Query Scheduler Job
IOMETE provides Query Scheduler Job to run your warehouse queries on a schedule or manually.
Installation
- In the left sidebar, under Applications, click Job Templates.
- Click Marketplace to open the list of preconfigured Marketplace jobs.
- Find
query-scheduler-job, open the actions menu, and click Deploy. - The Marketplace template opens a pre-filled Create New Job form. Review the defaults and update the values for your environment.
You can also create a job template manually with New Job Template, but the Marketplace flow is recommended because it pre-populates the Query Scheduler image, schedule, environment variables, and default query configuration.
Specify the following parameters (these are examples, you can change them based on your preference):
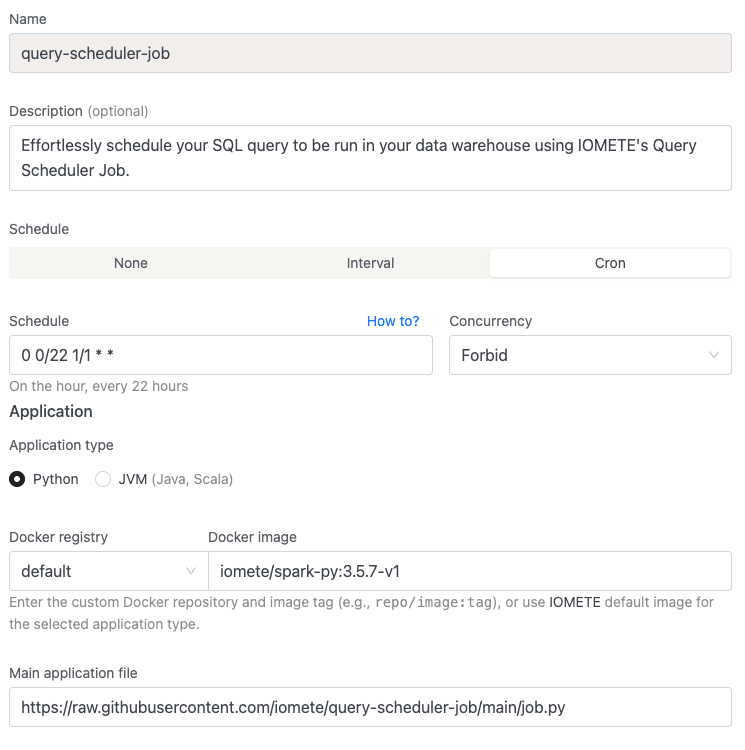
- Name:
query-scheduler-job - Schedule:
0 0/22 1/1 * * - Docker image:
iomete/spark-py:3.5.7-v1 - Main application file:
https://raw.githubusercontent.com/iomete/query-scheduler-job/main/job.py - Environment variables:
LOG_LEVEL:INFO
Environment variables
The Marketplace template includes LOG_LEVEL by default.
Config file
- Config file:
The Marketplace template includes a default query configuration under the
Config Mapstab. Review the queries and update them for your environment.
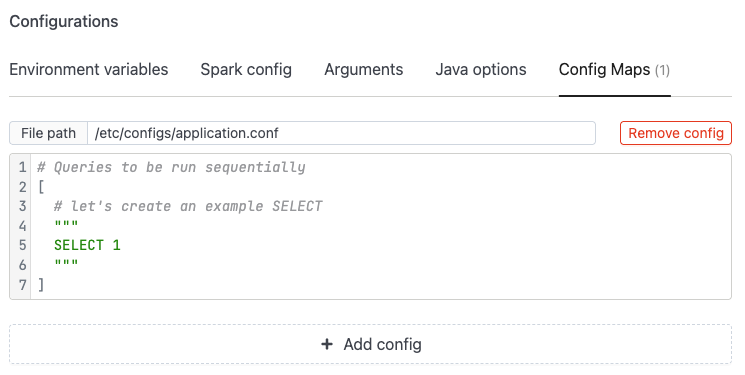
# Queries to be run sequentially
[
# let's create an example SELECT
"""
SELECT 1
"""
]
Click Create after reviewing the job configuration.
Summary
You can find the source code in GitHub. Feel free to customize the code for your requirements. Please contact us if you have any questions.
The job runs according to the cron schedule after it is created. To run it manually, use a one-time schedule when creating the job, or create the job first and then trigger it from the job list with the Run action.