IOMETE Release Notes
IOMETE Patch 1.19.2
- Added resource limits to kubernetes pod for new
spark-submit-service
IOMETE Release 1.19.1
- Optimized performance of spark-operator for handling large numbers of Spark job submissions.
IOMETE Release 1.19.0
- Restuctured sidebar menu in the IOMETE Console.
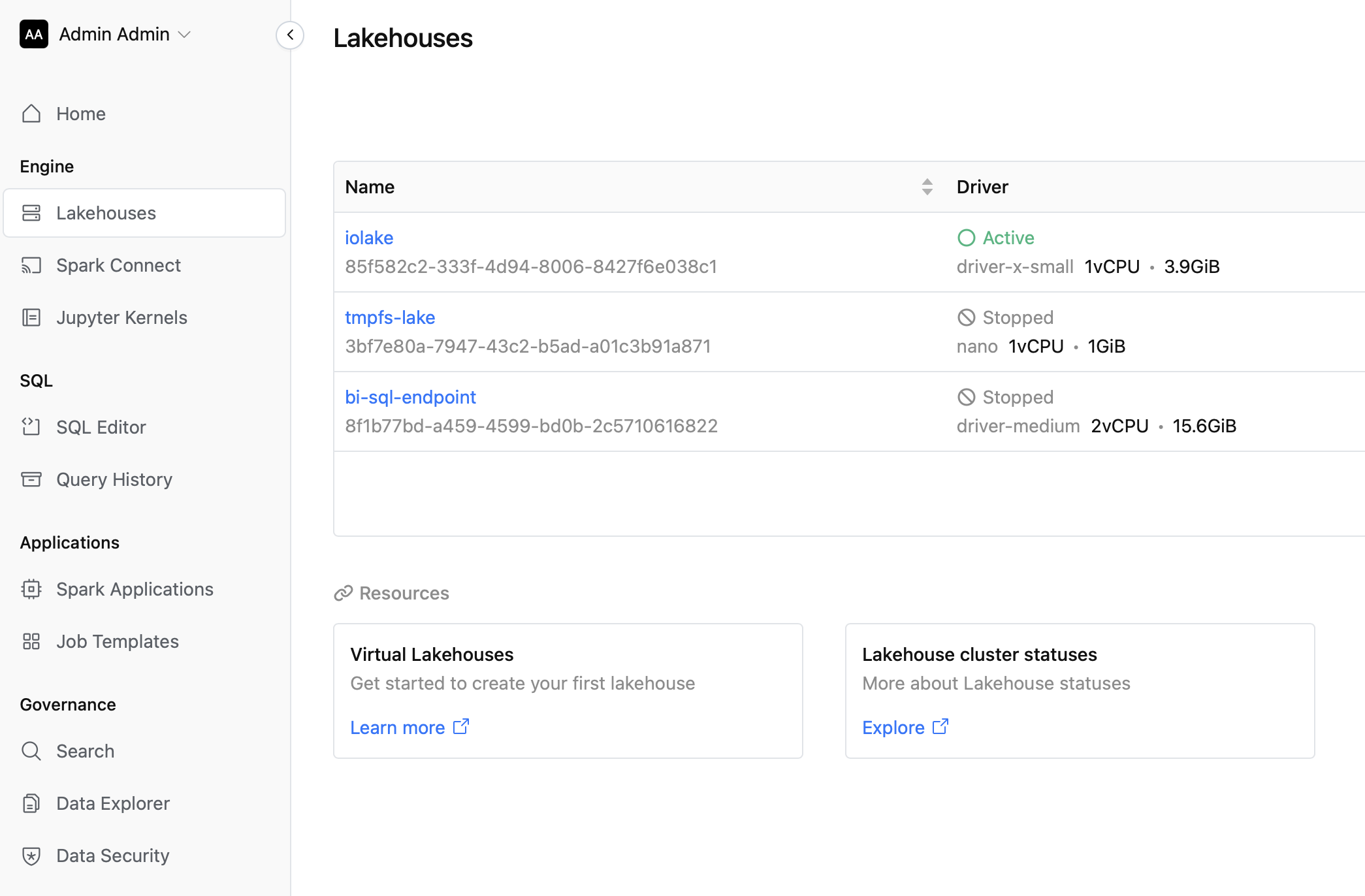
- Spark Applications: Introduced a new Spark Applications page featuring a zoomable timeline chart. This enhancement allows for easy tracking and visualization of applications across all Spark jobs.
