Data Catalog Sync Job
A searchable data catalog is only useful if it stays in sync with what's in your warehouse. The Data Catalog Sync Job scans every catalog in your IOMETE environment and indexes the tables it finds. Indexed tables appear on the Data Catalog page, where you can add documentation, assign owners, define classifications, and set maintenance properties.
- Version:
5.0.1(requires IOMETE3.16.xor later) - Source: View on GitHub
Installation
Marketplace
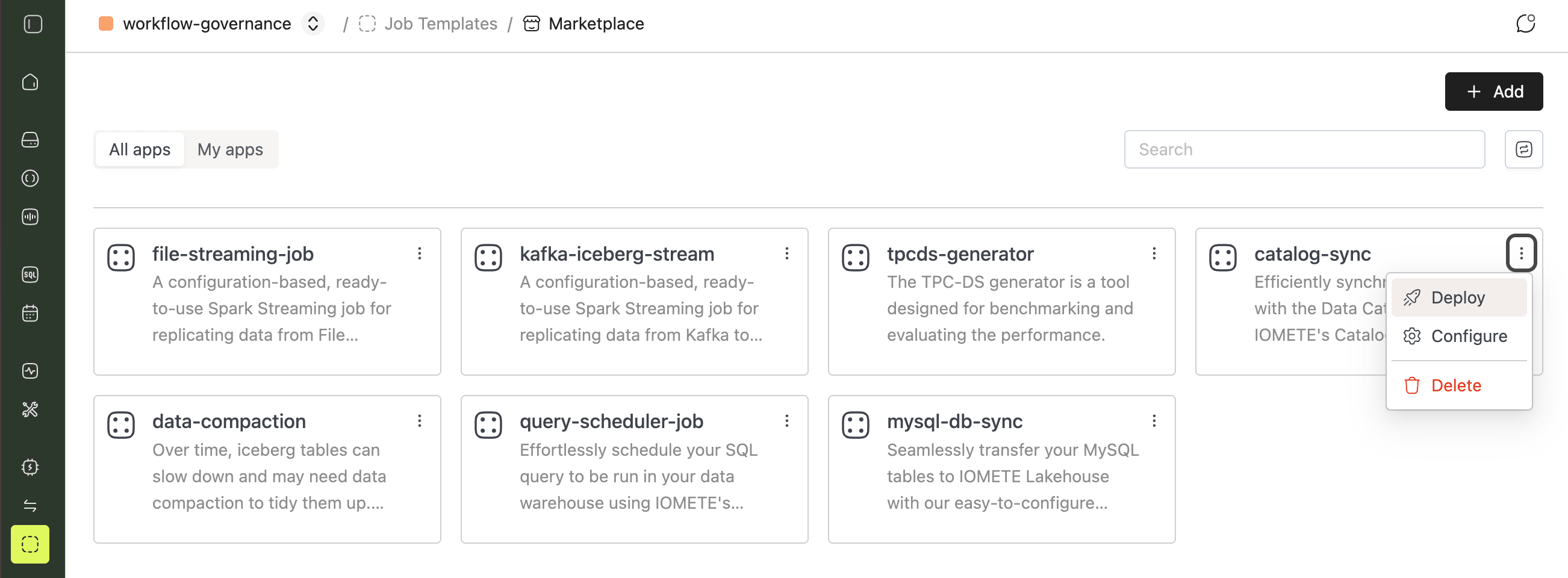
Open Job Templates and click Marketplace. Find the catalog-sync card, click the ⋮ menu, and select Deploy.
The job form opens pre-filled with recommended defaults.
