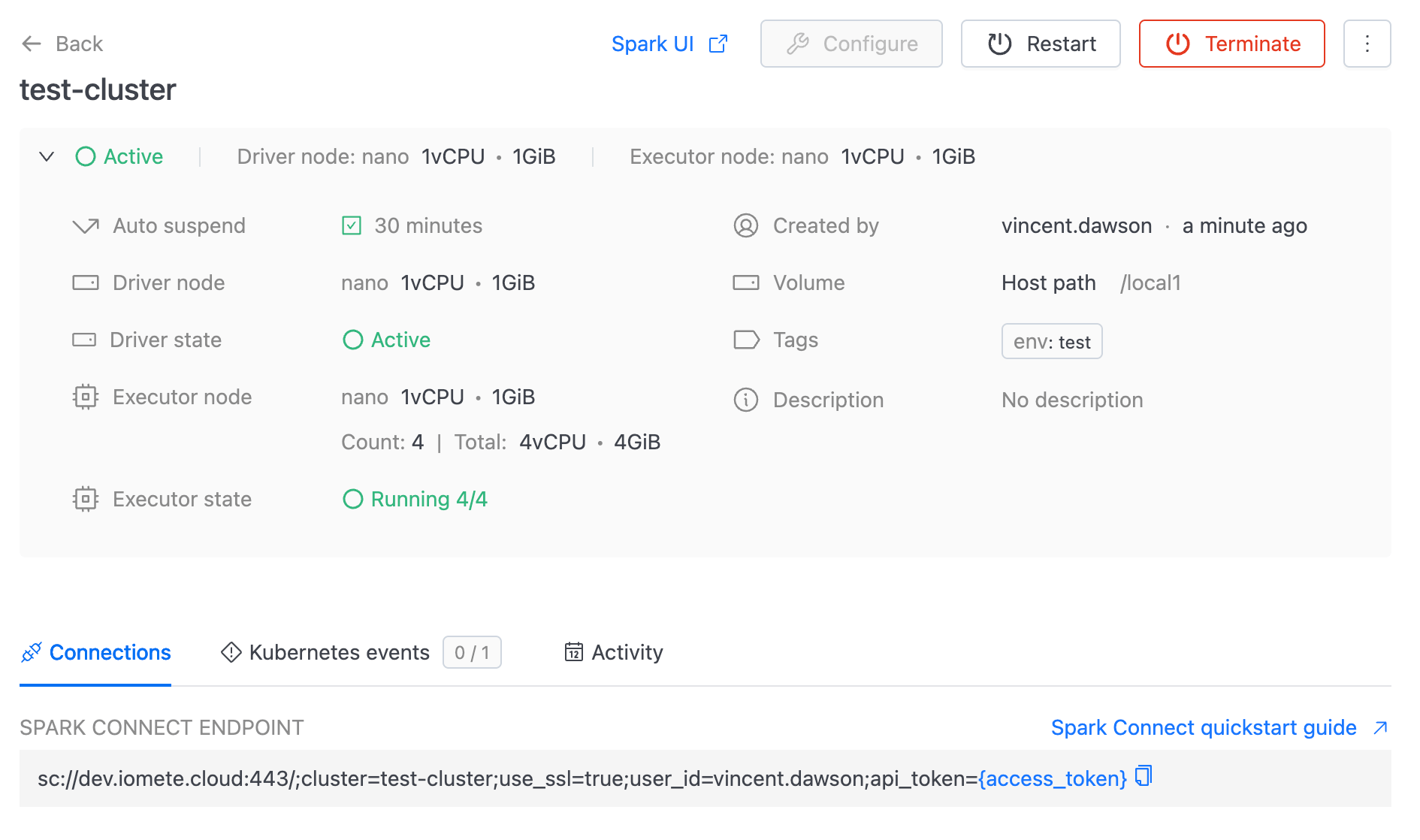
🎉 🎉🎉 Tadaa! The newly created test-cluster details view is shown.
Cluster details
The Cluster Detail View in our application provides a comprehensive overview and management options for a specific cluster instance.
