A Comprehensive Guide to PySpark Joins
Joins are fundamental operations for combining data from multiple sources. PySpark provides different types of joins, including
- inner and cross joins
- outer joins (left, right, full)
- left semi and, left anti join
PySpark Join Syntax:
df1.join(df2, join_condition, join_type)
PySpark join type must be one of:
inner(default)crossouter,full,fullouter,full_outerleft,leftouter,left_outerright,rightouter,right_outersemi,leftsemi,left_semianti,leftanti,left_anti
Default join type is inner
| SQL Join Clause | PySpark Join Type | Description |
|---|---|---|
| INNER JOIN | inner | Returns all rows when there is at least one match in BOTH tables |
| CROSS JOIN | cross | Returns all rows from the left table multiplied by all rows from the right table (Cartesian product) |
| LEFT OUTER JOIN (a.k.a LEFT JOIN) | left, leftouter, left_outer | Returns all rows from the left table, and the matched rows from the right table |
| RIGHT OUTER JOIN (a.k.a RIGHT JOIN) | right, rightouter, right_outer | Returns all rows from the right table, and the matched rows from the left table |
| FULL OUTER JOIN | outer, full, fullouter, full_outer | Returns all rows when there is a match in ONE of the tables |
| LEFT SEMI JOIN | semi, leftsemi, left_semi | Returns all rows from the left table for which there is at least one match in the right table |
| LEFT ANTI JOIN | anti, leftanti, left_anti | Returns all rows from the left table for which there is no match in the right table |
Spark doesn't support right semi and right anti joins.
In this guide, we will use tables, datasets, and data frames interchangeably. They all have the same meaning in this context.
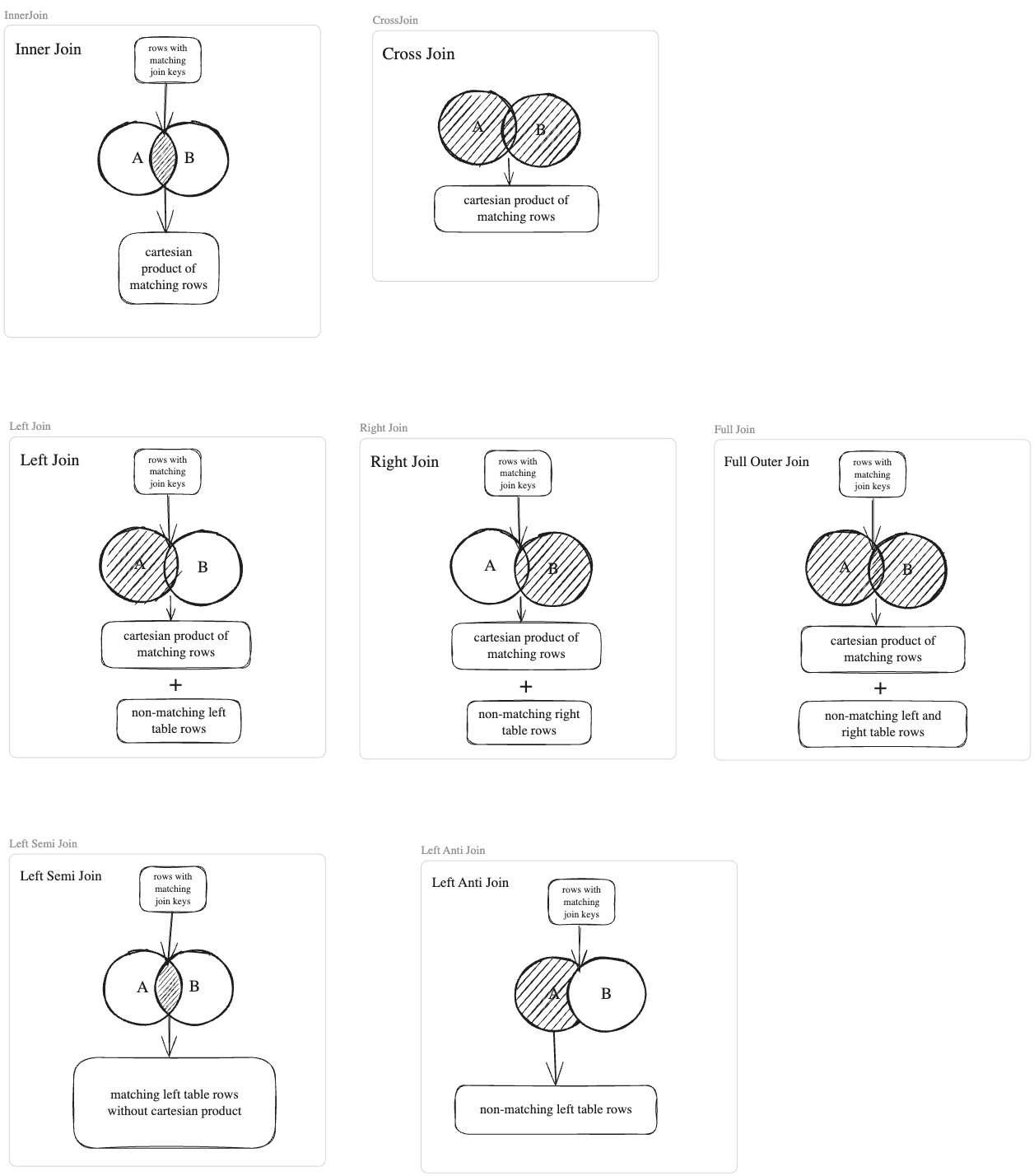
Inner Join
In an Inner Join between two DataFrames (let's call them A and B), the operation matches each row from A with each row from B where the join condition is true. Only the matching rows from both DataFrames are included in the result.
It's one of the most commonly used joins, allowing you to correlate related data across different sources.
Let's use two simple tables to demonstrate how an INNER JOIN works:
Example Tables
Table A (Employees):
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | John | 1 |
| 2 | Emma | 2 |
| 3 | Raj | null |
| 4 | Nina | 4 |
Table B (Departments):
| dept_id | dept_name |
|---|---|
| 1 | HR |
| 2 | Tech |
| 3 | Marketing |
| null | Temp |
Some records have null values in the dept_id column to demonstrate null handling.
Objective
We aim to match employees with their respective departments based on a common dept_id. Our goal is to retrieve a combined view of employees and their department names.
Expected output:
| emp_id | emp_name | dept_id | dept_name |
|---|---|---|---|
| 1 | John | 1 | HR |
| 2 | Emma | 2 | Tech |
Rows with null in dept_id are expected to be excluded from the result as nulls do not match with any value, including other nulls.