Manual Setup
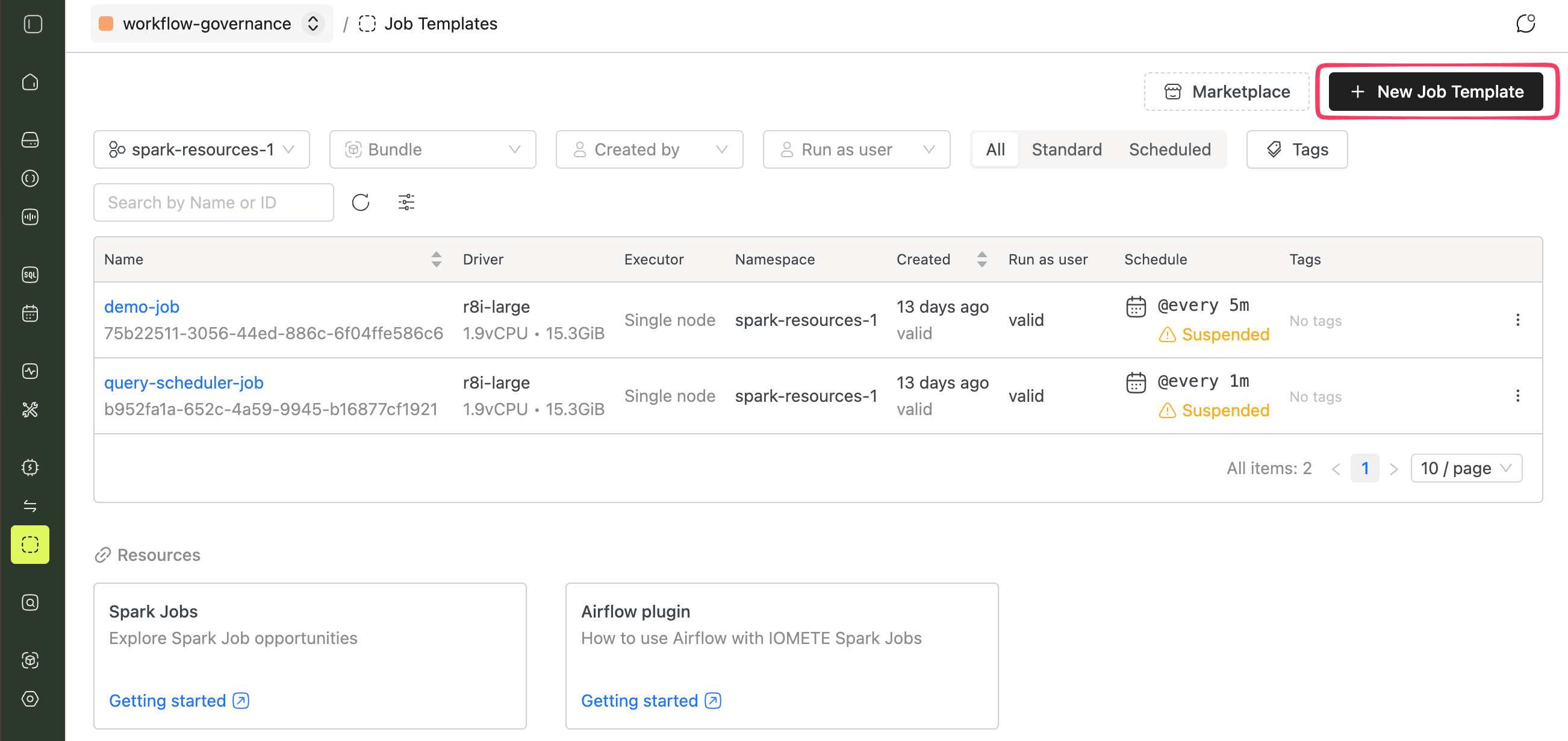
Open Job Templates in the sidebar and click New Job Template.
