Application Config
When creating a Spark job deployment programmatically with IOMETE, you would run a command similar to the following:
curl --location \
--request POST "https://sandbox.iomete.com/api/v1/spark-jobs" \
--header "X-API-Token: <ACCESS_TOKEN>" \
--header "Content-Type: application/json" \
--data-raw '{
"jobType": "MANUAL",
"name": "sample-job",
"template": {
"image": "iomete/sample-job:1.0.0",
"mainApplicationFile": "local:///app/job.py",
"instanceConfig": {
"driverType": "stde2pdsv5dr",
"executorType": "stde2pdsv5",
"executorCount": 1
}
}
}'
Or, using IOMETE console
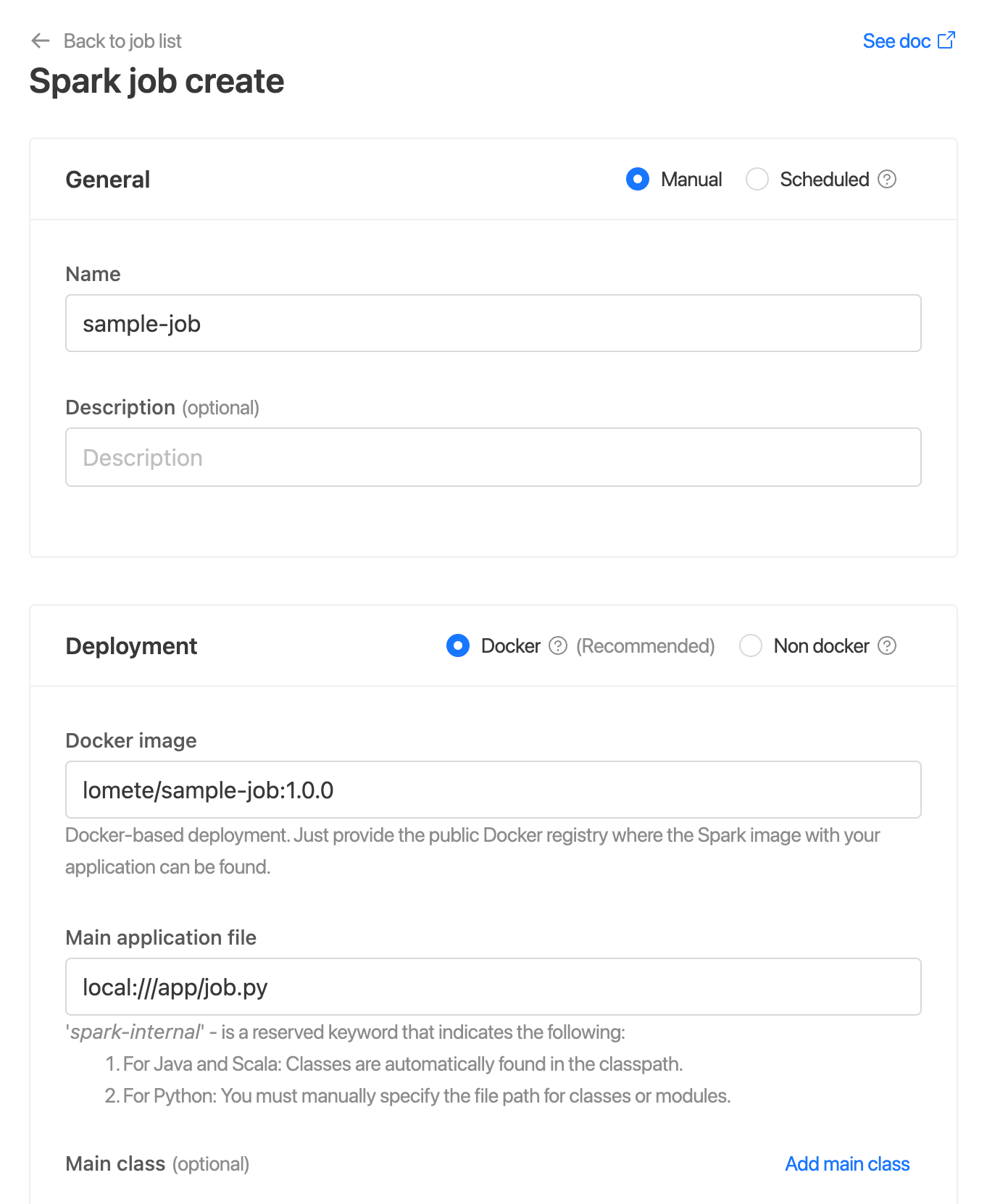
The template is the IOMETE Spark Application Configuration (short: Application Config) used to create runs. In programming language terms, you can think of it as a class, and runs are instances created from this class.