PySpark Inner Join Example
Here's how you might set up the DataFrames and perform the Inner Join in PySpark:
from pyspark.sql import SparkSession
# Initialize a SparkSession
spark = SparkSession.builder.appName("inner_join_example").getOrCreate()
# Create DataFrames for Employees and Departments
data_employees = [(1, "John", 1), (2, "Emma", 2), (3, "Raj", None), (4, "Nina", 4)]
data_departments = [(1, "HR"), (2, "Tech"), (3, "Marketing"), (None, "Temp")]
columns_employees = ["emp_id", "emp_name", "dept_id"]
columns_departments = ["dept_id", "dept_name"]
df_employees = spark.createDataFrame(data_employees, columns_employees)
df_departments = spark.createDataFrame(data_departments, columns_departments)
# Perform INNER JOIN
# since `inner` is the default join type, we can omit it
df_joined = df_employees.join(df_departments, df_employees.dept_id == df_departments.dept_id)
# Show the result
df_joined.show()
Spark SQL Equivalent of the Inner Join:
SELECT *
FROM employees e
INNER JOIN departments d
ON e.dept_id = d.dept_id;
The result of df_joined.show() would include rows with matching dept_id values from both tables:
+------+--------+-------+-------+---------+
|emp_id|emp_name|dept_id|dept_id|dept_name|
+------+--------+-------+-------+---------+
| 1| John| 1| 1| HR|
| 2| Emma| 2| 2| Tech|
+------+--------+-------+-------+---------+
As you've seen in the example, you cannot match null values with other null values. Therefore, rows with null values as the join key are excluded from the result.
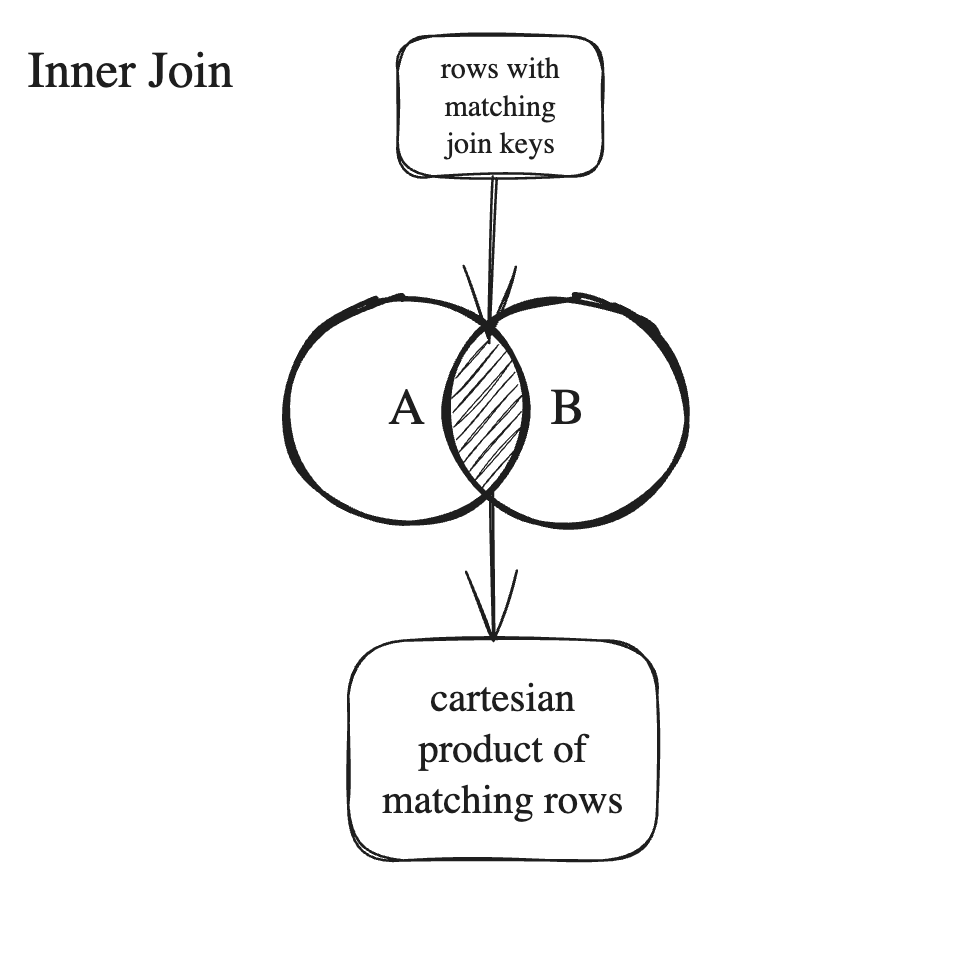
Cross Join
A Cross Join in PySpark is a join operation that returns the Cartesian product of two DataFrames. In other words, it combines every row from the left DataFrame with every row from the right DataFrame, resulting in a large, unfiltered result.
In a Cross Join:
- All rows from the left DataFrame are combined with all rows from the right DataFrame.
- There is no join condition; it simply generates all possible combinations.
Cross Joins should be used with caution as they can generate a massive number of rows and can be computationally expensive.
PySpark Cross Join Syntax
df1.crossJoin(df2)
Example tables
Let's illustrate a Cross Join using two simple tables:
Table A (Employees):
| emp_id | emp_name |
|---|---|
| 1 | John |
| 2 | Emma |
| 3 | Raj |
Table B (Departments):
| dept_id | dept_name |
|---|---|
| A | HR |
| B | Tech |
Objective
Our goal is to generate a Cartesian product of employees and departments, creating a result that pairs every employee with every department.