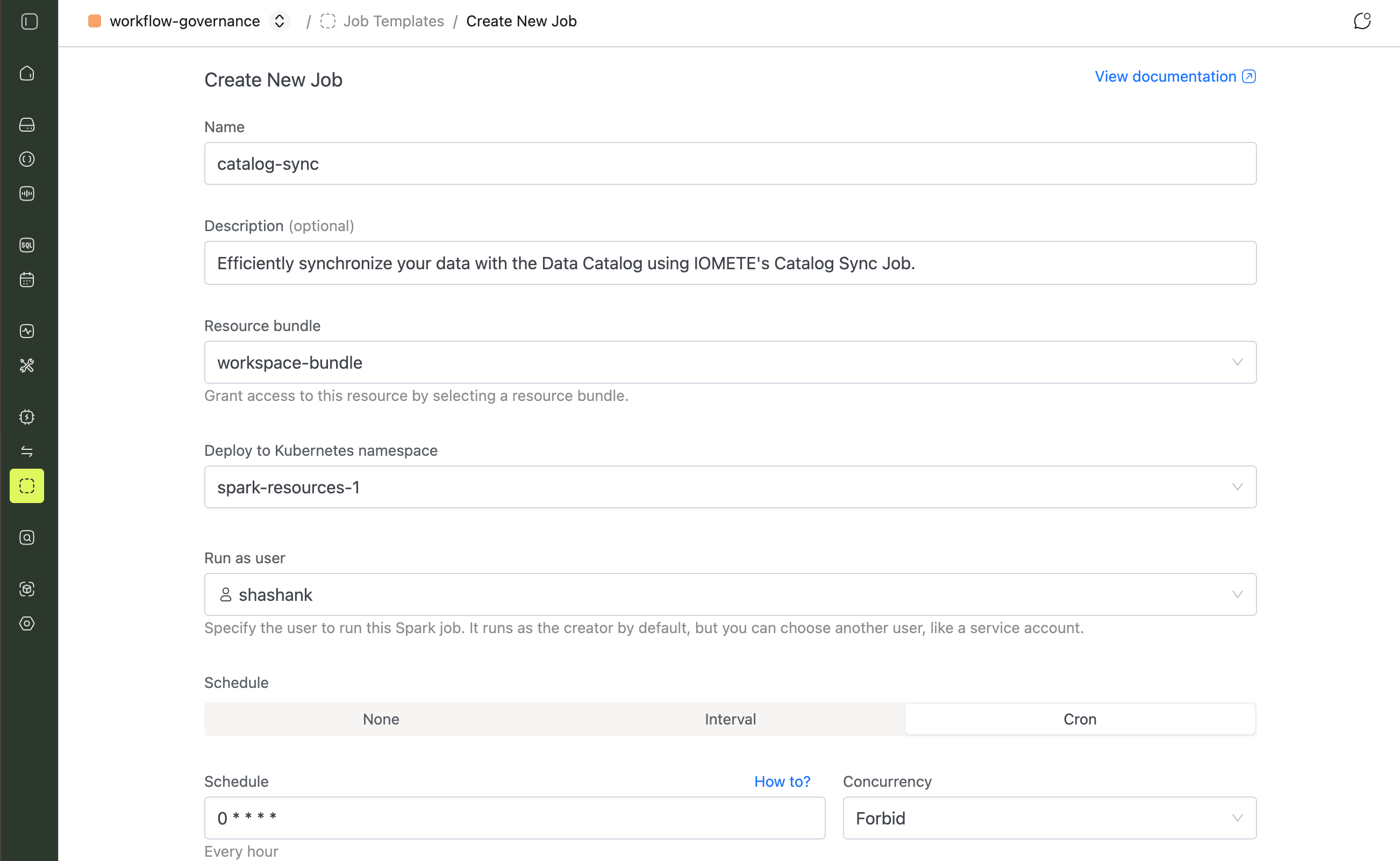
1. Name & Schedule
- Name: any name you like, for example
catalog-sync - Schedule:
0 * * * *(runs every hour). Use any cron expression that fits your needs. - Concurrency:
Forbid, which prevents overlapping runs if a previous execution is still in progress.