In this document, we'll cover all the available options for configuring a Spark Application in IOMETE.
Deployment Parameters
The Deployment Parameters consists of several fields that help specify various aspects of the Spark application deployment. Below is a list of the available fields:
- image: Container image for the driver and executors. If this field is provided, there is no need to specify the
sparkVersion. This is because the Spark distribution that comes with the provided image will be used. If this field is not provided but the Spark version is provided, IOMETE will detect the matching Docker image version and use that. If both fields are omitted, the default values will be used. - sparkVersion: Spark version to use. This field will be used only if
imagefield is omitted. If this field is provided and the image field is omitted, IOMETE will detect the matching Docker image version and use that. The default value for the Spark version is3.2.1, and the default Docker image isiomete/spark:3.2.1-latest. - mainApplicationFile: URI for the application file (jar, Python script, etc.). This field is also required and has no default value.
- mainClass: Main class for the application (Scala/Java only). This field is required for Java/Scala applications, but not for PySpark applications.
Example 1: A simple PySpark application deployment configuration.
{
"image": "iomete/sample-job:1.0.0",
"mainApplicationFile": "local:///app/job.py"
}
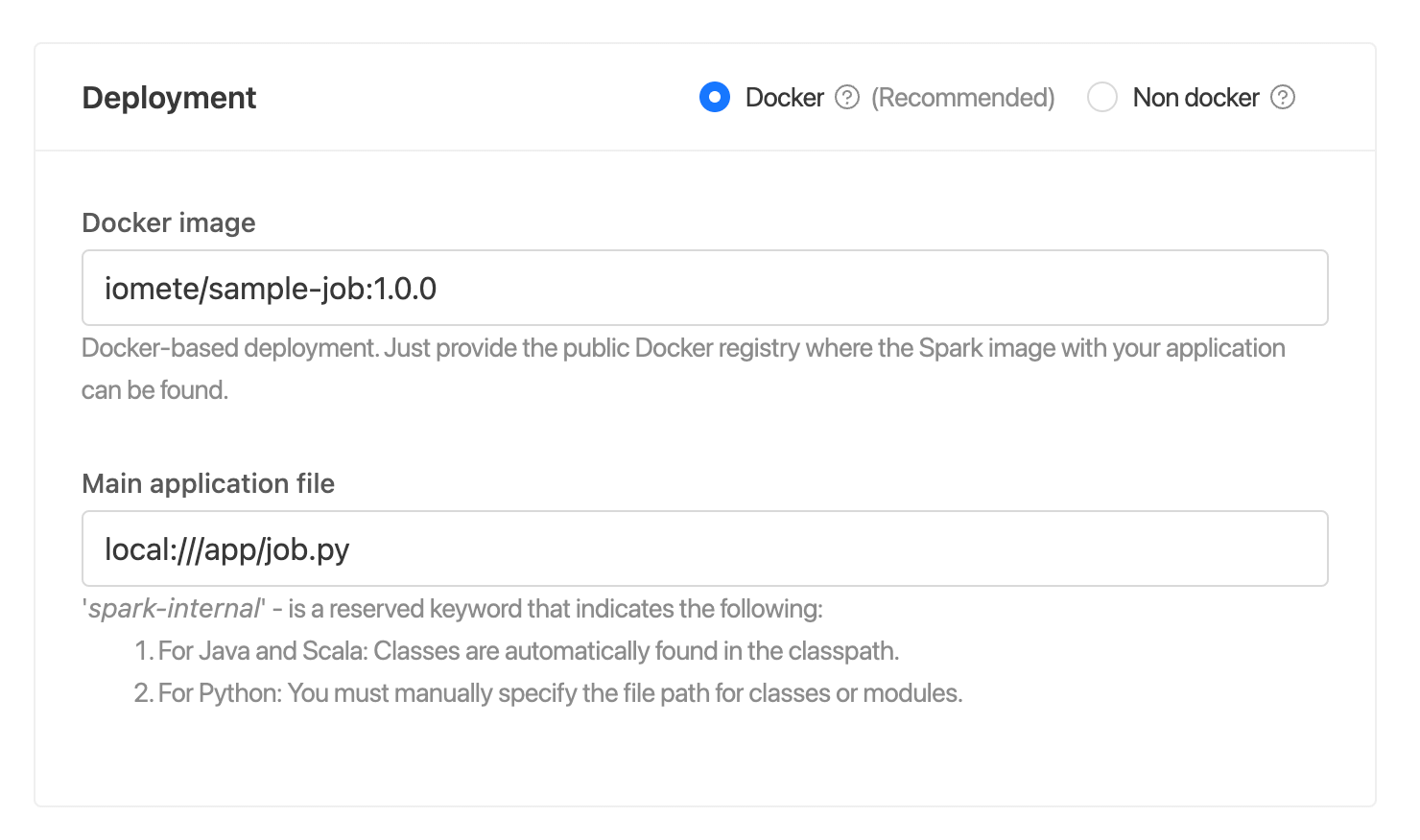
This configuration specifies that the image used for the driver and executors is iomete/sample-job:1.0.0. The mainApplicationFile field points to a Python script located at local:///app/job.py.
Note that the local:// URI scheme is used to indicate that the file is located on the local filesystem of the machine running IOMETE.
In addition, since this is a PySpark application, there's no need to specify the mainClass field.
Example 2: Deploying Java spark application
{
"sparkVersion": "3.2.1",
"mainClass": "org.apache.spark.examples.SparkPi",
"mainApplicationFile": "local:///opt/spark/examples/jars/spark-examples_2.12-3.2.1.jar"
}
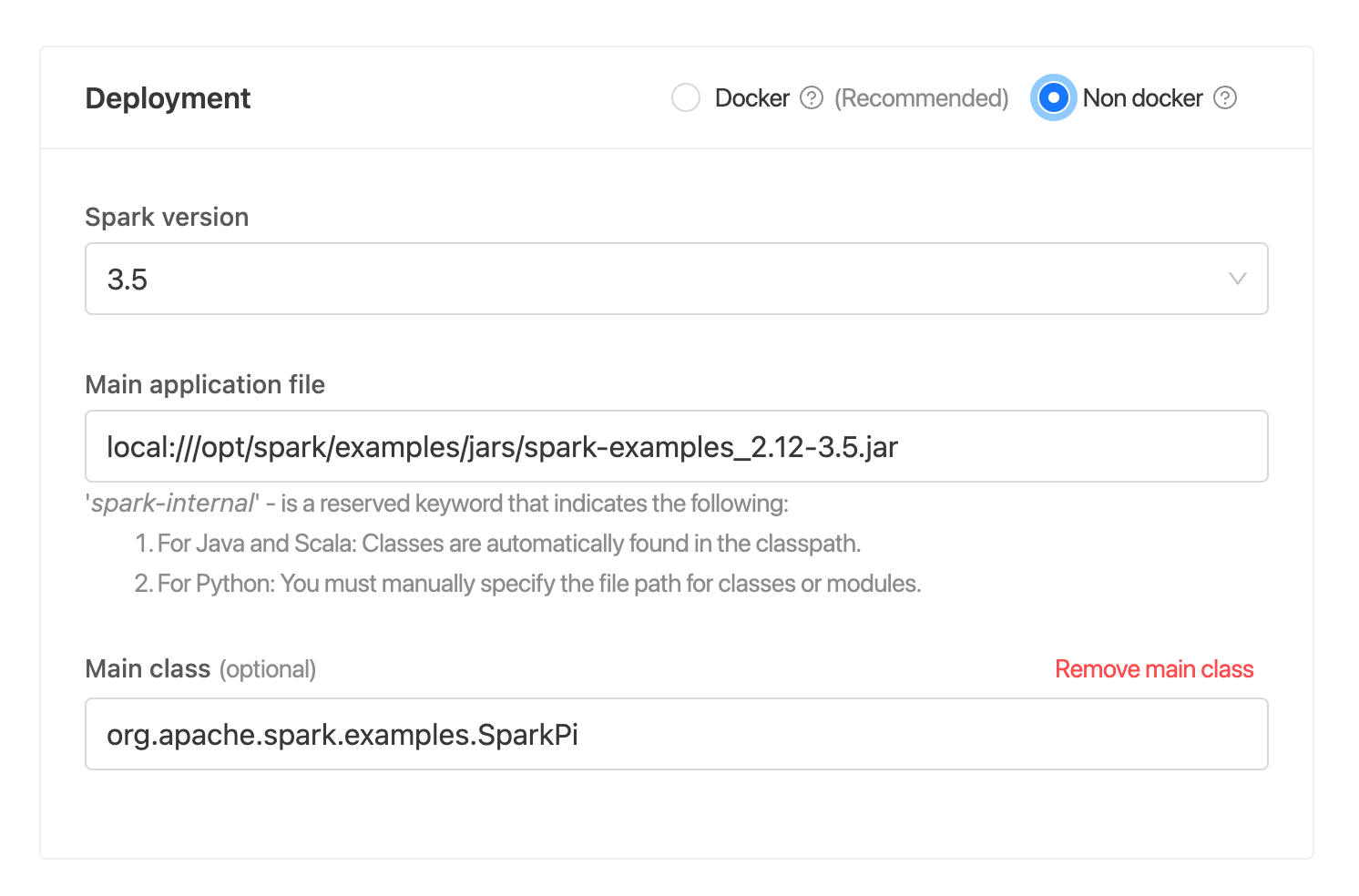
This configuration specifies that the Spark version is 3.2.1, and the application file is located at local:///opt/spark/examples/jars/spark-examples_2.12-3.2.1.jar. Additionally, it specifies the mainClass to be org.apache.spark.examples.SparkPi. The docker image and version will be resolved based the on the Spark version, which is iomete/spark:3.2.1-latest in this case.
Note that this configuration is for a Scala application, which requires a main class to be specified.
In this case, we are using the pre-built Spark example JAR file for calculating Pi (spark-examples_2.12-3.2.1.jar).
Docker Image
The IOMETE platform runs on top of Kubernetes. Thus, the spark job should be packaged as a Docker image.