PySpark Cross Join Example
Here's how you might set up the DataFrames and perform the Cross Join in PySpark:
from pyspark.sql import SparkSession
# Initialize a SparkSession
spark = SparkSession.builder.appName("cross_join_example").getOrCreate()
# Create DataFrames for Employees and Departments
data_employees = [(1, "John"), (2, "Emma"), (3, "Raj")]
data_departments = [("A", "HR"), ("B", "Tech")]
columns_employees = ["emp_id", "emp_name"]
columns_departments = ["dept_id", "dept_name"]
df_employees = spark.createDataFrame(data_employees, columns_employees)
df_departments = spark.createDataFrame(data_departments, columns_departments)
# Perform Cross Join
df_cross_joined = df_employees.crossJoin(df_departments)
# Show the result
df_cross_joined.show()
Spark SQL Equivalent of Cross Join:
SELECT
*
FROM
employees e
CROSS JOIN
departments d;
The result of df_cross_joined.show() would include every possible combination of employees and departments:
+------+--------+-------+---------+
|emp_id|emp_name|dept_id|dept_name|
+------+--------+-------+---------+
| 1| John| A| HR|
| 1| John| B| Tech|
| 2| Emma| A| HR|
| 2| Emma| B| Tech|
| 3| Raj| A| HR|
| 3| Raj| B| Tech|
+------+--------+-------+---------+
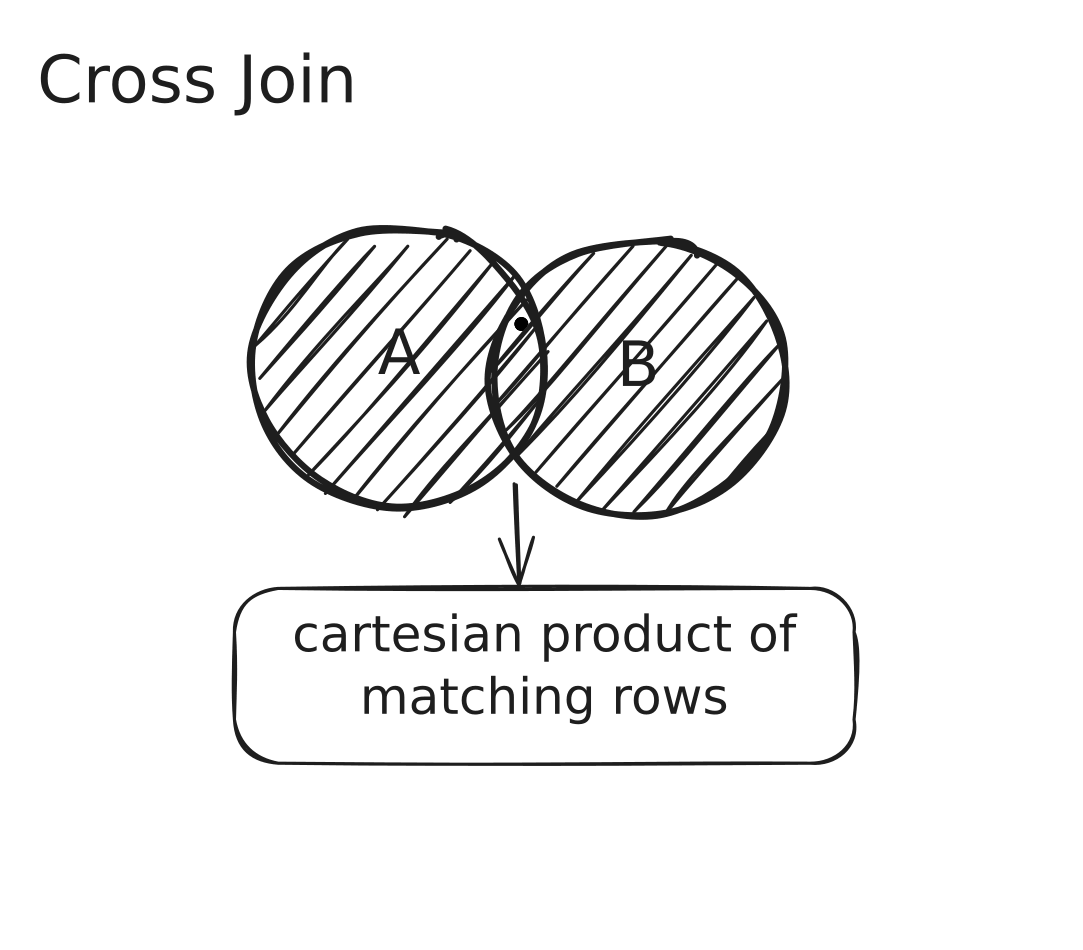
Left Outer Join
In a Left Outer Join (also called Left Join) between two DataFrames (let's call them A and B), the operation first finds all the rows from DataFrame A and then attempts to match each row from A with rows from B where the join condition is true.
In a Left Outer Join:
- All rows from the left DataFrame are included in the result.
- Only the rows from the right DataFrame that match the join condition are included.
- If there's no match in the right DataFrame, null values are used to fill in the columns from the right DataFrame.
Left Outer Join is especially useful when you want to include all records from one dataset and only the matching records from another dataset.
Syntax:
df1.join(df2, join_condition, "left") # "leftouter", "left_outer" can be used
Example tables
Let's illustrate a Left Outer Join using two simple tables:
Table A (Employees):
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | John | 1 |
| 2 | Emma | 2 |
| 3 | Raj | null |
| 4 | Nina | 4 |
Table B (Departments):
| dept_id | dept_name |
|---|---|
| 1 | HR |
| 2 | Tech |
| 3 | Marketing |
| null | Temp |
Objective
Our goal is to match employees with their respective departments based on a common dept_id. The expected output should provide a combined view of employees and their department names, including those employees with null dept_id.
Expected output:
| emp_id | emp_name | dept_id | dept_id | dept_name |
|---|---|---|---|---|
| 1 | John | 1 | 1 | HR |
| 2 | Emma | 2 | 2 | Tech |
| 3 | Raj | null | null | null |
| 4 | Nina | 4 | null | null |
Order of rows can be different in the actual output. Output is sorted for better readability.
PySpark Left Outer Join Example
Here's how you might set up the DataFrames and perform the Left Outer Join in PySpark:
from pyspark.sql import SparkSession
# Initialize a SparkSession
spark = SparkSession.builder.appName("left_outer_join_example").getOrCreate()
# Create DataFrames for Employees and Departments
data_employees = [(1, "John", 1), (2, "Emma", 2), (3, "Raj", None), (4, "Nina", 4)]
data_departments = [(1, "HR"), (2, "Tech"), (3, "Marketing"), (None, "Temp")]
columns_employees = ["emp_id", "emp_name", "dept_id"]
columns_departments = ["dept_id", "dept_name"]
df_employees = spark.createDataFrame(data_employees, columns_employees)
df_departments = spark.createDataFrame(data_departments, columns_departments)
# Perform Left Outer Join
df_joined = df_employees.join(df_departments, df_employees.dept_id == df_departments.dept_id, "left")
# Show the result
df_joined.show()
Spark SQL Equivalent of Left Join:
SELECT
*
FROM
employees e
LEFT JOIN
departments d ON e.dept_id = d.dept_id;
The result of df_joined.show() would include all rows from the df_employees DataFrame and matching rows from the df_departments DataFrame, with null values in the dept_name column for rows without a match in the right DataFrame.
|emp_id|emp_name|dept_id|dept_id|dept_name|
+------+--------+-------+-------+---------+
| 1| John| 1| 1| HR|
| 2| Emma| 2| 2| Tech|
| 3| Raj| null| null| null| -> null values for non-matching rows
| 4| Nina| 4| null| null| -> dep_id=4 doesn't exist in departments table, thus null values for right table columns
+------+--------+-------+-------+---------+
As you've seen in the example, null dept_id doesn't match null in the right DataFrame (df_departments). Therefore, those rows are not matched and null values are used to fill in the columns from the right DataFrame.