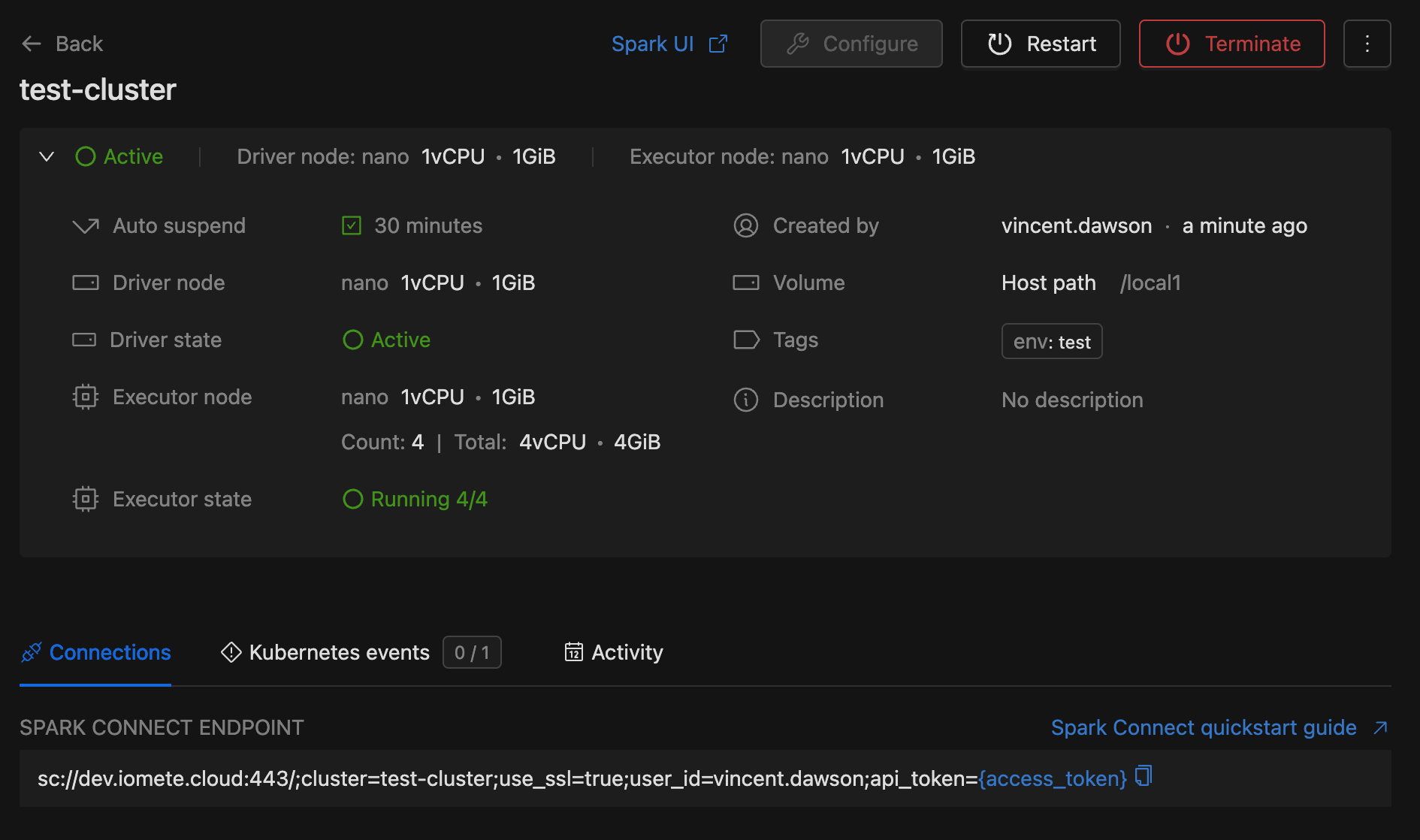
Navigation buttons
The header of the Detail View includes the following elements:
- Spark UI link: This link redirects users to the Spark UI for real-time metrics and logs.
- Configure: Opens the configuration settings for the cluster, enabling users to modify its parameters and settings.
- Start: Starts the cluster instance if it is not already running. If the instance is already running, this button will be replaced with
RestartandTerminate. - Restart: Restarts the cluster instance to apply new configurations or resolve issues by stopping and then starting it.
- Terminate: This button stops the cluster instance and terminates all associated processes and jobs. You can start the instance again if needed.