If non-dockerized deployment is used, just specify the Spark Version. The platform will use the corresponding docker image, which has the Spark distribution. The application artifacts (jar, python file, and dependencies) should be uploaded to remote storage (S3, GCS, etc.) and specified in the Main Application File and Dependencies sections accordingly.
Mainly two different deployment options can be used:
- Docker-based deployment
- Non-docker deployment
Docker-based deployment
In this option, you create a docker image to package the Spark distribution and the Spark Job artifacts (jar, python file, and dependencies).
This is the recommended option.
💡 In your Dockerfile, use the IOMETE Spark Docker image as the base image. See the IOMETE Spark Docker Images for more information.
Example:
FROM iomete/spark-py:3.2.1.1
WORKDIR "/app"
# Reset to root to run installation tasks
USER 0
# add source code to the /app directory
COPY infra/requirements.txt job.py ./
COPY spark_conf/log4j.properties /opt/spark/iomete/log4j.properties
RUN pip install -r requirements.txt
# Specify the User that the actual main process will run as
ARG spark_uid=185
USER ${spark_uid}
Non-docker deployment You upload your Spark Job artifacts (jar, python file, and dependencies) to object storage (S3, GCS, etc.) and specify these files in the dependencies section. In that case, you just specify the docker image that contains the Spark Distribution version you want to use. See the IOMETE Spark Docker Images for more information.
