Time travel with SQL examples
Apache Iceberg provides versioning and time travel capabilities, allowing users to query data as it existed at a specific point in time. This feature can be extremely useful for debugging, auditing, and historical analysis.
Time travel in Iceberg allows users to access historical snapshots of their table. Snapshots are created whenever a table is modified, such as adding or deleting data, and are assigned unique identifiers. Each snapshot is a consistent and complete view of the table at a given point in time.
Below we will provide SQL example on how to use time travel in IOMETE platform.
Prepare sample data
CREATE TABLE time_travel_example (
id BIGINT,
name STRING,
created_at TIMESTAMP
);
Now insert first row into the table:
insert into time_travel_example values(1, 'first row', CURRENT_TIMESTAMP);
Wait couple minutes before inserting next row, so we can see the difference in timestamps.
Let's insert the second row into our table:
insert into time_travel_example values(2, 'second row', CURRENT_TIMESTAMP);
Review history
To query a table at a specific snapshot, you will need the snapshot ID. You can find it from the history table.
Now let's review the history of our table and see how many snapshots we have. We can do this by running the following query:
SELECT * FROM default.time_travel_example.history;
The history table is a special table that is automatically created for each table in Iceberg. It contains information about all snapshots of the table.
To query history of the table you need to provide database name and table name in the following format: database.table.history.
Result of the query will look like this:
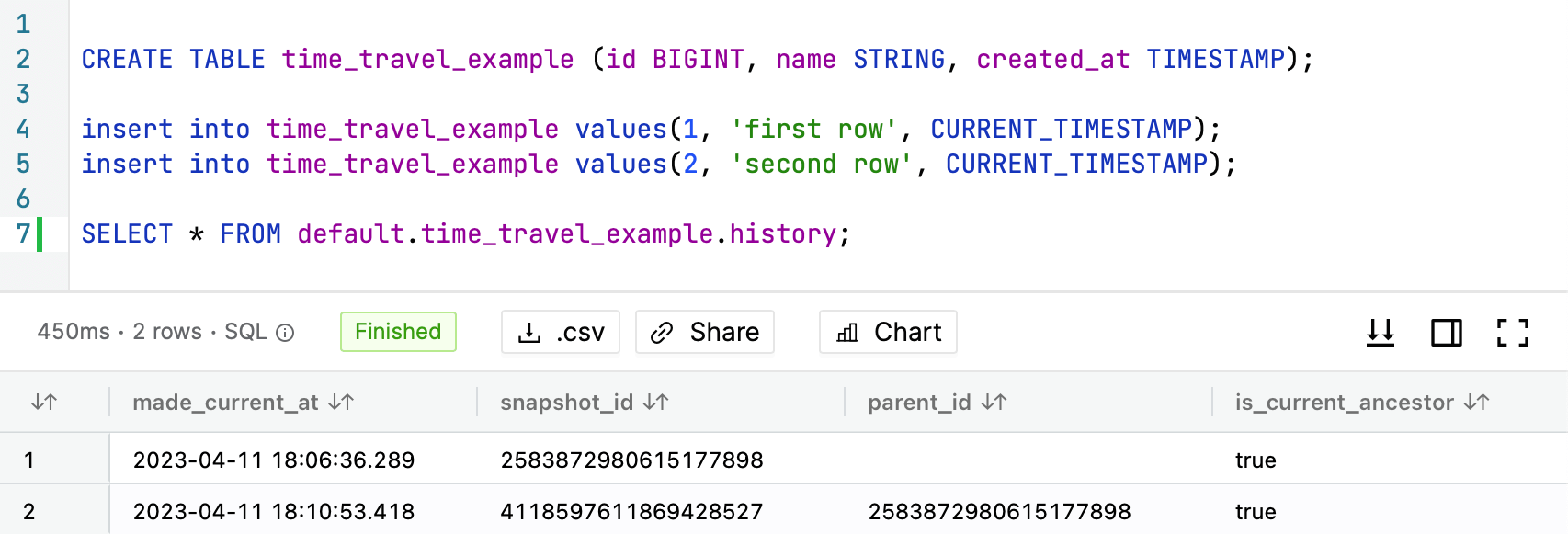
As you can see we have two snapshots. Additionally you can get more details about snapshots by running the following query:
SELECT * FROM default.time_travel_example.snapshots;
Time travel
Iceberg provides three ways to query data at a specific time.