2. Application
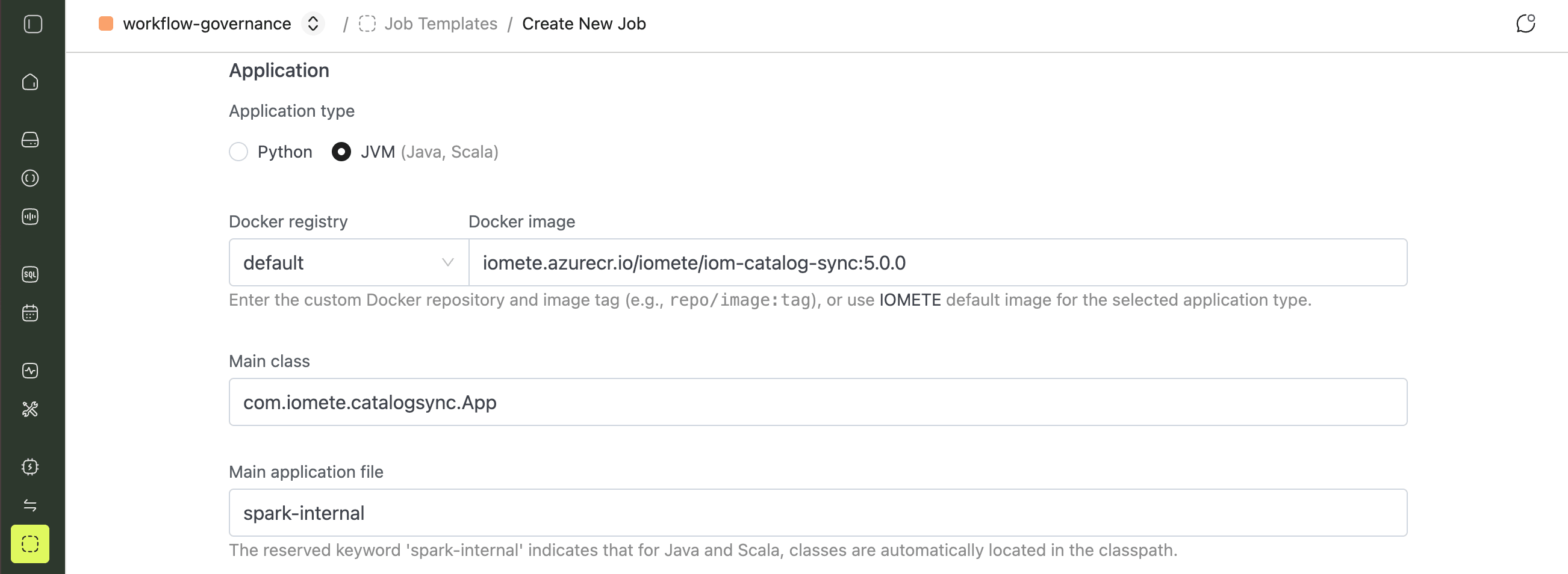
- Application type:
JVM (Java, Scala) - Docker image:
iomete.azurecr.io/iomete/iom-catalog-sync:5.0.1(replace with the latest version) - Main Class:
com.iomete.catalogsync.App - Main application file:
spark-internal
3. Exclusion Rules Config
This step is optional and applies to both Marketplace and manual installs. Without a config file, the job falls back to its built-in defaults and indexes everything.