Right Outer Join
In a Right Outer Join (also called Right Join) between two DataFrames (let's call them A and B), the operation first finds all the rows from DataFrame B and then attempts to match each row from B with rows from A where the join condition is true.
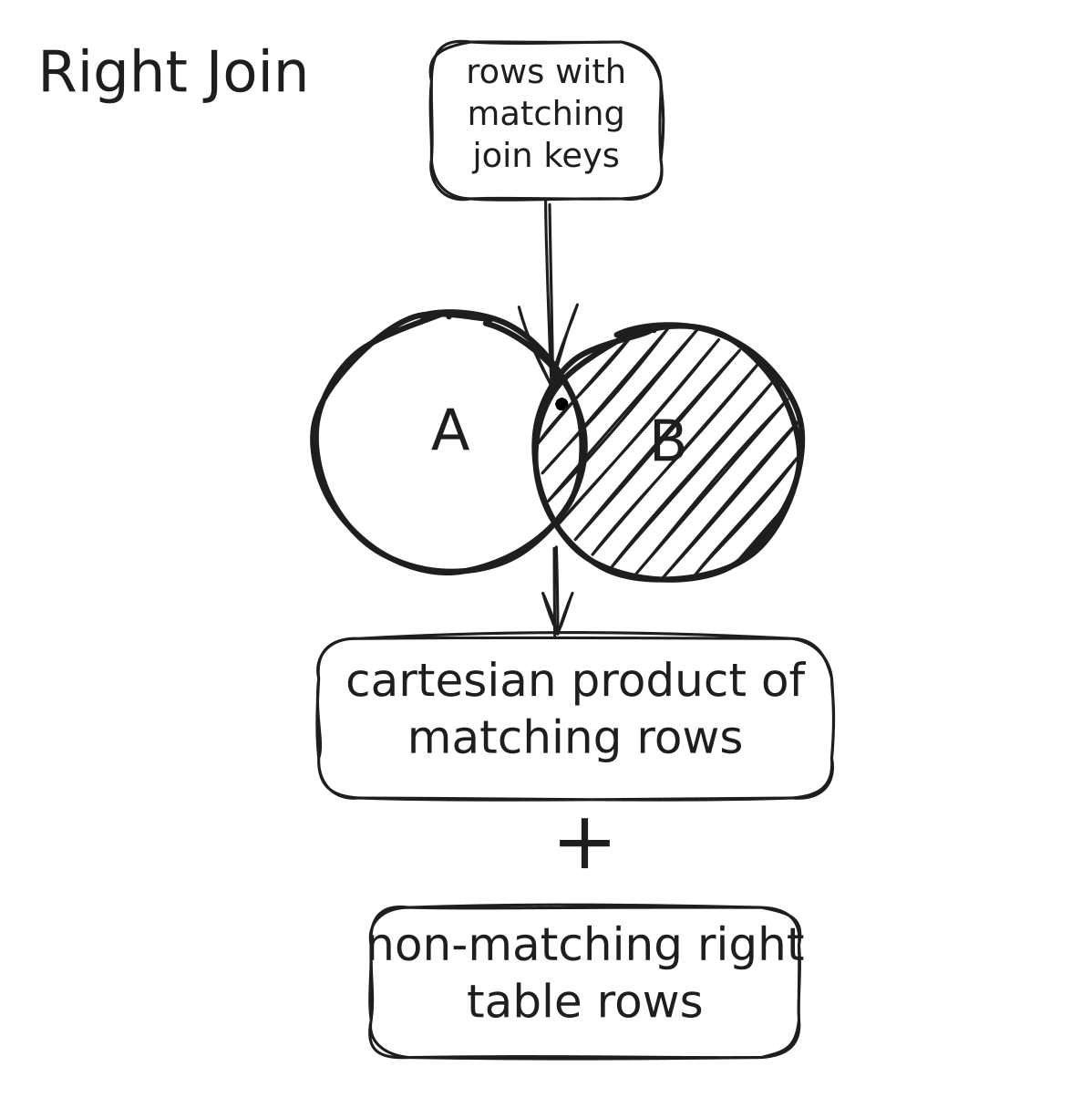
In a Right Outer Join:
- All rows from the right DataFrame are included in the result.
- Only the rows from the left DataFrame that match the join condition are included.
- If there's no match in the left DataFrame, null values are used to fill in the columns from the left DataFrame.
Right Outer Join is almost identical to Left Outer Join, except that it starts with the right DataFrame instead of the left DataFrame.
Syntax:
df1.join(df2, join_condition, "right") # "rightouter", "right_outer" can be used
Example tables
Let's illustrate a Right Outer Join using two simple tables:
Table A (Employees):
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | John | 1 |
| 2 | Emma | 2 |
| 3 | Raj | null |
| 4 | Nina | 4 |
Table B (Departments):
| dept_id | dept_name |
|---|---|
| 1 | HR |
| 2 | Tech |
| 3 | Marketing |
| null | Temp |
Objective
Our goal is to match employees with their respective departments. We ignore employees who don't have a matching dept_id.
Expected output:
| emp_id | emp_name | dept_id | dept_id | dept_name |
|---|---|---|---|---|
| 1 | John | 1 | 1 | HR |
| 2 | Emma | 2 | 2 | Tech |
| null | null | null | 3 | Marketing |
| null | null | null | null | Temp |
Output is sorted for better readability.
PySpark Right Outer Join Example
Here's how you might set up the DataFrames and perform the Right Outer Join in PySpark:
from pyspark.sql import SparkSession
# Initialize a SparkSession
spark = SparkSession.builder.appName("right_outer_join_example").getOrCreate()
# Create DataFrames for Employees and Departments
data_employees = [(1, "John", 1), (2, "Emma", 2), (3, "Raj", None), (4, "Nina", 4)]
data_departments = [(1, "HR"), (2, "Tech"), (3, "Marketing"), (None, "Temp")]
columns_employees = ["emp_id", "emp_name", "dept_id"]
columns_departments = ["dept_id", "dept_name"]
df_employees = spark.createDataFrame(data_employees, columns_employees)
df_departments = spark.createDataFrame(data_departments, columns_departments)
# Perform Right Outer Join
df_joined = df_employees.join(df_departments, df_employees.dept_id == df_departments.dept_id, "right")
# Show the result
df_joined.show()
Spark SQL Equivalent of Right Join:
SELECT
*
FROM
employees e
RIGHT JOIN
departments d ON e.dept_id = d.dept_id;
The result of df_joined.show() would include all rows from the df_departments DataFrame and matching rows from the df_employees DataFrame, with null values in the emp_id and emp_name columns for rows without a match in the left DataFrame.
