Enterprise Catalog
Enterprise Catalog is a preview feature introduced in IOMETE v3.16.0. It is intended for evaluation and feedback — not for production use.
- Breaking changes may occur before general availability
- Please share your feedback with your IOMETE representative or open a ticket on our support portal
Overview
Enterprise Catalog is a format-agnostic data catalog that supports Avro, CSV, Iceberg, JSON, ORC, Parquet, and Text tables — with Delta Lake and Hudi support planned.
Traditional Spark setups rely on spark_catalog (the session catalog) which
uses Hive Metastore underneath. While Hive Metastore supports multiple
formats, it has significant limitations:
- Single namespace — All multi-format tables live in
spark_catalog; you cannot create additional multi-format catalogs - Legacy technology — Hive Metastore is aging infrastructure with known security vulnerabilities and performance bottlenecks
- Suboptimal Iceberg support — Forces users to create separate Iceberg REST Catalogs, fragmenting table management
- Scalability constraints — Performance degrades significantly with large table counts
Enterprise Catalog addresses these limitations by:
- Multiple catalog instances — Create as many multi-format catalogs as needed, each with isolated namespaces
- Modern architecture — Built on top of Iceberg REST Catalog with format-agnostic design, eliminating Hive Metastore dependencies
- Format unification — Manage Iceberg tables alongside flat files (Parquet, JSON, CSV, etc.) in a single catalog
- Auto-configuration — Simplified setup requiring only name and warehouse; connection properties and internal routing configured automatically
Enterprise Catalog is currently only accessible by IOMETE workloads: Lakehouses, Spark jobs, and Jupyter notebooks.
Architecture
Enterprise Catalog is built as a wrapper on top of the Iceberg REST Catalog:
- For Iceberg tables, it delegates to the underlying Iceberg REST Catalog infrastructure
- For other formats (Avro, CSV, JSON, ORC, Parquet, Text), it extends the catalog to register and query these formats alongside Iceberg tables
- Connection properties (REST endpoint, storage type, internal routing) are auto-configured — no manual S3 credentials or endpoint configuration required
This architecture means Enterprise Catalog inherits the reliability of Iceberg REST Catalog while extending format support beyond Iceberg. It currently uses the Spark Catalog V1 API, with V2 migration planned for a future release.
