Data Compaction Job
Over the time iceberg tables could slow down and require to run data compaction to clean up tables. IOMETE provides built-in job to run data compactions for each table. This job triggers the next iceberg processes:
- ExpireSnapshots Maintenance - Expire Snapshots
- Delete Orphan Files - See Maintenance - Delete Orphan Files
- Rewrite Data Files - See Maintenance - Rewrite Data Files
- Rewrite Manifests - See Maintenance
To enable data compaction spark job follow the next steps:
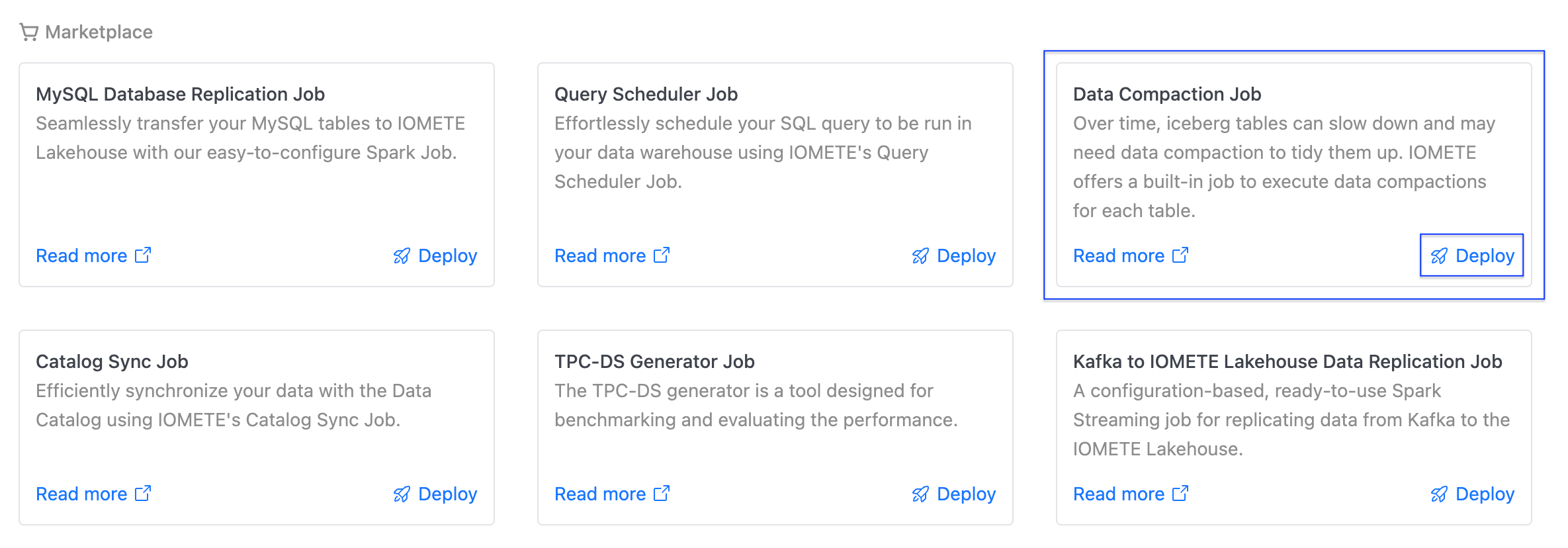
- Navigate to the
Job Templates, then click theDeploybutton on the Data Compaction Job card.
- You will see the job creation page with all inputs filled.