- Delete: Permanently deletes the cluster instance.


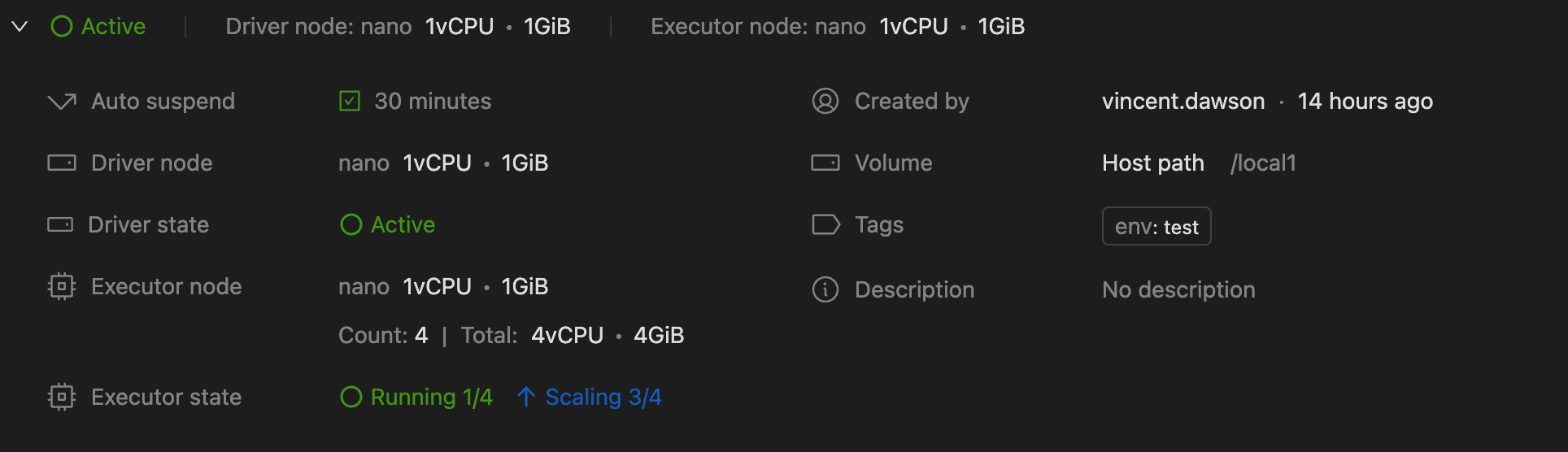
General informations
Under the header, there is a card displaying the following information about the Spark Connect.
Auto suspend
By default, scaling up usually takes 1 to 2 minutes, depending on various factors like the cloud provider's response time and resource availability.
In cloud environments, you can utilize IOMETE to establish a hot pool of preconfigured resources. This markedly accelerates the scaling process, reducing the scale-up time to a mere 10 to 15 seconds. Contact support to learn more about this feature.
Driver state��
- Starting: The Driver is booting up.
- Active: The Driver is running and ready to accept connections.
- Stopped: The Driver is offline and not accepting any connections.
- Failed: The Driver couldn't start. Contact support for assistance.
You're only charged for the Driver when it's in the Active state.
Executor state
- No running executors: There is no active executor. This happens when auto-suspend is configured. In this case, when there is no workload for a configured auto-suspend time, the cluster scales down to zero. Executors will scale up automatically based on demand.
- Running: Executors are active and processing data.
- Scaling: Executors are scheduled to start and waiting for resources to start.
Status examples
Running 1/4: One out of four Executors is active. The cluster scales down to save costs when the workload is light.Running 1/4Scaling 3/4: One Executor is active, and three are waiting to start due to an increase in workload.Running 4/4: All Executors are active, and the cluster is at full capacity.