+------+--------+-------+-------+---------+
|emp_id|emp_name|dept_id|dept_id|dept_name|
+------+--------+-------+-------+---------+
| 1| John| 1| 1| HR|
| 2| Emma| 2| 2| Tech|
| null| null| null| 3|Marketing| -> no employees in Marketing department
| null| null| null| null| Temp| -> null values do not match with other null values, therefore no matching rows
+------+--------+-------+-------+---------+
The Right Outer Join retains all rows from the right DataFrame (df_departments) and includes matching rows from the left DataFrame (df_employees) while filling in null values for non-matching rows.
As you've seen in the example, null dept_id doesn't match null in the left DataFrame (df_employees). Therefore, those rows are not matched and null values are used to fill in the columns from the left DataFrame.
Full Outer Join
In a Full Outer Join (also known as a Full Join), the operation combines the results of both Left and Right Outer Joins. This join type merge rows from two DataFrames (let's call them A and B) based on a join condition. Unlike Left or Right Joins that prioritize one DataFrame, the Full Outer Join treats both sides equally.
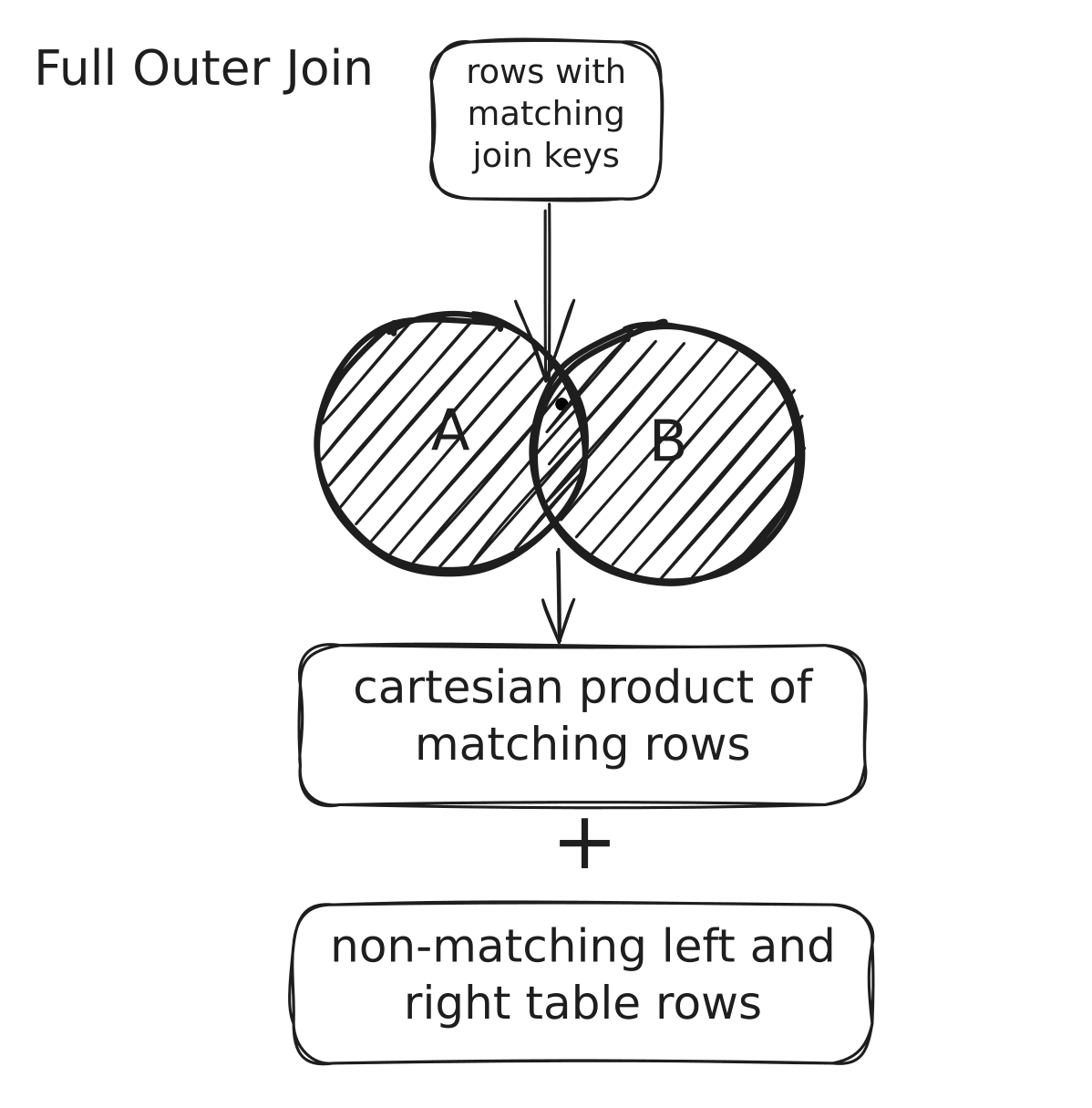
In a Full Outer Join:
- All rows from both the left DataFrame (A) and the right DataFrame (B) are included in the result.
- If there's a match between the DataFrames based on the join condition, the corresponding rows are combined into a single row in the result.
- If there's no match for a row in DataFrame A, the result will contain null values for columns from DataFrame B, and vice versa.
In simple terms, Full Outer Join = Left Outer Join + Right Outer Join
Syntax:
df1.join(df2, join_condition, "full") # "outer", "fullouter", "full_outer" can also be used
Example tables
Let's illustrate a Full Outer Join using two simple tables:
Table A (Employees):
| emp_id | emp_name | dept_id |
|---|---|---|
| 1 | John | 1 |
| 2 | Emma | 2 |
| 3 | Raj | null |
| 4 | Nina | 4 |
Table B (Departments):
| dept_id | dept_name |
|---|---|
| 1 | HR |
| 2 | Tech |
| 3 | Marketing |
| null | Temp |
Objective
Our goal is to match employees with their respective departments based on a common dept_id.
The expected output should provide a combined view of employees and their department names, including non-matching rows from both DataFrames.
Expected output:
| emp_id | emp_name | dept_id | dept_id | dept_name |
|---|---|---|---|---|
| 1 | John | 1 | 1 | HR |
| 2 | Emma | 2 | 2 | Tech |
| 3 | Raj | null | null | null |
| 4 | Nina | 4 | null | null |
| null | null | null | null | Temp |
| null | null | null | 3 | Marketing |
Output is sorted for better readability.