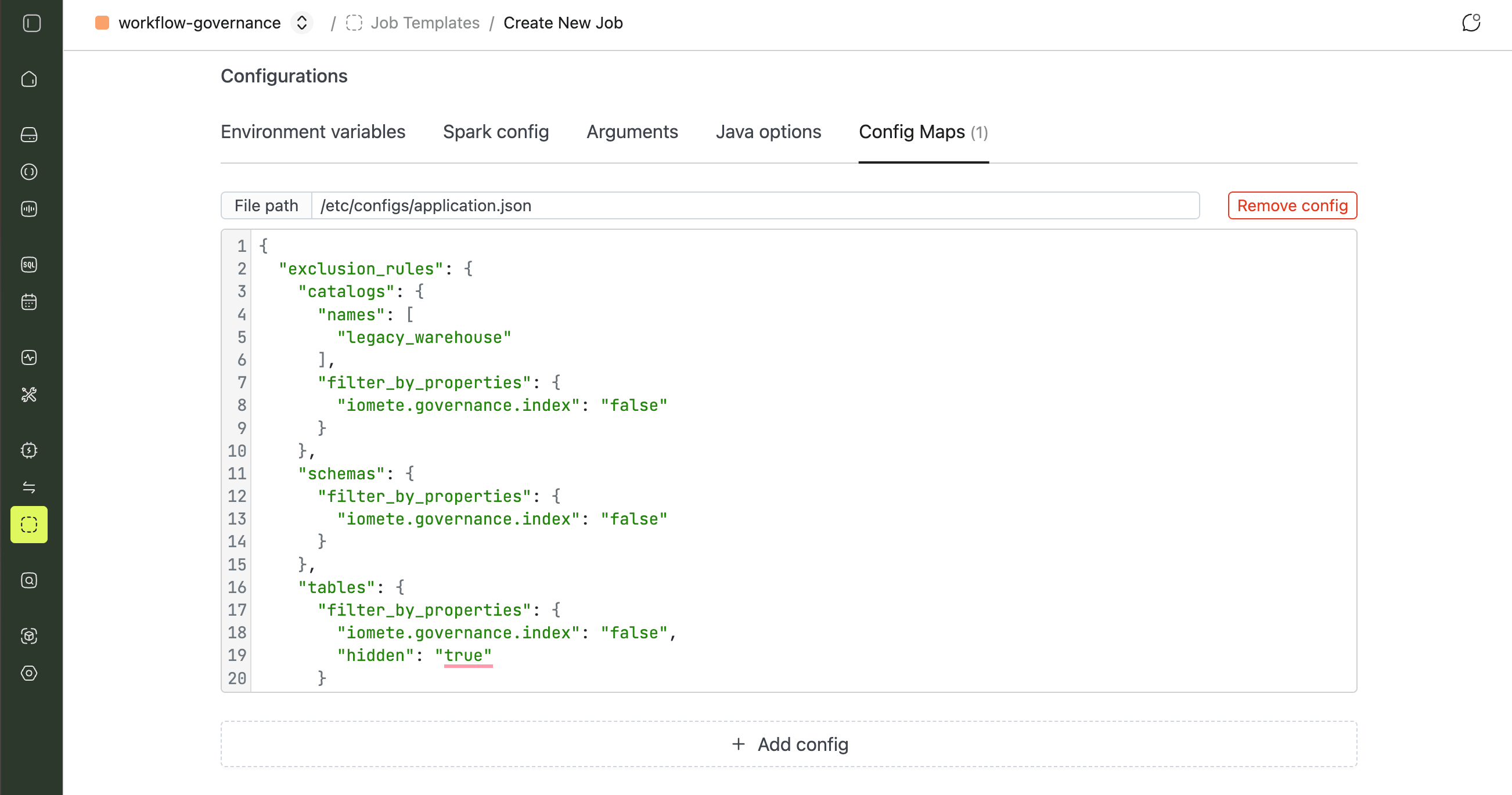
To control which catalogs, schemas, or tables are excluded, add a Config Map:
- File path:
/etc/configs/application.json - Content: your exclusion rules JSON (see Exclusion Rules)
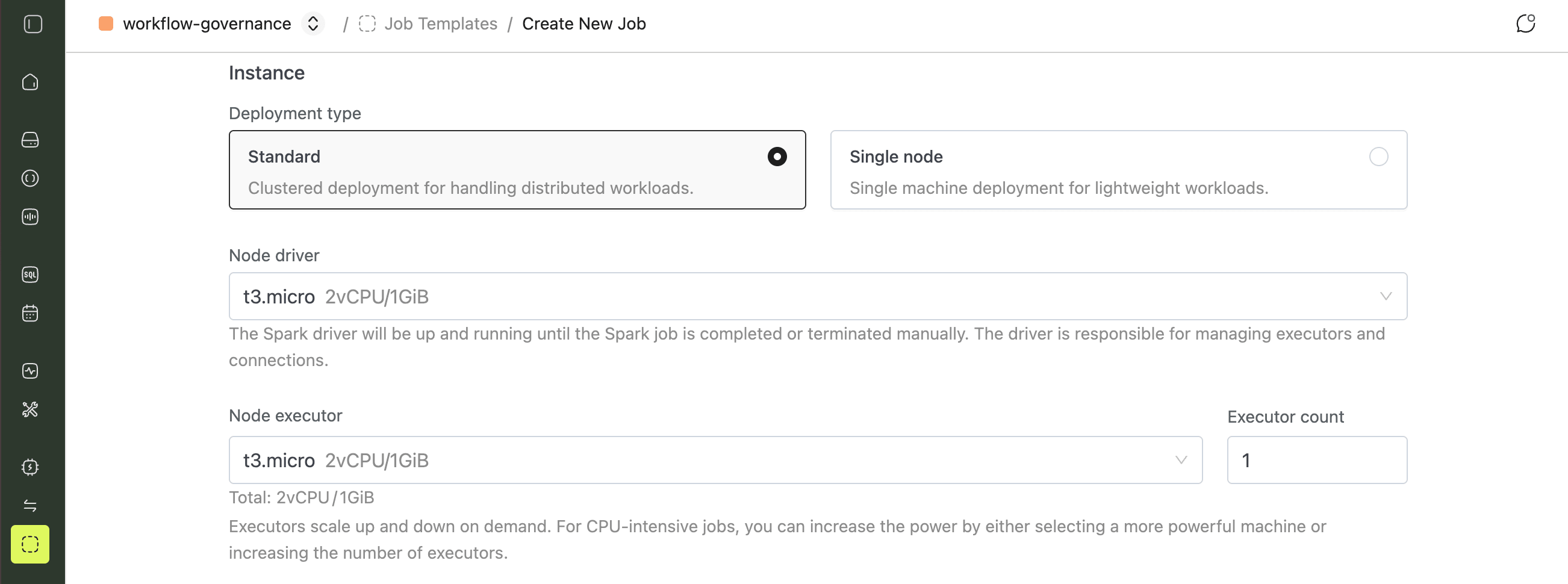
4. Instance Resources
- Deployment type:
Standard - Node driver / Node executor: choose any instance type that fits your workload
- Executor count:
1
Click Create to save the job.