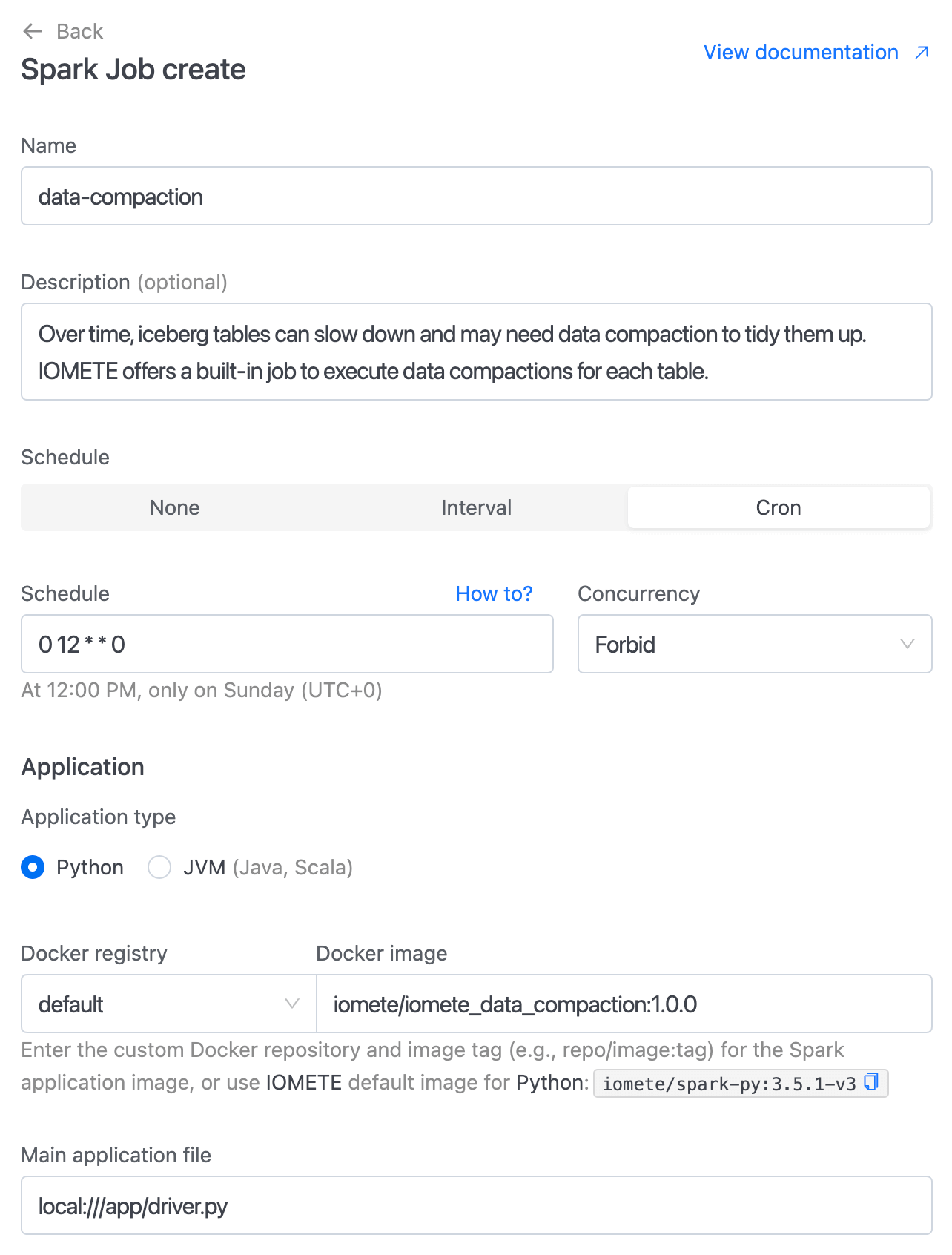
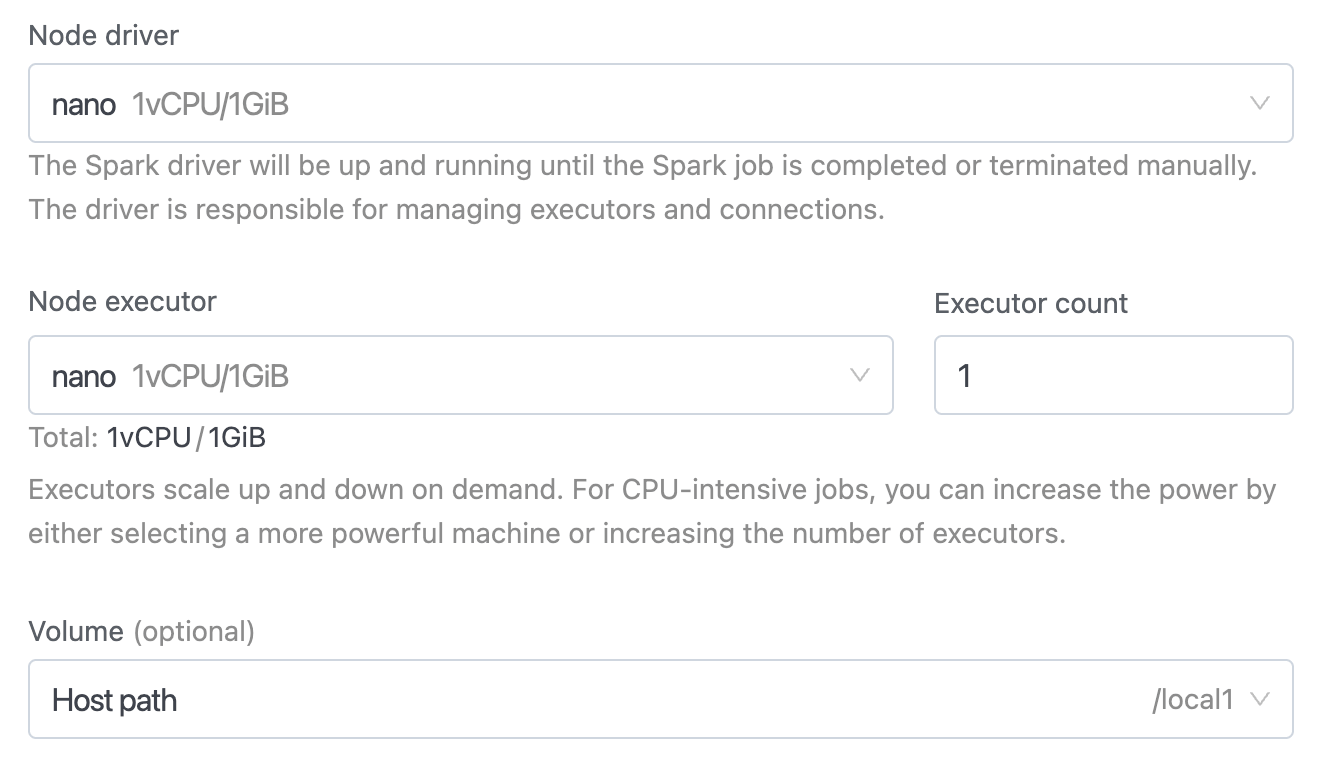
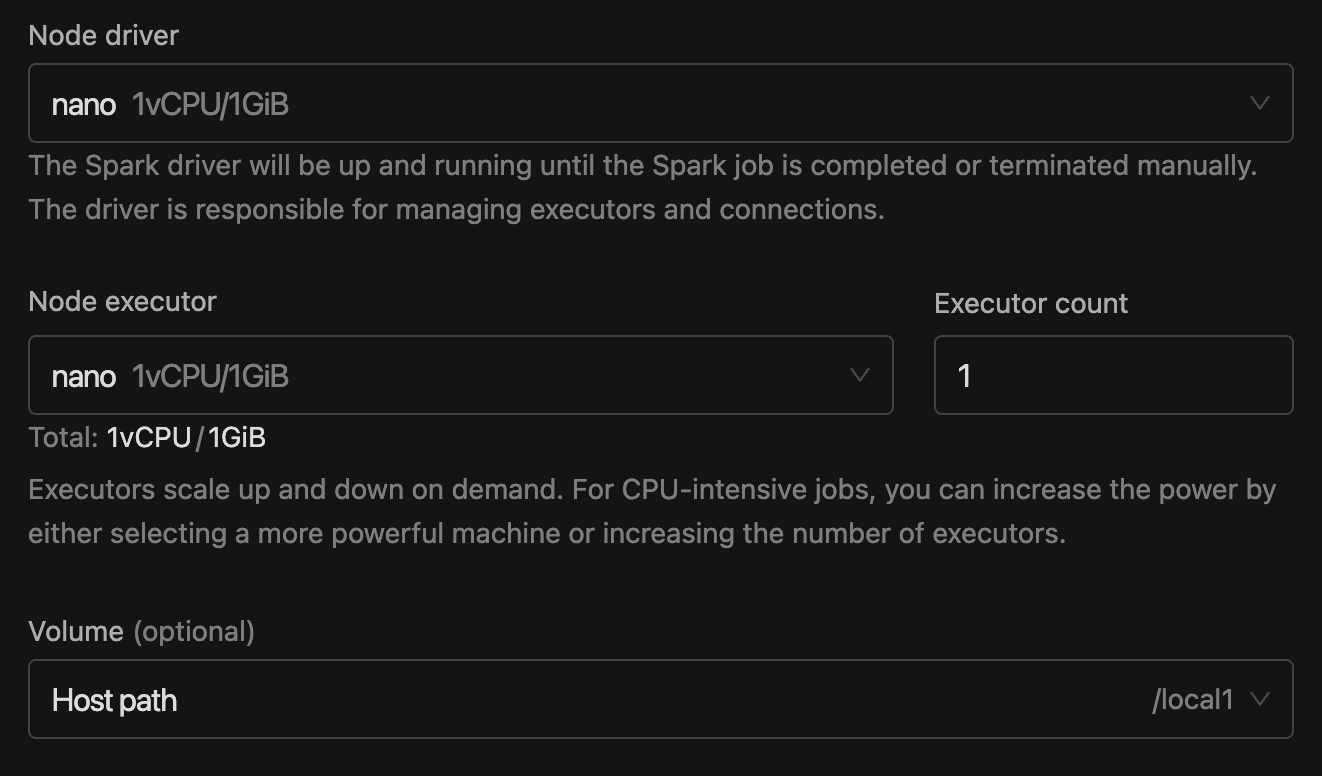