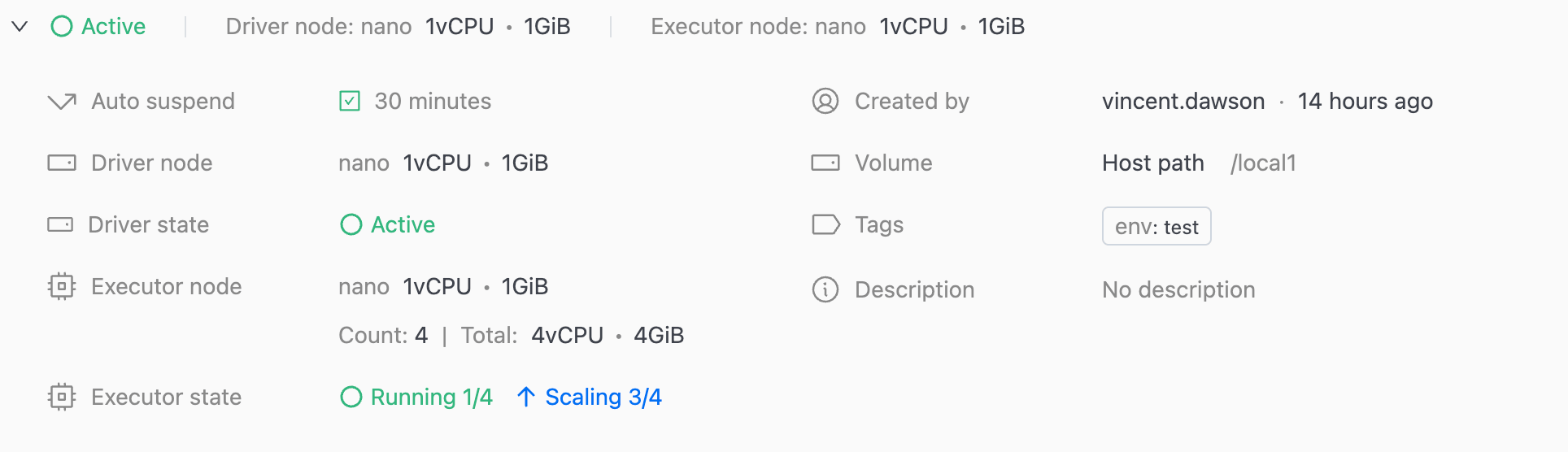
You're only billed for Executors when they're in the Running state.
Connections
In the Connections section, you can copy the endpoint for the connection.


Spark logs