Main Application File
The Main Application File is the path to the Spark application JAR/Python file.
The path must be a valid URI. The widely used URI schemes are:
local:///- A local file. If the application file is located in the Docker image, use this URI scheme. For example,local:///opt/spark/examples/jars/spark-examples_2.12-3.2.1-iomete.jar.s3a://- An S3 file. For example,s3a://my-bucket/spark-examples_2.12-3.2.1-iomete.jar
There is a special value spark-internal that can be used if the Jar file is already in the Spark Classpath. For example, if you want to run the SparkPi example, you can use spark-internal as the Main Application File. This will run the SparkPi example that is already in the Spark distribution.
Main Class
This option is only required for Java/Scala Spark Jobs. Not required for Python Spark Jobs.
The Main Class is the fully qualified name of the main class of the Spark application. This class will be searched in the classpath of the Spark application.
Example: org.apache.spark.examples.SparkPi
Driver and Executor Configuration
The instanceConfig field in IOMETE specifies the configuration for both the driver and executor instances of the Spark application. The field executorCount in instanceConfig specifies the number of executor instances, while the driver instance is always one.
For example, consider the following JSON config:
{
"instanceConfig": {
"driverType": "r6g.large",
"executorType": "r5d.xlarge",
"executorCount": 2
}
}

In this case, we're specifying that our Spark application should use a driver instance with type r6g.large, two executor instances with type r5d.xlarge, and an executor count of two. This means that our application will have one driver instance and two executor instances running concurrently.
Keep in mind that different instance types offer varying amounts of memory, CPU, and network capacity. Therefore, it's important to choose an appropriate instance type based on your workload requirements.
Configuration
IOMETE also provides a wide range of configuration options for controlling the behavior of the Spark application. These options include memory limits, environment variables, and user-defined parameters.


Passing Arguments
Passing arguments to a Spark application can be done through the args field in the Application Config. This field takes an array of strings, where each string represents an argument.
{
"args": ["arg1", "arg2"]
}
These arguments will be passed to the main function of the Spark application as command-line arguments.
Environment Variables
You can also specify environment variables for your Spark application using the envVars field of the Application Config. This field takes a JSON object with key-value pairs, where each key is the name of an environment variable and its value is the value to be assigned to it.
Here's an example env var config:
{
"envVars": {
"APP_ENV": "production"
}
}
In this case, we're specifying that our Spark application should have an environment variable named APP_ENV with a value of production. These environment variables can then be accessed within your Spark application just like any other environment variable.
Using environment variables in your Spark applications can help you keep sensitive information like API keys and database credentials out of your code. It also makes it easier to manage different configurations for different environments (e.g., development, staging, production) without having to modify your code.
Sensitive Environment Variables
In some cases, your Spark application may require sensitive information such as API keys or database credentials to be passed in as environment variables. However, storing these values in plain text can be a security risk.
Sensitive environment variables are values that you want to pass as environment variables to your Spark application, but you want to keep the value hidden. To keep sensitive environment variables secure, IOMETE allows you to add token, password, or secret as part of the environment variable key. These environment variables' values will be masked so they don't appear in plain text logs or output.
For example, let's say you have a sensitive API key for an external service that your Spark application needs to use. You can add this key as an environment variable named MYAPP_API_KEY and pass it to your Spark application. However, to keep the key secure, you can add the prefix SECRET_ to the key, so that the environment variable key becomes SECRET_MYAPP_API_KEY. IOMETE will automatically mask the value of this environment variable so that it does not appear in logs or output.
It's important to note that this feature only masks the value of the environment variable and not the key. Therefore, you should still avoid adding sensitive information to the key itself.
Here's an example:
{
"envVars": {
"APP_ENV": "production",
"DB_URL": "jdbc:mysql://localhost/mydatabase",
"DB_PASSWORD": "mysecretpassword",
"AWS_ACCESS_KEY_ID": "AKIAXXXXXXXXXXXXXXXX",
"AWS_SECRET_ACCESS_KEY": "mytopsecretkey"
}
}

Spark Configuration
To configure Spark, you can use the sparkConf field of the Application Config. The field takes a JSON object with the configuration key-value pairs.