Supported Formats
| Format | Status |
|---|---|
| Avro | ✅ Available |
| CSV | ✅ Available |
| Iceberg | ✅ Available |
| JSON | ✅ Available |
| ORC | ✅ Available |
| Parquet | ✅ Available |
| Text | ✅ Available |
| Delta Lake | 🔜 Planned |
| Hudi | 🔜 Planned |
Creating an Enterprise Catalog
On the admin portal, locate Spark Catalogs on the sidebar (under Data Governance) and click + New Spark Catalog.
Select Enterprise Catalog from the Managed Catalogs section.
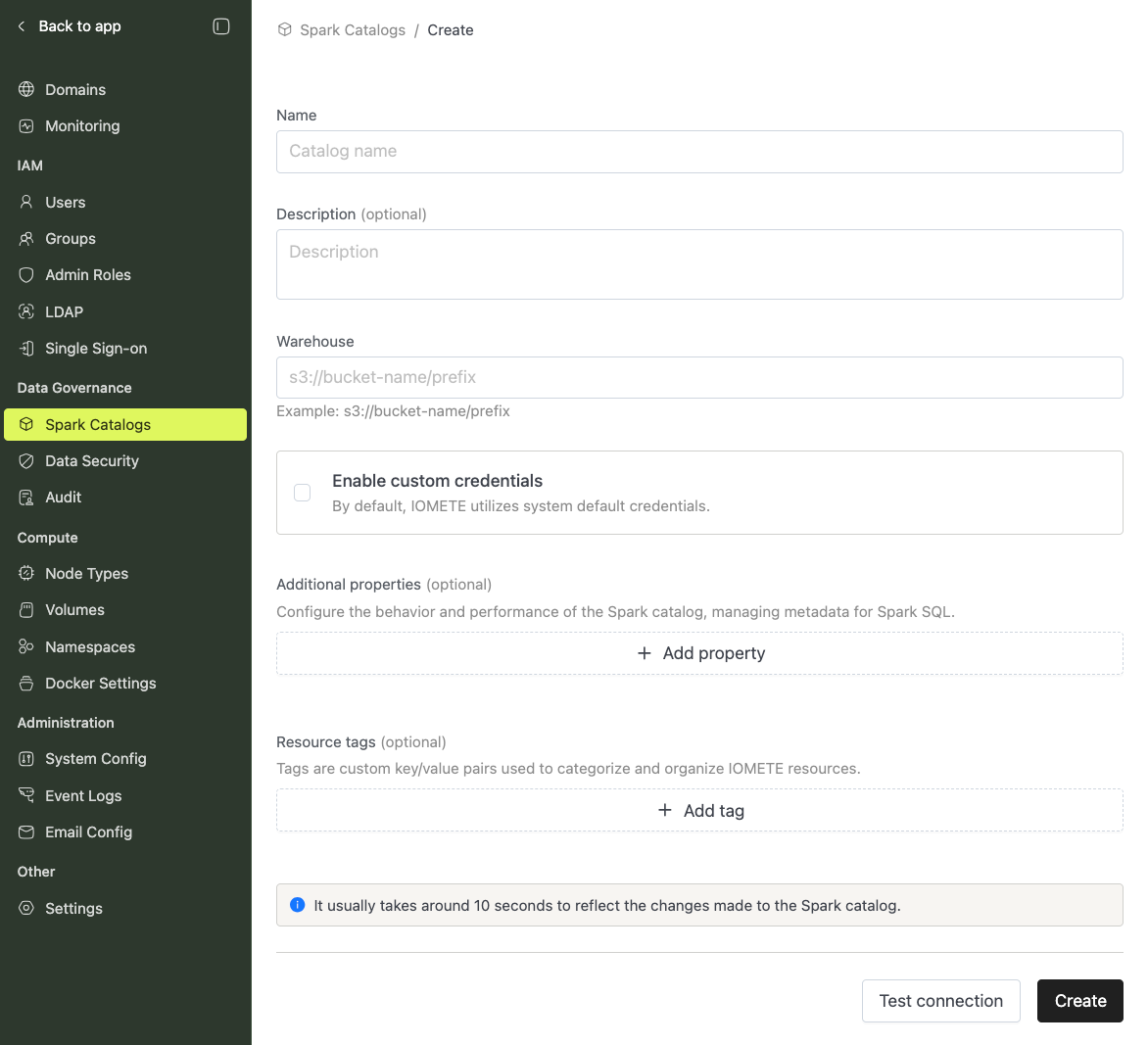
Provide the following:
- Name — A unique name for the catalog
- Warehouse — The S3-compatible warehouse URL for table storage
All other settings are automatically configured by the platform. Any values provided are treated as overrides — none are required.
Validating and Saving
Click Test Connection to validate connectivity and permissions, then click Create.
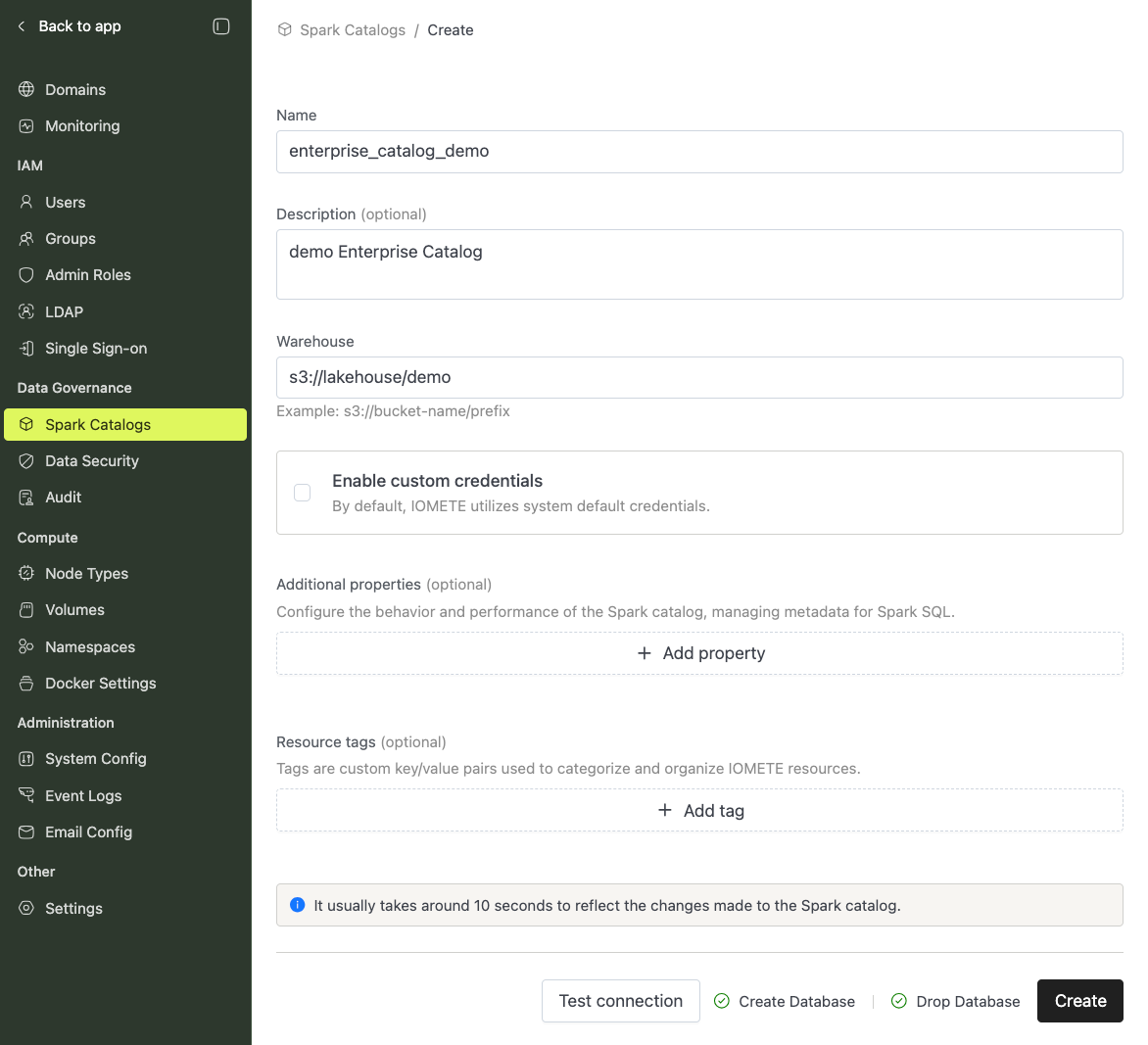
Due to caching, the catalog might take a few seconds to become available in the platform and on applications.
Current Features
- Multi-format read/write — Avro, CSV, Iceberg, JSON, ORC, Parquet, and Text tables in a single catalog
- Auto-configured connections — REST endpoint, storage type, and internal routing require no manual setup
- Simplified creation — Only name and warehouse required; no S3 credentials needed
- IOMETE workload access — Available to Lakehouses, Spark jobs, and Jupyter notebooks
Known Issues
The following issues are present in the current preview release and will be addressed in future releases:
- CSV table queries fail when
TBLPROPERTIEScollide with CSV option names — Providing table properties whose keys match CSV datasource option names causes queries to fail. For example,TBLPROPERTIES ('comment' = 'table description')producescomment cannot be more than one character. This happens because allTBLPROPERTIESare forwarded to the CSV datasource layer. Avoid setting properties whose keys match CSV option names — includingcomment,sep,quote,escape,header, andmultiLine— until this is resolved. - Non-Iceberg tables are treated as external tables — Regardless of how a table is created, all non-Iceberg tables are treated as external. This has the following implications:
UPDATE,DELETE,MERGE,TRUNCATE— These operations are not supported on non-Iceberg tablesPURGE— Dropping a table does not delete the underlying data files from storage- Table lifecycle behavior may differ from what is expected for managed tables
These are known limitations under active development. If you encounter additional issues, please open a ticket on our support portal or contact your IOMETE representative.
Planned Features
The following capabilities are under development for future releases:
- Spark Catalog V2 API migration — Currently uses V1 API; V2 will enable richer catalog operations
- External REST API access — Expose catalogs to external compute engines with token-based authentication
- Namespace & table-level ACLs — GRANT/REVOKE permissions via Data Security
- JDBC/ODBC discovery — Register catalogs for BI tool auto-discovery
- Hive Metastore migration utility — Migrate existing Hive-managed tables into Enterprise Catalog
- Delta Lake & Hudi support — Extend format coverage to include Delta Lake and Hudi tables
- Column-level lineage & tags — Track data flow and annotate columns with metadata
- Fine-grained privileges — Column-level access, row filters, and data masking
Catalog Comparison
spark_catalog (Hive Metastore) | Enterprise Catalog | Iceberg REST Catalog | |
|---|---|---|---|
| Formats | Avro, CSV, JSON, ORC, Parquet, Text. Iceberg (suboptimal) | Avro, CSV, JSON, ORC, Parquet, Text, Iceberg. Delta Lake & Hudi (planned) | Iceberg only |
| Multiple instances | ❌ Single session catalog only | ✅ Create multiple catalogs | ✅ Create multiple catalogs |
| Architecture | Legacy (Hive Metastore) | Modern (Iceberg REST-based) | Modern (Iceberg REST) |
| Setup | Pre-configured | Auto-configured (name + warehouse only) | Auto-configured when internal; manual S3 config for external access |
| External access | N/A (session catalog only) | Planned — currently internal only | REST API with token authentication |
| Access delegation | N/A | Planned | Credential vending & remote signing |
| Status | Production (legacy) | Preview | Production-ready |
Providing Feedback
Enterprise Catalog is in preview and we actively encourage you to try it out. Your feedback directly shapes its development — every issue reported, feature requested, or workflow shared helps us build a better product.
- Contact your IOMETE representative with questions, ideas, or issues
- Open a ticket on our support portal for technical support