File Streaming Job
The File Streaming Job continuously ingests files from object storage into an Iceberg table using Spark Structured Streaming. Point it at a source directory, or an SQS queue that notifies on new files, and it appends new files to the destination table on a fixed trigger interval.
- Version:
1.0.1 - Source: View on GitHub
File Formats
- CSV
- JSON
- Amazon S3 with SQS notifications (
s3-sqs), recommended for large or fast-growing buckets. See Amazon S3 with SQS.
Installation
Marketplace
Open Job Templates and click Marketplace. Find the file-streaming-job card, click the ⋮ menu, and select Deploy.
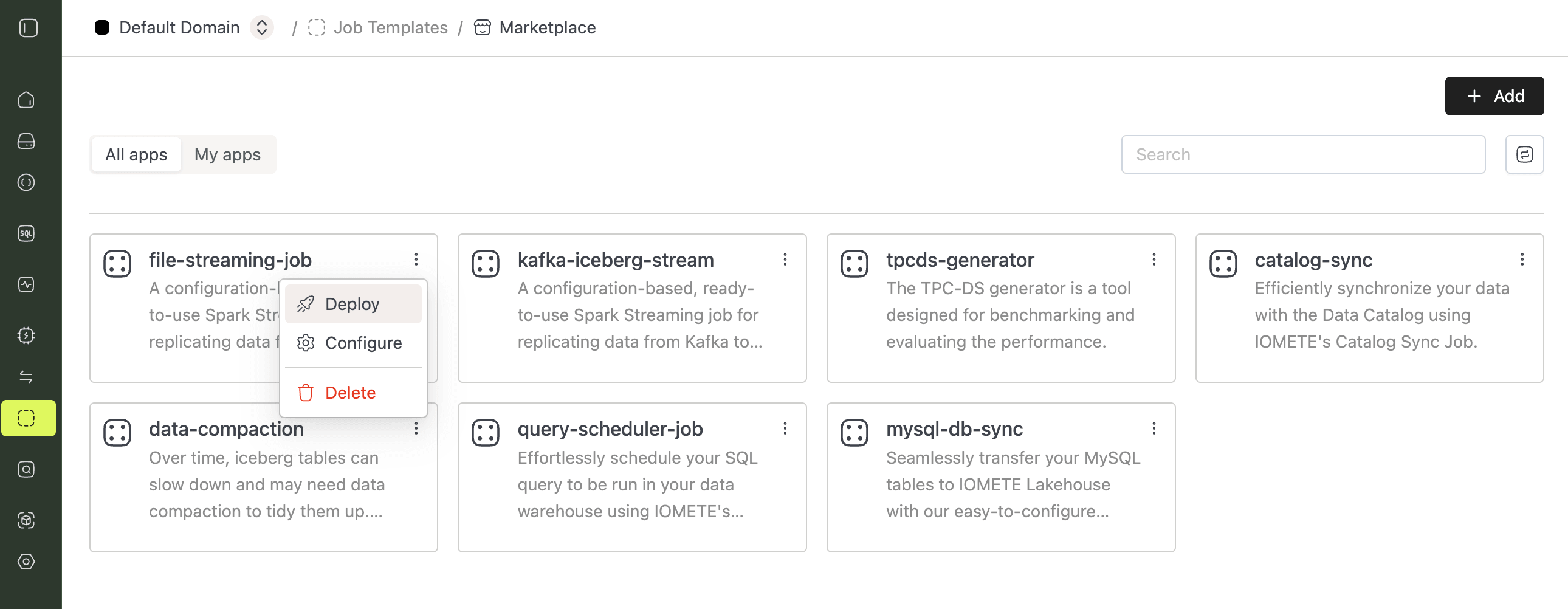
The Marketplace template opens a pre-filled Create New Job form. Review the source path and destination table in the config file (see Configuration) and update the values for your environment.