How It Works
Once deployed, the job runs on its own. It fires on a schedule (hourly by default), scans every catalog in your environment, and indexes the tables it finds. Anything matching an exclusion rule is skipped.
You can change the schedule or trigger a run manually at any time.
Running the Job
The schedule handles most cases. If you need a fresh index right now (say, after creating a batch of new tables), open the job and click Run.
Deleted Tables
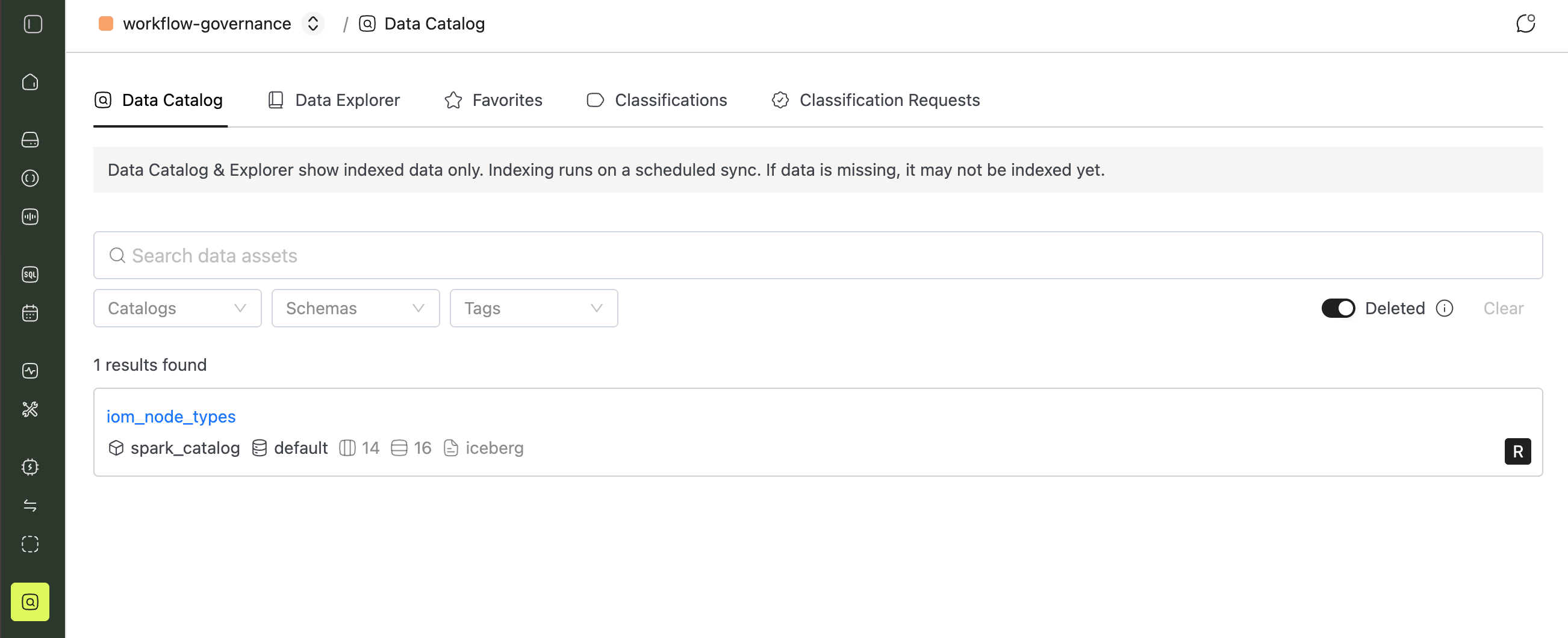
Dropping a table doesn't erase its history from the catalog. That history is useful when you need to know what existed before and when it disappeared. When a table is dropped from a source catalog, the sync job marks it as deleted and hides it from the default view instead of removing the record.