Job Configurations
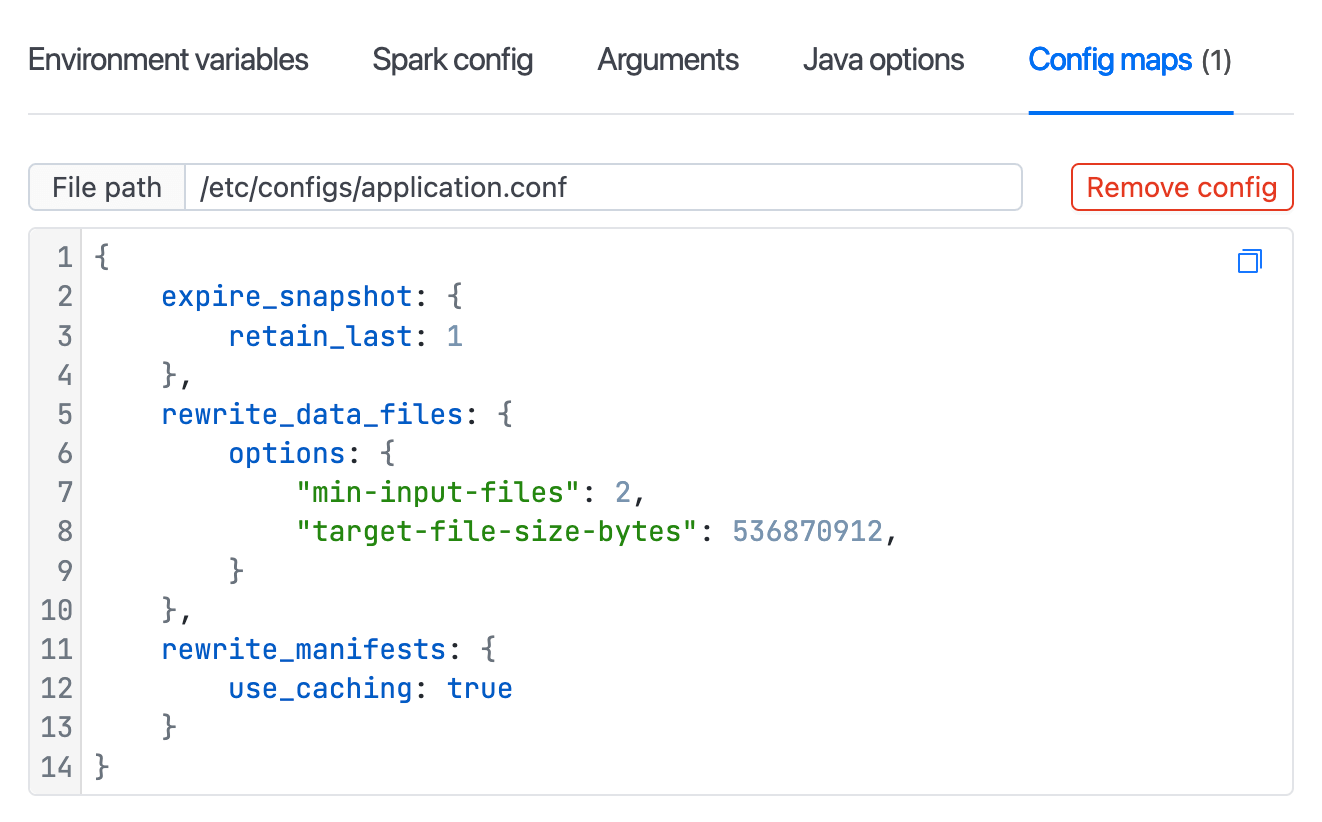
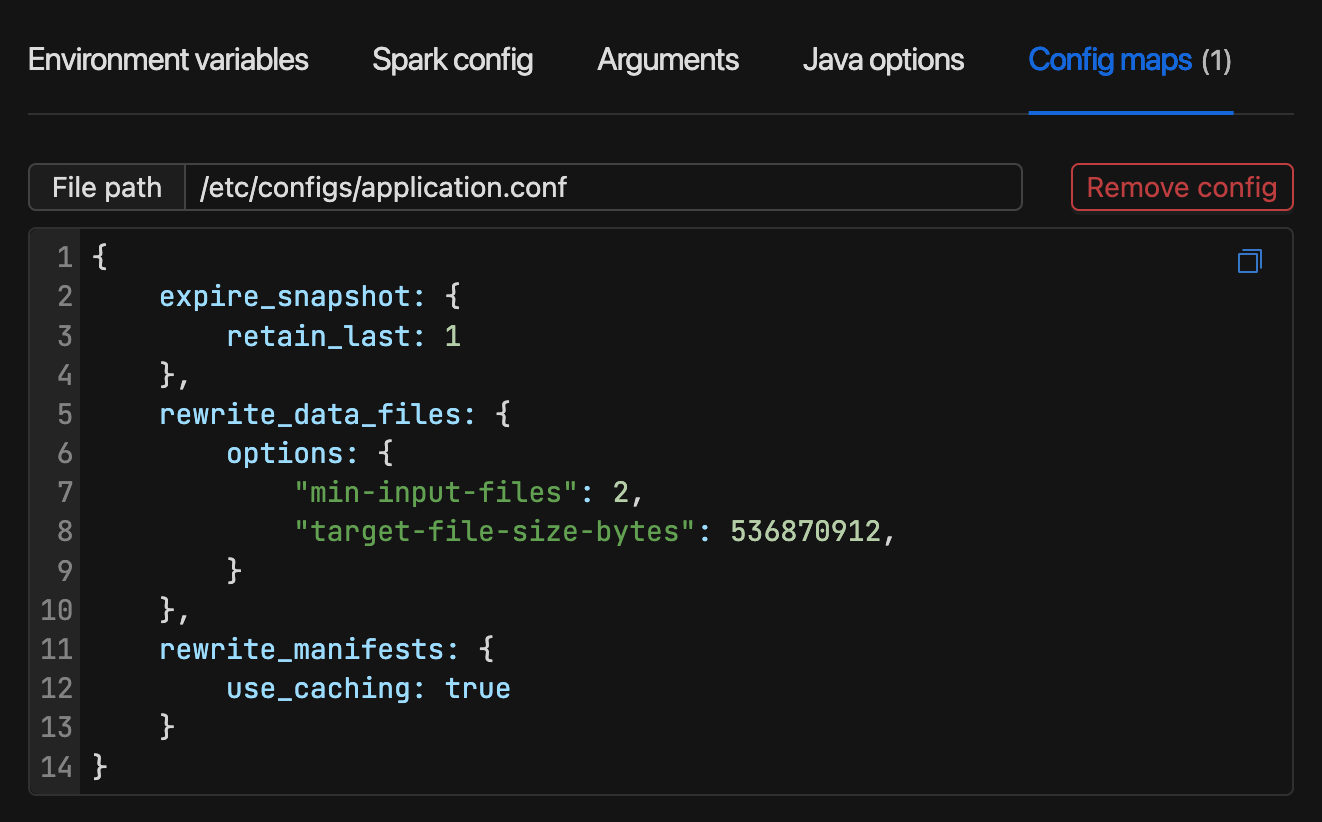
Instance
Github
We've created initial job for data-compaction which will be enough in most cases. Feel free to fork and create new data compaction image based on your company requirements. View in Github