For example, to set the spark.ui.port, spark.eventLog.enabled, and spark.eventLog.dir properties, use the following sparkConf field:
{
"sparkConf": {
"spark.ui.port": "4045",
"spark.eventLog.enabled": "true",
"spark.eventLog.dir": "hdfs://hdfs-namenode-1:8020/spark/spark-events"
}
}
Check out the Spark Configuration page for all the available configuration options.
Hadoop Configuration
To add Hadoop configuration, you can use the hadoopConf field of the Application Config. The field takes a JSON object with the configuration key-value pairs.
Example:
{
"hadoopConf": {
"fs.gs.project.id": "spark",
"fs.gs.system.bucket": "spark",
"google.cloud.auth.service.account.enable": true
}
}
Java System Options
In addition to Spark and Hadoop configuration, you can also specify Java system options using the javaOptions field of the Application Config. This is useful when you need to pass arguments to the JVM that runs your Spark application.
Java system options are specified as a single string containing one or more options separated by spaces. Here's an example:
{
"javaOptions": "-Dlog.level=INFO -XX:+UseG1GC"
}
In this case, we're specifying two Java system options: -Dlog.level=INFO, which sets the logging level to INFO, and -XX:+UseG1GC, which enables the G1 garbage collector.
These Java system options will be applied to all driver and executor instances of your Spark application.
You may need to use Java system options if you have custom memory requirements or if you need to enable additional debugging or profiling tools. For example, you might use the -Xmx option to increase the maximum heap size for your application, or use the -agentlib option to enable a profiling tool like JProfiler.
Keep in mind that incorrect use of Java system options can cause your application to fail or behave unexpectedly. Make sure you understand what each option does before adding it to your configuration.
Dependencies
Spark applications often require additional files, such as jars and data files, to run. These dependencies can be specified using the optional deps field of an Application Config. The field includes optional fields deps.jars and deps.files, which correspond to the --jars and --files options of the spark-submit script.
Example:
{
"deps": {
"jars": ["s3a://my-bucket/spark-jars/my-lib.jar"],
"files": [
"gs://spark-data/data-file-1.txt",
"s3a://my-bucket/data-file-2.txt"
]
}
}
It's also possible to specify additional jars to obtain from a remote repository by adding Maven coordinates to deps.packages. Conflicting transitive dependencies can be addressed by adding to the exclusion list with deps.excludePackages. Additional repositories can be added to the deps.repositories list. These directly translate to the spark-submit parameters --packages, --exclude-packages, and --repositories.
Note that each package in the packages list must be of the form groupId:artifactId:version, and each package in the excludePackages list must be of the form groupId:artifactId.
Here's an example using IOMETE to specify these parameters:
{
"deps": {
"repositories": [""],
"packages": ["com.example:some-package:1.0.0"],
"excludePackages": ["com.example:other-package"]
}
}

Python Support
Python support can be enabled by setting mainApplicationFile with the path to your python application. Also, you can specify additional python files to be added to the python path by adding them to deps.pyFiles.
Below is an example showing part of an Application Config with python:
{
"mainApplicationFile": "s3://my-bucket/my-app.py",
"deps": {
"pyFiles": [
"s3://my-bucket/py_container_checks.py",
"s3://my-bucket/python-dep.zip"
]
}
}
Lifecycle
Configuring Automatic Application Restart and Failure Handling
IOMETE supports automatic application restart with a configurable Restart Policy using the optional field restartPolicy. The following is an example of a sample RestartPolicy:
{
"restartPolicy": {
"type": "OnFailure",
"onFailureRetries": 3,
"onFailureRetryInterval": 10,
"onSubmissionFailureRetries": 5,
"onSubmissionFailureRetryInterval": 20
}
}
The valid types of restartPolicy include Never, OnFailure, and Always. Upon termination of an application, IOMETE determines if the application is subject to restart based on its termination state and the restartPolicy in the specification. If the application is subject to restart, IOMETE restarts it by submitting a new run.