To review what was removed and when, use the Deleted toggle in the Data Catalog UI.
Deleted entries are kept indefinitely for now. Automatic cleanup of old deleted entries is planned for a future release.
Exclusion Rules
Not every catalog needs to be indexed. For example, you may want to skip:
- An external catalog (e.g., Oracle) with millions of tables that would clutter search results
- Catalogs or schemas containing sensitive data that shouldn't appear in the Data Catalog
- Personal or sandbox environments used for development
Exclusion rules let you skip specific catalogs, namespaces (schemas/databases), or tables during sync.
Default Rule
For a single rule that covers everything, start here. The default rule applies at all levels: catalogs, schemas, and tables. Any asset with a matching property is excluded from indexing.
{
"exclusion_rules": {
"default_rule": {
"filter_by_properties": {
"iomete.governance.index": "false"
}
}
}
}
With this rule in place, setting iomete.governance.index=false on any catalog, schema, or table excludes it from the sync. One rule, applied wherever you need it via properties.
Excluding Catalogs
For catalog-level control, exclude catalogs by name, by property, or both.
By Name
List catalog names directly. These catalogs are always skipped, regardless of their properties.
{
"exclusion_rules": {
"catalogs": {
"names": ["sandbox_dev", "legacy_warehouse", "user_personal_spaces"]
}
}
}
By Property
Set iomete.governance.index to false on the catalog in the Admin Portal when you create or edit it.
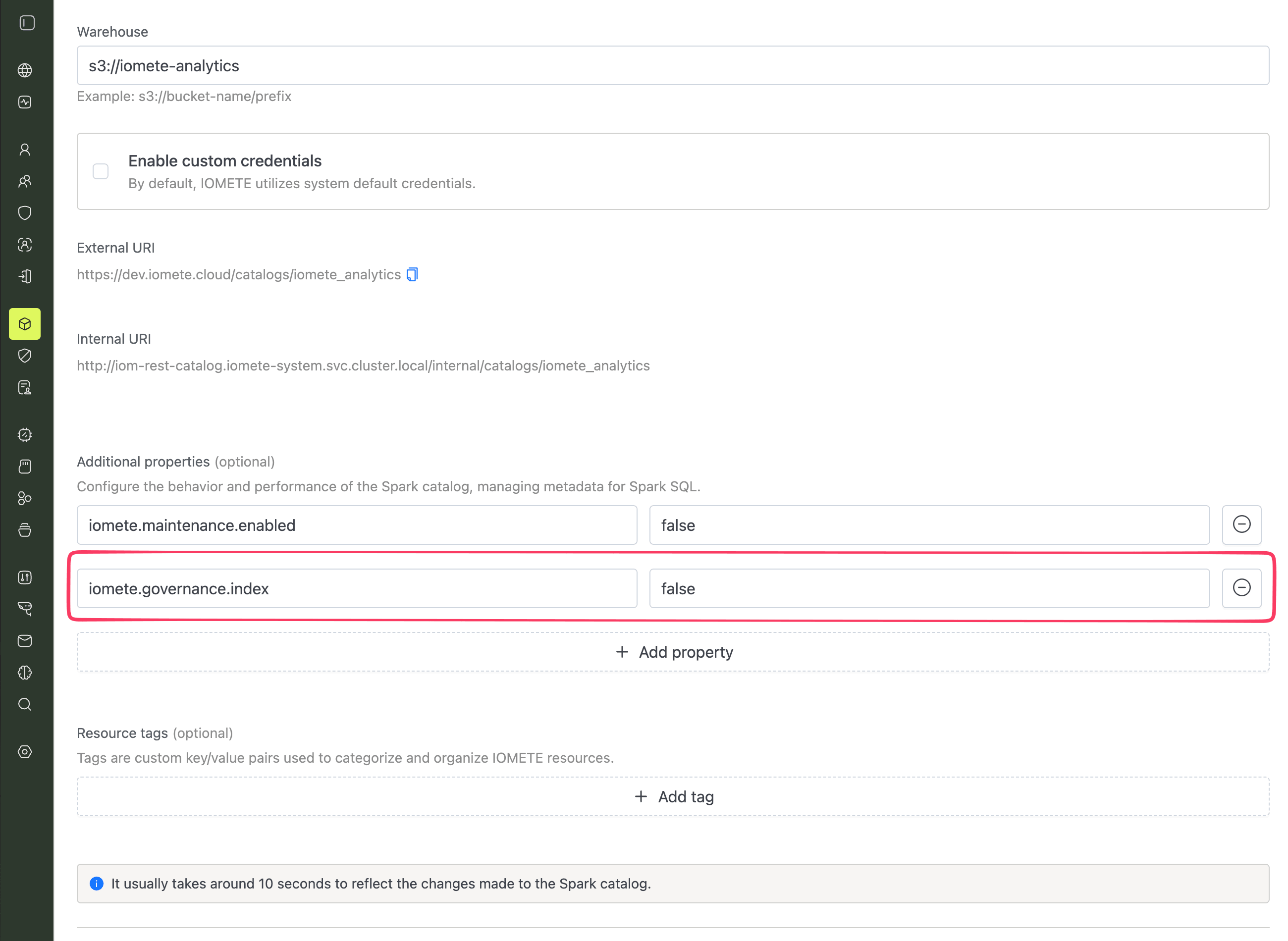
Then add the matching filter:
{
"exclusion_rules": {
"catalogs": {
"filter_by_properties": {
"iomete.governance.index": "false"
}
}
}
}
Combining Both
Use names and properties together. A catalog is excluded if it matches either condition.
{
"exclusion_rules": {
"catalogs": {
"names": ["sandbox_dev", "legacy_warehouse"],
"filter_by_properties": {
"iomete.governance.index": "false"
}
}
}
}
Excluding Namespaces (Schemas/Databases)