PySpark Full Outer Join Example
Here's how you might set up the DataFrames and perform the Full Outer Join in PySpark:
from pyspark.sql import SparkSession
# Initialize a SparkSession
spark = SparkSession.builder.appName("full_outer_join_example").getOrCreate()
# Create DataFrames for Employees and Departments
data_employees = [(1, "John", 1), (2, "Emma", 2), (3, "Raj", None), (4, "Nina", 4)]
data_departments = [(1, "HR"), (2, "Tech"), (3, "Marketing"), (None, "Temp")]
columns_employees = ["emp_id", "emp_name", "dept_id"]
columns_departments = ["dept_id", "dept_name"]
df_employees = spark.createDataFrame(data_employees, columns_employees)
df_departments = spark.createDataFrame(data_departments, columns_departments)
# Perform Full Outer Join
df_joined = df_employees.join(df_departments, df_employees.dept_id == df_departments.dept_id, "outer")
# Show the result
df_joined.show()
Spark SQL Equivalent of Full Outer Join:
SELECT
*
FROM
employees e
FULL OUTER JOIN
departments d ON e.dept_id = d.dept_id;
The result of df_joined.show() would include all rows from both the df_employees and df_departments DataFrames, with null values in the columns for rows without a match in the respective DataFrame.
+------+--------+-------+-------+---------+
|emp_id|emp_name|dept_id|dept_id|dept_name|
+------+--------+-------+-------+---------+
| 1| John| 1| 1| HR| -> matched row
| 2| Emma| 2| 2| Tech| -> matched row
| 3| Raj| null| null| null| -> employees included in the result, but no matching department (null `dept_id` on employees table)
| 4| Nina| 4| null| null| -> employees included in the result, but no matching department
| null| null| null| null| Temp| -> departments included in the result, but no matching employee (null `dept_id` on departments table)
| null| null| null| 3|Marketing| -> departments included in the result, but no matching employee
+------+--------+-------+-------+---------+
As you see in the example above, null values do not match with other null values. Therefore, rows with null values as the join key are not matched.
Left Semi Join
Left Semi Join in PySpark is an operation used to filter a DataFrame based on the keys present in another DataFrame. It's essentially a way to narrow down a dataset by keeping only the rows that have a corresponding match in another dataset.
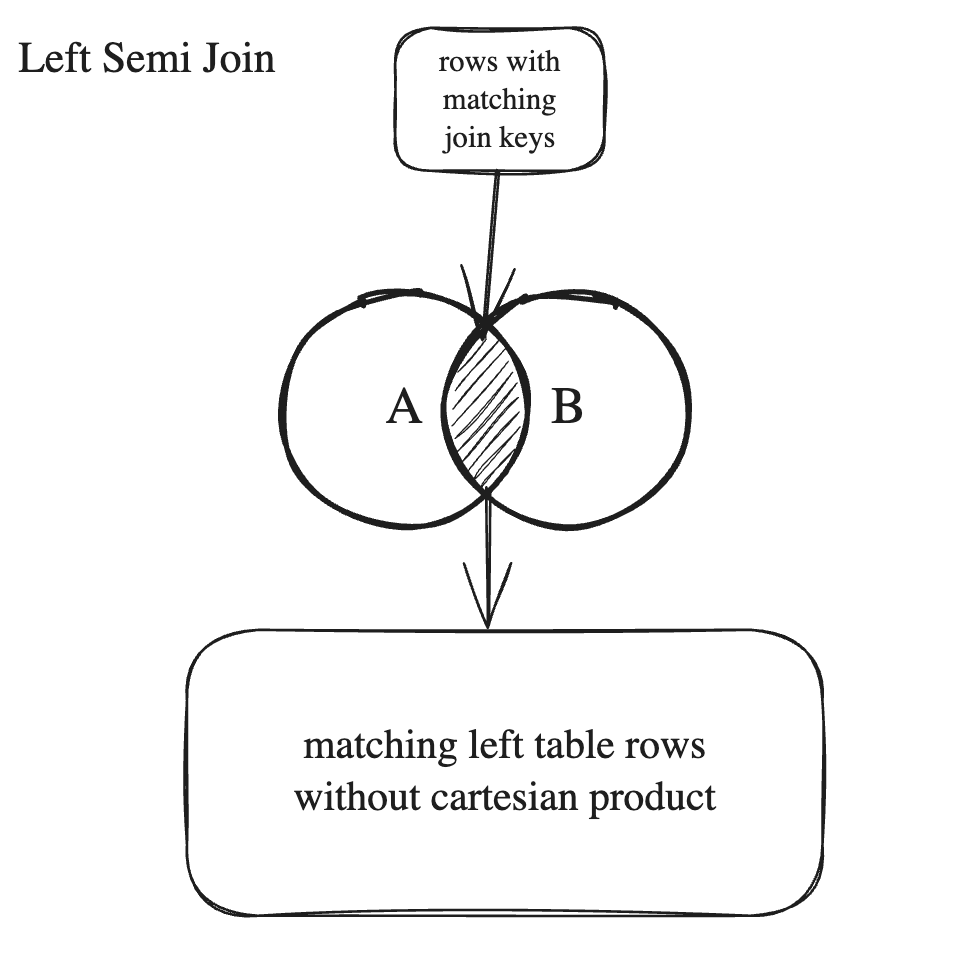
In a Left Semi Join between two datasets (let's call them A and B), the join returns all the rows from the left dataset (A) that have a corresponding match in the right dataset (B). It's the opposite of a Left Anti Join, which returns rows that do not have a match.
Let's create an example using two simple tables to demonstrate how a Left Semi Join works in PySpark:
Example Tables
Table A (Users):
| id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
| 4 | David |
| null | Eve |
Table B (Purchases):
| user_id | item |
|---|---|
| 1 | Book |
| 2 | Pen |
| 5 | Notebook |
| null | Pencil |
Some records have null values to demonstrate null handling.
In this scenario:
- Table A lists users with a unique
id. - Table B records purchases made by users, linked by
user_id.
Objective
We want to find out which users have made purchases. We expect to identify Alice (1) and Bob (2) as users who appear in both the users table and the purchases table.
Expected output:
+---+-----+
| id| name|
+---+-----+
| 1|Alice|
| 2| Bob |
+---+-----+
User Eve (null) is not included because null values do not match with any other value, including another null.
PySpark Left Semi Join Example
Here's how you might set up the data and perform the join:
from pyspark.sql import SparkSession
# Initialize a SparkSession
spark = SparkSession.builder.appName("left_semi_join_example").getOrCreate()
# Create DataFrames for Users and Purchases
data_users = [(1, "Alice"), (2, "Bob"), (3, "Charlie"), (4, "David")]
data_purchases = [(1, "Book"), (2, "Pen"), (5, "Notebook")]
columns_users = ["id", "name"]
columns_purchases = ["user_id", "item"]
df_users = spark.createDataFrame(data_users, columns_users)
df_purchases = spark.createDataFrame(data_purchases, columns_purchases)
# Perform Left Semi Join
df_purchasers = df_users.join(df_purchases, df_users.id == df_purchases.user_id, "left_semi")
# Show the result
df_purchasers.show()
Spark SQL Equivalent:
SELECT
*
FROM
users u
LEFT SEMI JOIN
purchases p ON u.id = p.user_id;
In this code:
df_usersrepresents Table A (Users).df_purchasesrepresents Table B (Purchases).- The
left_semijoin is used to find all users who have a correspondingidin the purchases table.