- Using TIMESTAMP
- Using snapshot ID
- Using named reference (Branch or Tag)
You can run either of the queries below to query data:
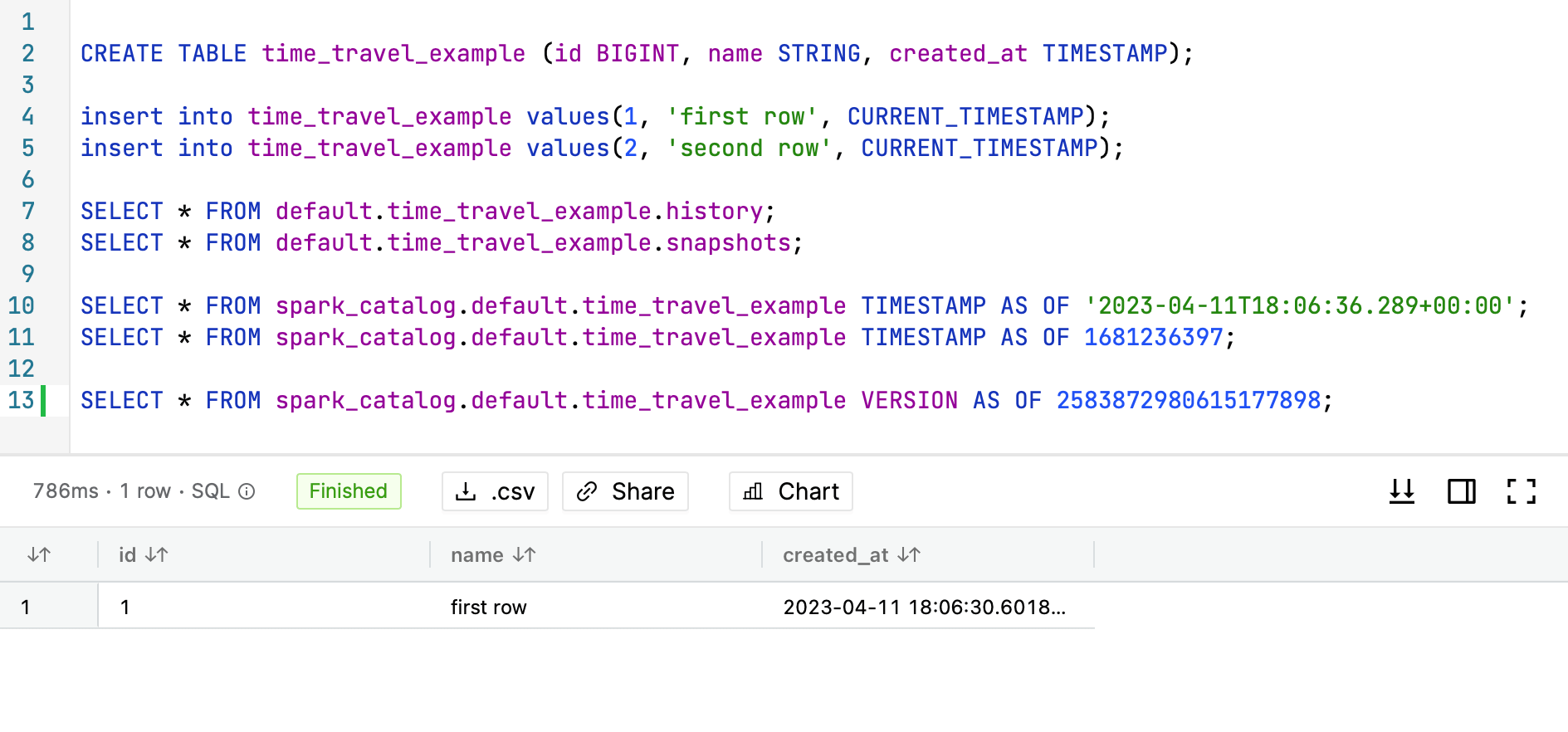
-- time travel to timestamp
SELECT * FROM spark_catalog.default.time_travel_example TIMESTAMP AS OF '2023-04-11T18:06:36.289+00:00';
SELECT * FROM spark_catalog.default.time_travel_example TIMESTAMP AS OF 1681236397; -- UNIX timestamp representation
-- time travel to snapshot with id 2583872980615177898
SELECT * FROM spark_catalog.default.time_travel_example VERSION AS OF 2583872980615177898;
All queries above will return only 1 result
Using named references
You can also use named references (branches and tags) to query data at a specific time. In the example below we will create a tag and then use it to query data.
-- create tag
ALTER TABLE default.time_travel_example CREATE TAG sample_tag;
-- View all references (branches and tags)
SELECT * FROM default.time_travel_example.refs;
-- time travel to tag / branch
SELECT * FROM spark_catalog.default.time_travel_example VERSION AS OF 'sample_tag';
SELECT * FROM spark_catalog.default.time_travel_example VERSION AS OF 'main';
More about branches and tags in the What's next section below (Soon...).