To keep a catalog in the index but skip a few schemas inside it, use namespace exclusion. It's property-based. Set the property in SQL to mark a namespace for exclusion:
ALTER DATABASE my_catalog.my_schema SET DBPROPERTIES ('iomete.governance.index' = 'false');
Verify the property:
DESCRIBE DATABASE EXTENDED my_catalog.my_schema;
To re-enable indexing later, flip the property back:
ALTER DATABASE my_catalog.my_schema SET DBPROPERTIES ('iomete.governance.index' = 'true');
Then add the exclusion rule:
{
"exclusion_rules": {
"schemas": {
"filter_by_properties": {
"iomete.governance.index": "false"
}
}
}
}
Excluding Tables
Tables work the same way as namespaces. Set a property on the table, then define the matching rule.
ALTER TABLE my_catalog.my_schema.my_table SET TBLPROPERTIES ('iomete.governance.index' = 'false');
Verify the property:
SHOW TBLPROPERTIES my_catalog.my_schema.my_table;
To remove the property later:
ALTER TABLE my_catalog.my_schema.my_table UNSET TBLPROPERTIES ('iomete.governance.index');
Then add the exclusion rule:
{
"exclusion_rules": {
"tables": {
"filter_by_properties": {
"iomete.governance.index": "false"
}
}
}
}
Multiple Properties (OR Logic)
When a table exclusion rule lists multiple properties, a table is excluded if any of them match.
{
"exclusion_rules": {
"tables": {
"filter_by_properties": {
"iomete.governance.index": "false",
"hidden": "true"
}
}
}
}
A table is excluded if iomete.governance.index is false or hidden is true. It doesn't need to match both.
Full Example
A complete configuration that uses every exclusion level:
{
"exclusion_rules": {
"catalogs": {
"names": ["sandbox_dev", "legacy_warehouse", "user_personal_spaces"],
"filter_by_properties": {
"iomete.governance.index": "false"
}
},
"schemas": {
"filter_by_properties": {
"iomete.governance.index": "false"
}
},
"tables": {
"filter_by_properties": {
"iomete.governance.index": "false",
"hidden": "true"
}
},
"default_rule": {
"filter_by_properties": {
"iomete.governance.index": "false"
}
}
}
}