The result of df_purchasers.show() would be:
+---+-----+
| id| name|
+---+-----+
| 1|Alice|
| 2| Bob |
+---+-----+
As you've seen in the example, you cannot match null values with other null values. Therefore, rows with null values as the join key are excluded from the result.
Pros:
- Performance: Generally faster than other joins as it only needs to check for the existence of keys without needing to shuffle and join all corresponding data.
- Simplicity: The result is straightforward, containing only rows from the left DataFrame that have matches in the right DataFrame.
Cons:
- Less Intuitive: The concept might be less intuitive for those used to SQL joins, as it doesn't return a combined result set.
Left Anti Join
Left Anti Join in PySpark is a powerful tool for finding non-matching records between two datasets.
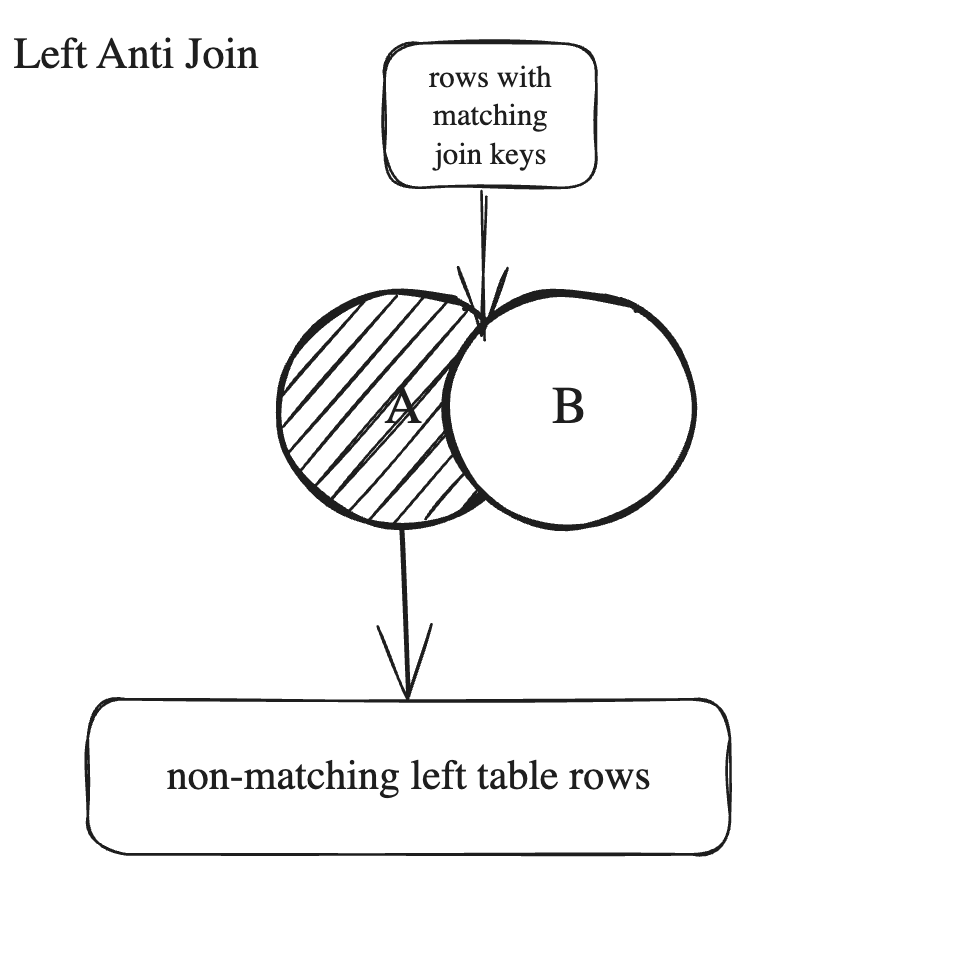
Consider two datasets (let's call them A and B). The join returns all the rows from the left dataset (A) that do not have a match in the right dataset (B).
This join is the opposite of a Left Semi Join, which returns rows that do have a match.
Let's create an example using two simple tables to demonstrate how a Left Anti Join works in PySpark.
Example Tables
Table A (Users):
| id | name |
|---|---|
| 1 | Alice |
| 2 | Bob |
| 3 | Charlie |
| 4 | David |
| null | Eve |
Table B (Purchases):
| user_id | item |
|---|---|
| 1 | Book |
| 2 | Pen |
| 5 | Notebook |
| null | Pencil |
Some records have null values to demonstrate null handling.
In this example:
- Table A is a list of users with a unique
idfor each user. - Table B records purchases made by users, referenced by
user_id.
Objective
We want to find out which users have not made any purchases.
In this example, we expect the result only to include Charlie (3) and David (4), as they are the only users who do not have a matching id in the purchases table. In other words, Charlie and David have not made any purchases, as their IDs do not appear in the purchases table.
| id | name |
|---|---|
| 3 | Charlie |
| 4 | David |
| null | Eve |
The result also includes Eve (null) because nulls do not match with any other value, including other nulls.
PySpark Left Anti Join Example
Here's how you might set up the data and perform the join:
from pyspark.sql import SparkSession
# Initialize a SparkSession
spark = SparkSession.builder.appName("left_anti_join_example").getOrCreate()
# Create DataFrames for Users and Purchases
data_users = [(1, "Alice"), (2, "Bob"), (3, "Charlie"), (4, "David")]
data_purchases = [(1, "Book"), (2, "Pen"), (5, "Notebook")]
columns_users = ["id", "name"]
columns_purchases = ["user_id", "item"]
df_users = spark.createDataFrame(data_users, columns_users)
df_purchases = spark.createDataFrame(data_purchases, columns_purchases)
# Perform Left Anti Join
df_non_purchasers = df_users.join(df_purchases, df_users.id == df_purchases.user_id, "left_anti")
# Show the result
df_non_purchasers.show()
Spark SQL Equivalent:
SELECT
*
FROM
users u
LEFT ANTI JOIN
purchases p ON u.id = p.user_id;
In the code:
df_usersrepresents Table A (Users).df_purchasesrepresents Table B (Purchases).- The
left_antijoin is used to find all users who do not have a matchingidin the purchases table.
As you've seen in the example, even though there's a null in the purchases table, nulls do not match with other nulls in standard join operations. Therefore, Eve is also listed as not having made a purchase.