For OnFailure, IOMETE further supports setting limits on the number of retries via the onFailureRetries and onSubmissionFailureRetries fields. Additionally, if the submission retries have not been reached, IOMETE retries submitting the application using a linear backoff with the interval specified by onFailureRetryInterval and onSubmissionFailureRetryInterval, which are required for both OnFailure and Always Restart Policy.
The old resources, like driver pod, UI service/ingress, etc., are deleted if they still exist before submitting the new run, and a new driver pod is created by the submission client, so effectively, the driver gets restarted.
Summary
In this document, we have covered the available options for configuring a Spark Application in IOMETE. We have seen how to specify the deployment parameters, driver and executor configuration, environment variables, Spark and Hadoop configurations, Java system options, dependencies, and automatic application restart and failure handling.
By using these configurations effectively, you can optimize your Spark applications for performance and scalability.
Full JSON Configuration Example
Here is an example of a complete JSON configuration that includes all the available options:
The following example is not a correct configuration and is only for demonstration purposes. It includes all available fields for reference, but in practice some fields may be omitted or left with default values depending on your specific use case.
{
"name": "sample-job1",
"template": {
"image": "iomete/sample-job:1.0.0",
"sparkVersion": "3.2.1",
"mainApplicationFile": "local:///app/job.py",
"mainClass": null,
"args": ["arg1", "arg2"],
"envVars": {
"APP_ENV": "production",
"DB_URL": "jdbc:mysql://localhost/mydatabase",
"SECRET_MYAPP_API_KEY": "mysecretapikey"
},
"sparkConf": {
"spark.ui.port": "4045",
"spark.eventLog.enabled": "true",
"spark.eventLog.dir": "hdfs://hdfs-namenode-1:8020/spark/spark-events"
},
"hadoopConf": {
"fs.gs.project.id": "spark",
"fs.gs.system.bucket": "spark",
"google.cloud.auth.service.account.enable": true
},
"javaOptions": "-Dlog.level=INFO -XX:+UseG1GC",
"deps": {
"jars": ["s3a://my-bucket/spark-jars/my-lib.jar"],
"files": [
"gs://spark-data/data-file-1.txt",
"s3a://my-bucket/data-file-2.txt"
],
"packages": ["com.example:some-package:1.0.0"],
"excludePackages": ["com.example:other-package"],
"repositories": [""],
"pyFiles": [
"s3://my-bucket/py_container_checks.py",
"s3://my-bucket/python-dep.zip"
]
},
"instanceConfig": {
"driverType": "r6g.large",
"executorType": "r5d.xlarge",
"executorCount": 2
},
"restartPolicy": {
"type": "OnFailure",
"onFailureRetries": 3,
"onFailureRetryInterval": 10,
"onSubmissionFailureRetries": 5,
"onSubmissionFailureRetryInterval": 20
}
}
}
This configuration specifies a PySpark application named sample-job1 that uses version 3.2.1 of Spark running on iomete/spark:3.2.1-latest. The main application file is located at local:///app/job.py, and takes two arguments (arg1 and arg2).
Several environment variables are defined, including sensitive information like database credentials and AWS access keys. Note that the SECRET_MYAPP_API_KEY environment variable is prefixed with SECRET_, which will mask its value so that it does not appear in logs or output.
The Spark configuration sets the UI port to 4045 and enables event logging to HDFS at /spark/spark-events, while the Hadoop configuration sets a key to value mapping for Hadoop config keys/values.
Java system options are specified using -Dlog.level=INFO -XX:+UseG1GC.
Dependencies include jars located at s3a://my-bucket/spark-jars/my-lib.jar and data files located at Google Cloud Storage bucket (gs://) or S3 bucket (s3a://). Additional packages can be obtained from a remote repository by adding Maven coordinates to deps.packages, and conflicts can be resolved by adding to the exclusion list with deps.excludePackages.
The instance configuration sets one driver instance with type r6g.large, two executor instances with type r5d.xlarge, and an executor count of two.
Finally, automatic application restart is enabled using a configurable Restart Policy that retries up to three times upon failure or five times upon submission failure with linear backoff intervals of ten seconds or twenty seconds respectively between each retry attempt.