Manual Setup
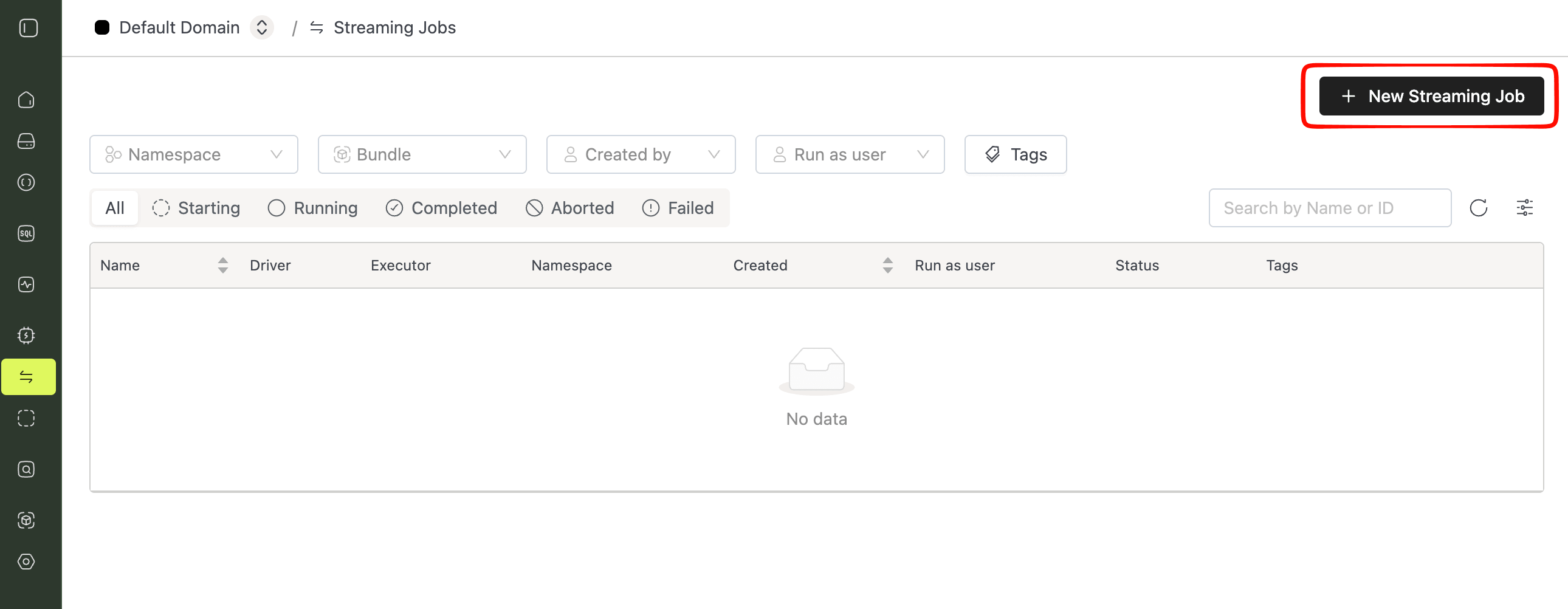
Open Streaming Jobs in the sidebar and click New Streaming Job if you do not use the Marketplace flow.
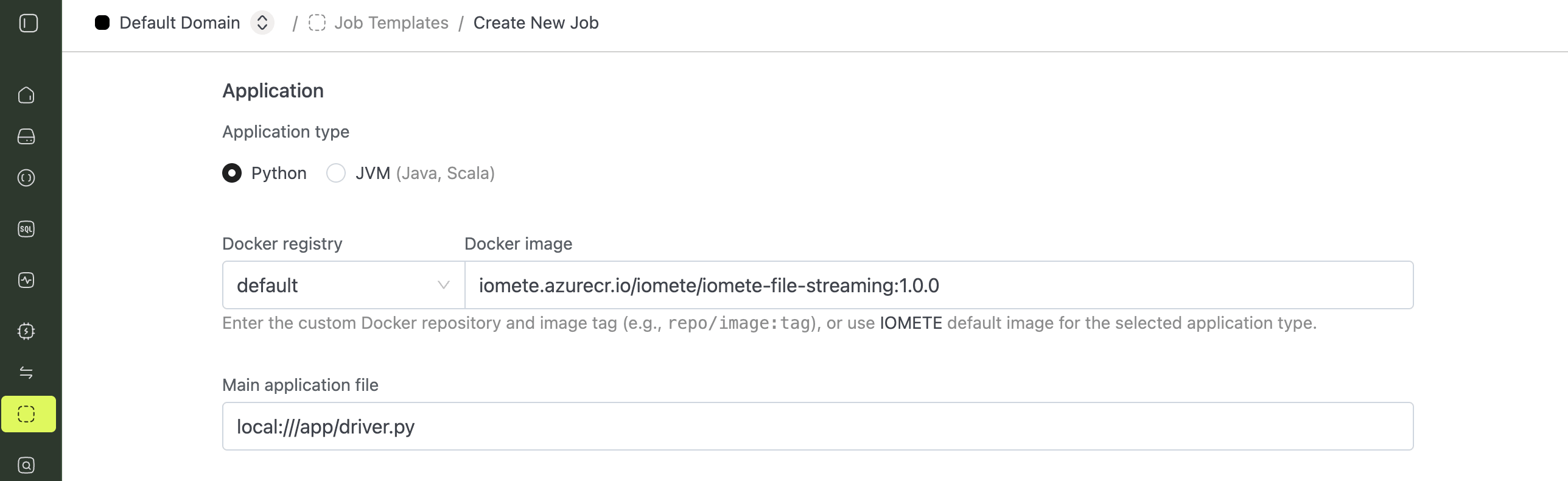
1. Name and Application
- Name: any name you like, for example
file-streaming-job - Application type:
Python - Docker image:
iomete.azurecr.io/iomete/iomete-file-streaming:1.0.1(replace with the latest version) - Main application file:
local:///app/driver.py
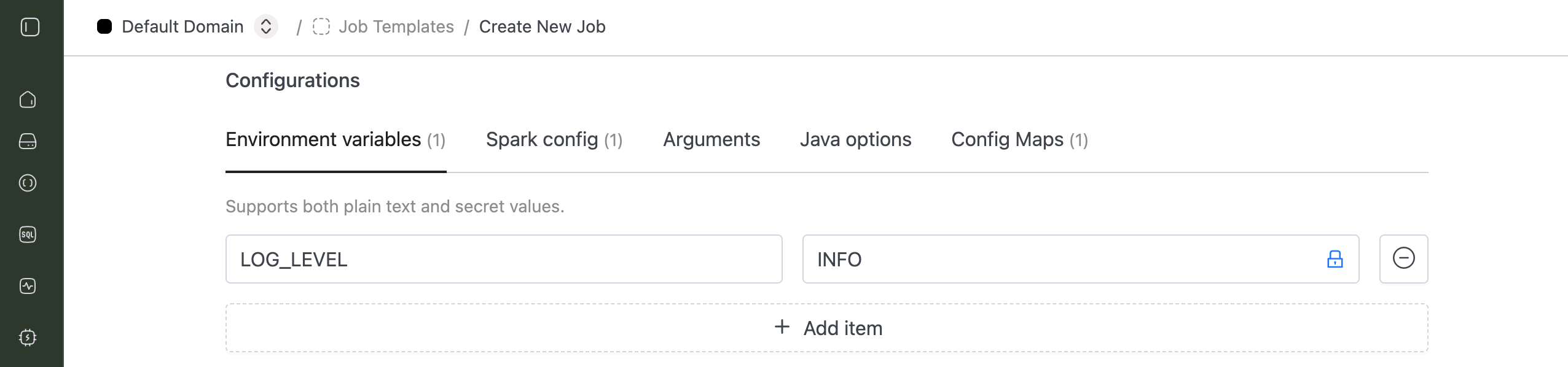