In this section we can see Spark logs.
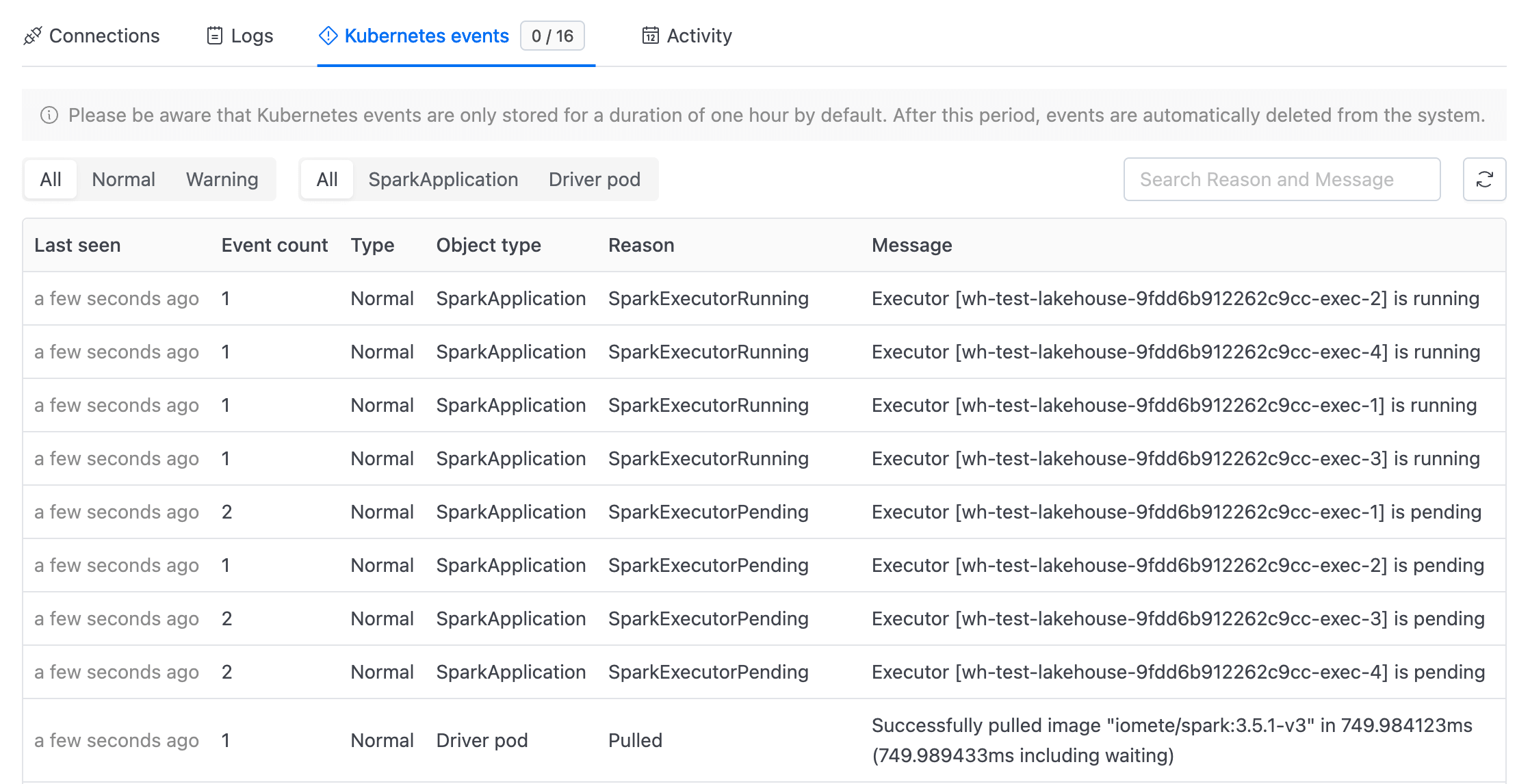
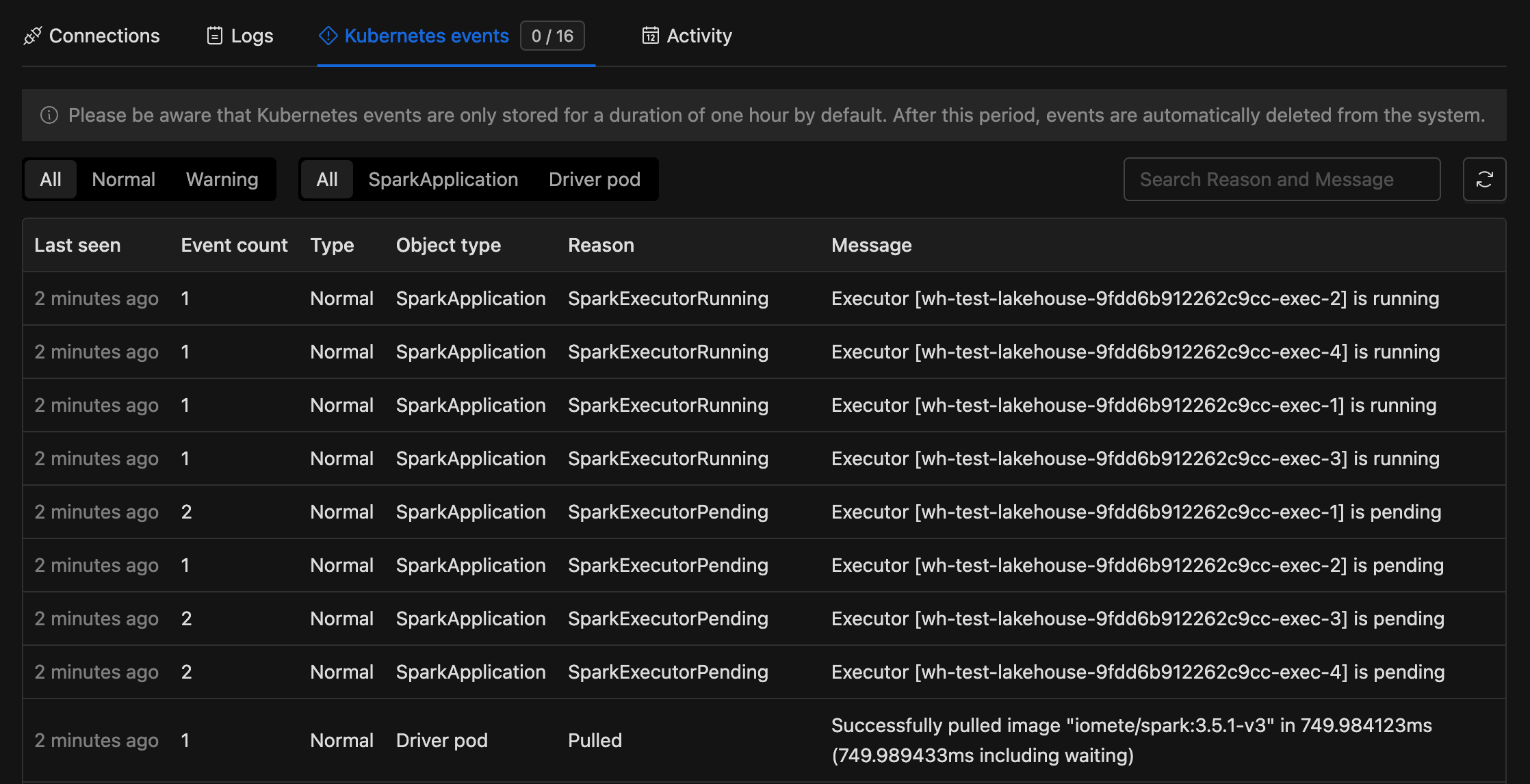
Kubernetes events
Kubernetes events are only stored for a duration of one hour by