Best Practices for PySpark Joins
1. Understand Your Data
- Pre-Inspect Data: Familiarize yourself with the data, its size, distribution, and the columns you plan to join on. Understanding the nature of your data can help in choosing the most efficient join type and strategy.
- Check for Duplicates: Ensure that the keys you're joining on don't have unexpected duplicates, which can cause inflated results and performance issues.
2. Optimize Data Size
- Filter Early: Apply filters to reduce the size of DataFrames before joining. Smaller DataFrames require less time and memory to join.
- Select Necessary Columns: Only select the columns needed for analysis before joining to reduce data shuffle.
3. Manage Skewness
- Detect Skew: Identify if your data is skewed, meaning some keys have significantly more data than others. Skewness can lead to unequal distribution of data and can severely impact join performance.
- Handle Skew: If skew is detected, consider using techniques like salting or broadcasting smaller tables to minimize its impact.
4. Use Broadcast Joins for Small Tables
- Broadcast Small DataFrames: If one of your DataFrames is small enough, use a broadcast join to send it to all nodes. This avoids shuffling large DataFrames across the network.
from pyspark.sql.functions import broadcastdf_large.join(broadcast(df_small), join_condition)
5. Choose the Right Join Type
- Appropriate Join Type: Use the join type that suits your data and requirements. For instance, if you only need matching rows, consider using an inner join; if you need to retain all rows from one DataFrame, consider using an outer join.
6. Partitioning and Clustering
- Effective Partitioning: Ensure your DataFrames are partitioned effectively before joining. Partitioning on the join key can reduce shuffling.
- Clustering: If possible, cluster your data on the join key. Clustering can significantly speed up join operations as related data is physically stored together.
7. Monitor and Tune
- Examine Execution Plans: Use
.explain()to understand the physical and logical plan Spark is using to execute your join. Look for opportunities to reduce shuffles and stages. - Tune Spark Configuration: Adjust Spark configurations like
spark.sql.shuffle.partitionsto better suit your job's requirements and available cluster resources.
8. Avoid Cartesian Joins
- Be Cautious with Cross Joins: Only use cross joins when absolutely necessary, as they can produce an extensive number of rows and significantly degrade performance.
9. Test and Iterate
- Performance Testing: Test your joins with different configurations and on subsets of your data to find the most efficient approach.
- Iterative Optimization: Performance tuning is often iterative. Continuously monitor, test, and adjust your strategy as your data and requirements evolve.
FAQ for PySpark Joins
Q1: What is the difference between inner and outer joins in PySpark?
A1: An inner join returns rows that have matching values in both tables, while outer joins (left, right, or full) include non-matching rows from one or both tables, filling in with nulls for missing values.
Q2: When should I use a cross join?
A2: Use a cross join when you need to combine every row of one DataFrame with every row of another, resulting in a Cartesian product. Be cautious, as this can result in a significantly large number of rows and may affect performance.
Q3: Can I join more than two DataFrames at a time in PySpark?
A3: Yes, you can chain multiple join operations to combine more than two DataFrames. However, consider the impact on performance and readability, and ensure the join conditions are correctly specified.
Q4: How does PySpark handle null values in join conditions?
A4: PySpark, like most SQL systems, treats nulls as unknown. Therefore, nulls in join conditions do not match with anything, including other nulls, resulting in rows being excluded from the join result unless using a full outer join.
Q5: What are some best practices for optimizing join performance in PySpark?
A5: To optimize join performance, consider strategies like broadcasting smaller DataFrames, filtering data before joining, and ensuring DataFrames are partitioned and clustered appropriately for the join keys.
Q6: What is the difference between left semi and left anti joins?
A6: A left semi join returns all rows from the left DataFrame that have a match in the right DataFrame, essentially filtering the left DataFrame. A left anti join, on the other hand, returns only the rows from the left DataFrame that do not have a match in the right DataFrame.
Q7: Are there limitations to the size of DataFrames I can join in PySpark?
A7: While PySpark is designed to handle large datasets, the practical limitations depend on your cluster's resources and configuration. Large joins may require significant computation and memory, so it's crucial to optimize where possible.
Q8: Can I perform SQL-style joins directly in PySpark SQL?
A8: Yes, PySpark SQL supports SQL-style syntax for joins, allowing you to write your join operations as you would in a standard SQL query.
Q9: How do I handle duplicate column names after a join?
A9: You can alias columns before the join or use DataFrame select methods to rename columns after the join to avoid conflicts with duplicate names.
Glossary for PySpark Joins
DataFrame
DataFrame: A distributed collection of data organized into named columns, conceptually equivalent to a table in a relational database. DataFrames can be manipulated using both SQL and standard Python-like operations.
Join
Join: An operation in relational databases and PySpark that combines rows from two or more DataFrames based on a related column between them.
Inner Join
Inner Join: A type of join that returns rows from both DataFrames where the join condition is true. It only returns matching rows.
Outer Join
Outer Join: A type of join that returns all rows from one or both DataFrames where there is a match. Depending on the type (left, right, or full), non-matching rows are filled with null values.
Left Outer Join
Left Outer Join: A join that returns all rows from the left DataFrame and matched rows from the right DataFrame. Non-matching rows from the right DataFrame are filled with nulls.
Right Outer Join
Right Outer Join: A join that returns all rows from the right DataFrame and the matched rows from the left DataFrame. Non-matching rows from the left DataFrame are filled with nulls.
Full Outer Join
Full Outer Join: A join that returns all rows from both the left and right DataFrames. Rows that do not match on either side are filled with nulls.
Cross Join
Cross Join: A join operation that returns the Cartesian product of the rows from the DataFrames involved. It combines each row of the first DataFrame with every row of the second DataFrame.
Left Semi Join
Left Semi Join: A join that returns all rows from the left DataFrame that have a corresponding match in the right DataFrame. It's used for filtering rather than combining DataFrames.
Left Anti Join
Left Anti Join: A join that returns all rows from the left DataFrame that do not have a corresponding match in the right DataFrame. It's useful for identifying non-matching entries.
Cartesian Product
Cartesian Product: The result of a cross join, where each row from one DataFrame is combined with each row from another DataFrame, resulting in every possible combination of rows.
SparkSession
SparkSession: The entry point to programming Spark with the DataFrame and Dataset API. It's used to create DataFrames, register DataFrames as tables, and execute SQL over tables, among other functions.
Broadcast Join
Broadcast Join: A type of join in Spark where the smaller DataFrame is sent to every node containing partitions of the larger DataFrame for more efficient join operations. It's beneficial for small to medium-sized DataFrames.
Partitioning
Partitioning: The process of dividing a large DataFrame into smaller pieces (partitions) that can be processed in parallel. Effective partitioning is crucial for optimizing join operations in distributed computing.