2. Environment Variables
LOG_LEVEL:INFOorERROR
You can also use environment variables to store sensitive values, such as passwords or secrets, and reference them in your config file using the ${DB_PASSWORD} syntax.
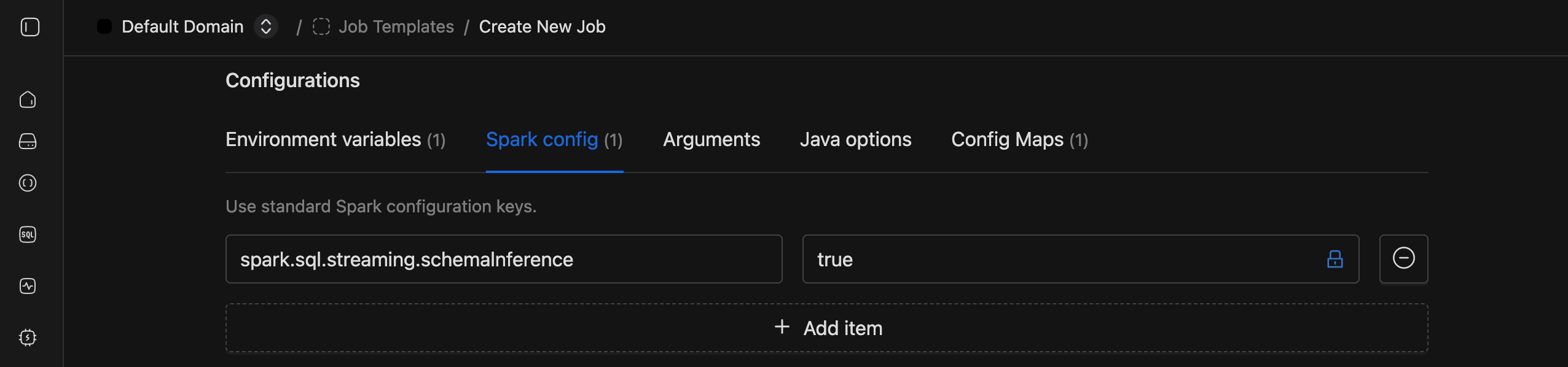
3. Spark Config
spark.sql.streaming.schemaInference:true
Set this when the config file doesn't provide an explicit schema for CSV. JSON and s3-sqs sources always need an explicit schema regardless of this setting. See Schema.

