Kafka Streaming

This is a collection of data movement capabilities. This streaming job copies data from Kafka to Iceberg.
Table of Contents
Deserialization Format
Currently, only JSON deserialization format supported.
Spark Job creation
- In the left sidebar menu choose Spark Jobs
- Click on Create
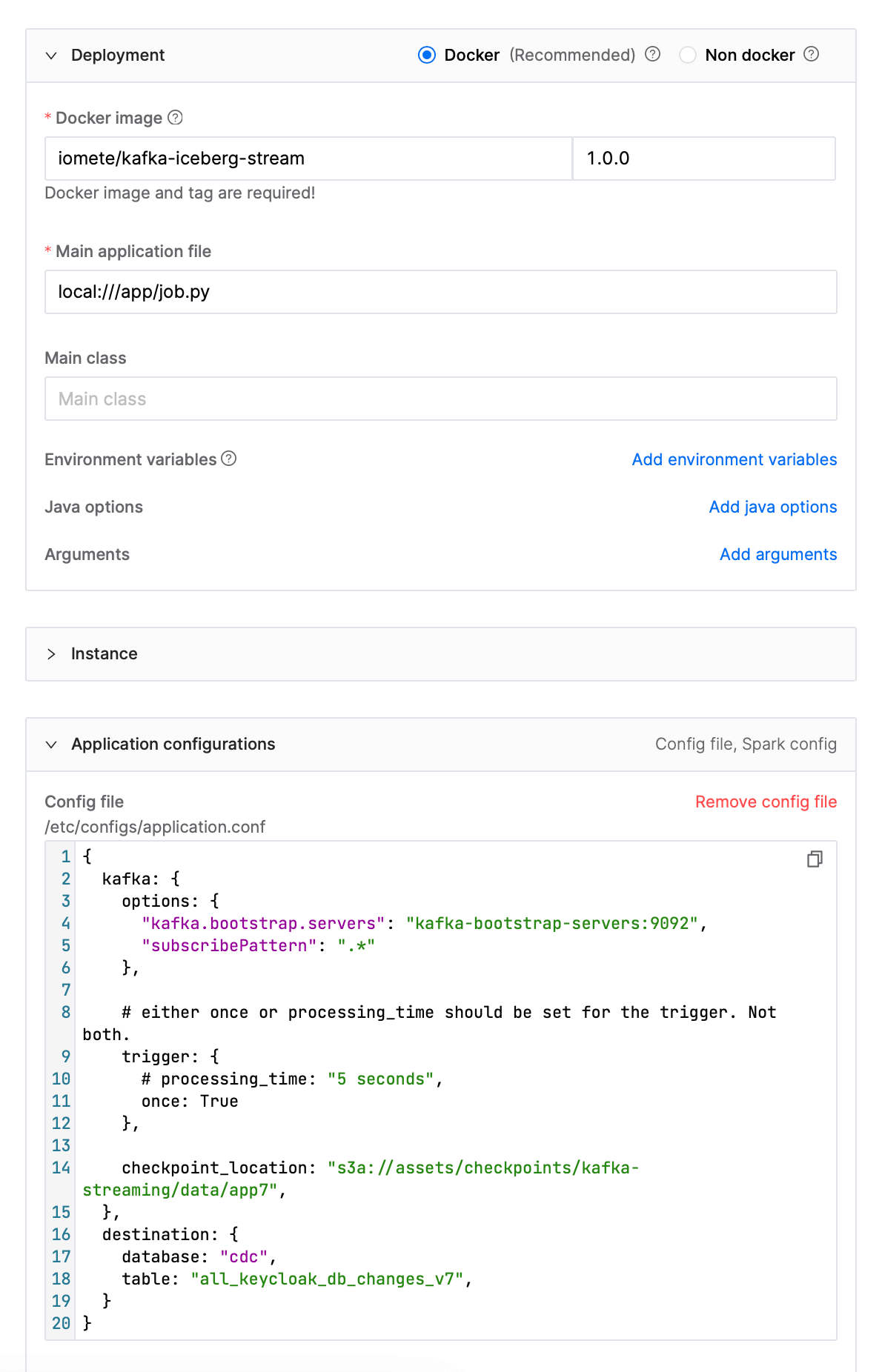
Specify the following parameters (these are examples, you can change them based on your preference):
-
Name:
kafka-iceberg-stream -
Docker image:
iomete/kafka-iceberg-stream:1.0.0 -
Main application file:
local:///app/job.py -
Java options (Optional):
-Dlog4j.configurationFile=/opt/spark/iomete/log4j2.properties- specify logging configuration file -
Config file:
{kafka: {options: {"kafka.bootstrap.servers": "kafka-bootstrap-server:9092","subscribePattern": ".*"},# either once or processing_time should be set for the trigger. Not both.trigger: {# processing_time: "15 minutes",once: True},# set checkpointLocation to object storage for production.# Example: "s3a://assests-dir/checkpoints/kafka-streaming/data/app1"checkpoint_location: ".tmp/checkpoints/kafka-streaming/data/app1",},destination: {database: "default",table: "all_db_changes_v1",}}noteNote: It's recommended to exclude the
startingOffsetsoption. If the table doesn't exist or is empty, it will default to theearliestsetting automatically. Conversely, if the table is filled, it will default to thelatestsetting. This allows you to start from the beginning when the table is empty and continue from where you left off (based on the checkpoint state) when the table is not empty.
Configuration properties
- kafka.options: Kafka options. See Kafka Consumer Configurations for more details.
- kafka.trigger: Trigger options. See Triggers for more details. Only one of the
processing_timeoronceshould be set. - kafka.checkpoint_location: Checkpoint location. See Checkpointing for more details.
- destination.database: Iceberg database name. Database should be created before running the job.
- destination.table: Iceberg table name. Table will be created if it does not exist.
Job will create a table with the following schema:
root
|-- topic: string (nullable = true)
|-- partition: integer (nullable = true)
|-- offset: long (nullable = true)
|-- timestamp: timestamp (nullable = true)
|-- timestampType: integer (nullable = true)
|-- key: string (nullable = true)
|-- value: string (nullable = true)
- topic: Kafka topic name that the record is received from.
- partition: Kafka partition number that the record is received from.
- offset: Kafka offset number that the record is received from.
- timestamp: Kafka timestamp that the record is received from.
- timestampType: Kafka timestamp type that the record is received from.
- key: Kafka record key.
- value: Kafka record value.