default. After this period, events are automatically deleted from the system.
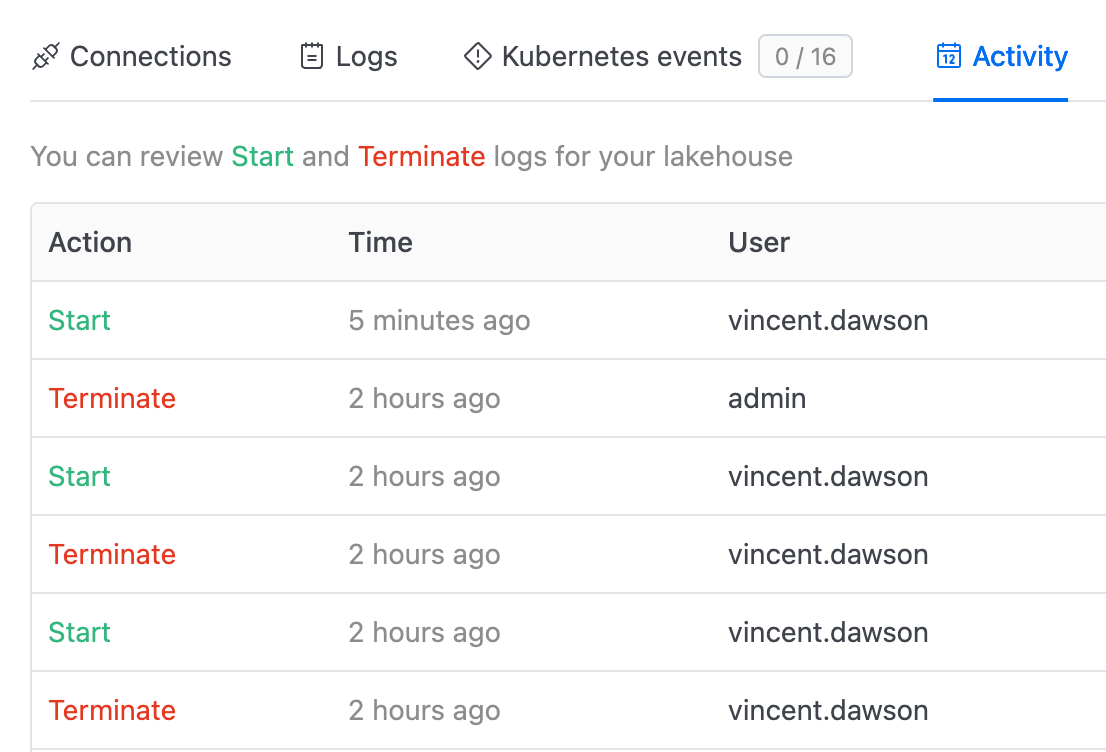
Resource activity
In this section we may check your lakehouse's Start/Terminate events.