4. Config File
Expand Configurations, select the Config Maps tab, click Add config, and paste the HOCON template below. See Configuration for what each field does.
{
source: {
file: {
format: csv,
header: true,
path: "s3a://bucket/path_to_csv_files/",
max_files_per_trigger: 1,
latest_first: false,
max_file_age: "7d"
}
}
destination: {
schema: default,
table: csv_file_stream,
partitions: []
}
processing_time: {
interval: 30,
unit: seconds # minutes
}
}
5. Instance Resources
Pick driver and executor instance types that fit your data volume.
Click Create to save the job.
Configuration
The config file is HOCON. It declares the source, the destination table, and the streaming trigger interval.
Source File
| Field | Description |
|---|---|
format | File format to read: csv or json (still used when source.queue is set, to tell the job how to parse the notified files). See Amazon S3 with SQS. |
header | Whether the CSV files include a header row (ignored when source.queue is set). |
path | Source directory path, including the filesystem scheme, for example s3a://bucket/path_to_csv_files/ (ignored when source.queue is set). |
max_files_per_trigger | Maximum number of new files to process per streaming trigger. |
latest_first | Whether to process the latest files first when there is a backlog (ignored when source.queue is set). |
max_file_age | Maximum age of files the stream considers, for example 7d. |
filename_only | Optional. Detect new files by filename only instead of full path. Only enable this if filenames are unique across the entire source; otherwise files with the same name in different folders are treated as duplicates and skipped. |
Destination
| Field | Description |
|---|---|
schema | Destination schema (database). |
table | Destination table. |
partitions | Optional. Destination partition columns. |
Processing Time
| Field | Description |
|---|---|
interval | Streaming trigger interval. |
unit | Trigger interval unit: seconds or minutes. |
Schema
CSV can infer its schema from the file (set spark.sql.streaming.schemaInference: true in Spark config) or use an explicit schema. JSON and s3-sqs sources always require an explicit schema; the job fails at startup with Schema must be defined. if one isn't provided.
Add schema under source to define one explicitly:
source: {
schema: [
{ name: channel, type: string },
{ name: context, type: struct, properties: [
{ name: library, type: struct, properties: [
{ name: name, type: string },
{ name: version, type: string }
]}
]},
{ name: received_at, type: timestamp }
]
file: { ... }
}
Supported type values:
stringint(orbigint/integer)doublebooleandatetimestamp(ordate-time/time)array(orlist)struct, for nested fields, with its ownproperties
Amazon S3 with SQS
Listing a source directory on every trigger gets expensive as a bucket grows. If an SQS queue is subscribed to S3 object-created notifications for the bucket, point the job at the queue instead of the directory.
Add queue under source. When queue is present, it takes over as the read path: the job still uses source.file.format to know how to parse the notified files, but source.file.path, header, and latest_first go unused.
source: {
queue: {
URL: "https://sqs.eu-central-1.amazonaws.com/{account_number}/{queue_name}"
fetch_interval_seconds: 2
log_polling_wait_time_seconds: 5
}
schema: [
{ name: id, type: string }
]
file: { ... }
}
source.file is still required even when queue is set; the job reads it unconditionally at startup. Set format to match your files (csv or json); path, header, and latest_first are ignored in this mode but the keys must still be present.
| Field | Description |
|---|---|
URL | SQS queue URL. The job parses the AWS region from this URL. |
fetch_interval_seconds | How often to poll the queue for new file notifications. |
log_polling_wait_time_seconds | Long-polling wait time for each SQS receive call. |
schema is required when using the s3-sqs source. See Schema.
Running the Job
Once deployed, the job runs continuously; there's no schedule to trigger. It reads new files as they arrive (or new SQS notifications, if configured) and appends them to the destination table on the configured processing_time interval.