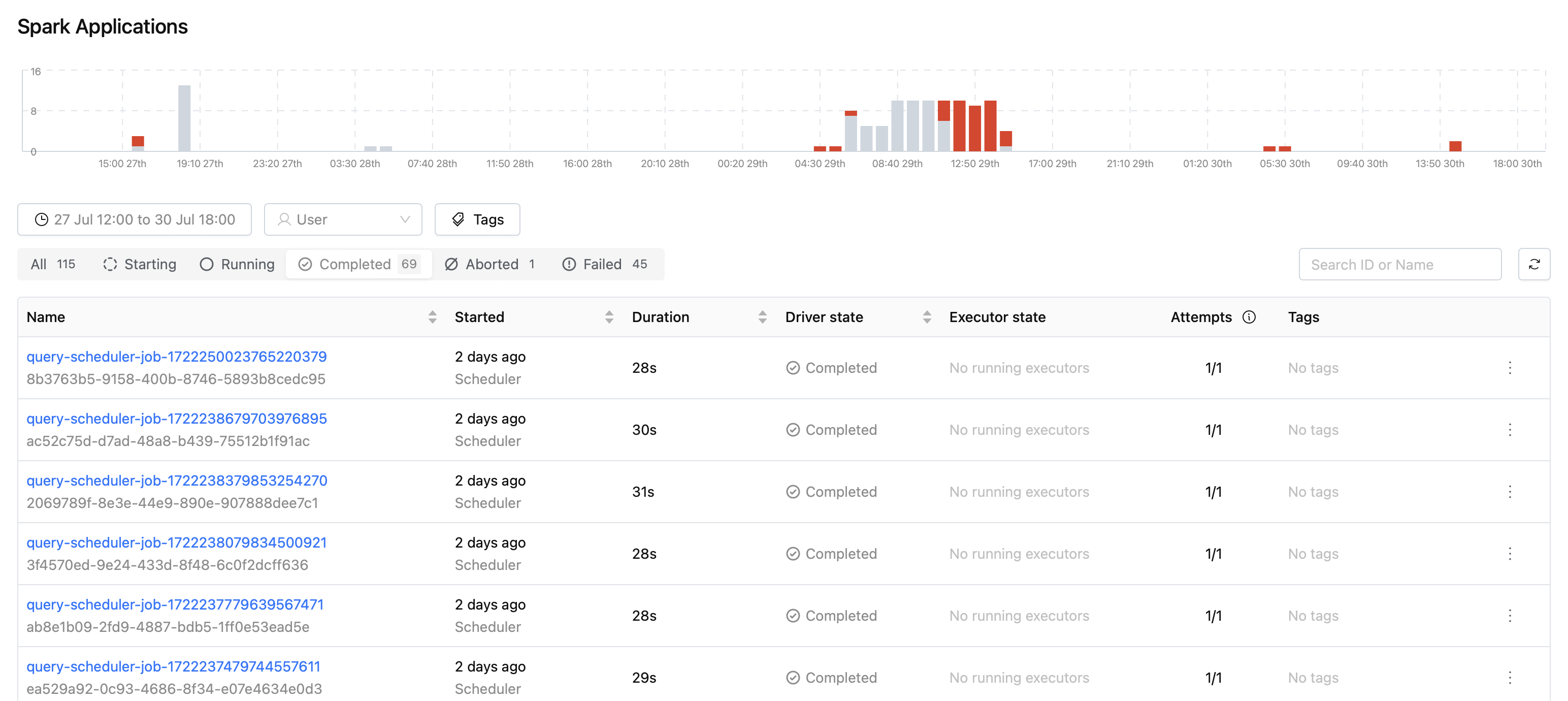
- Persistent Volume Claim (PVC) Options: When creating a Volume, you can now choose the "Reuse Persistent Volume Claim" and "Wait to Reuse Persistent Volume Claim" options on a per-PVC basis. This feature allows for customized volume configurations for different lakehouse and Spark resources, providing greater flexibility and control over resource management.
IOMETE Release 1.18.0
- Fixed issue with
explain ...sql statement. - Added cell expand to the SQL Editor result grid. You can double click on the cell with multi-line value to expand it.
- Added import/download functionality to the worksheets in SQL Editor.
- Fixed issue with DBeaver and Power BI integrations.
- UI / Design improvements in SQL Editor.
IOMETE Release 1.17.0
- Fixed issue where nessie catalog displayed wrong list of databases/tables in the SQL Explorer
- Launched beta version of Data-Catalog Explorer (Available in the Data-Catalog menu: from right-top side choose Explorer)
- Fixed "Invalid YeafOfEra" issue during Registration of Iceberg Tables.
- SQL Editor: Database Explorer improvements
- Added partitions folder, you can view table partition columns.
- Added Iceberg View support.
viewfolder now available for iceberg catalogs - Improved error messaging in SQL Editor
- Added item "Open in explorer" to the right-context menu. You can open the selected table in the Data-Catalog Explorer to view detailed information and snapshots
- Redesigned result charts
- Added Spark / Iceberg / Scala version information to the Data-Plane Informatino page in the Settings menu
- Improved Cron editor in Spark Job configuration
- Overall design improvements: slowly moving to a more compact design
IOMETE Release 1.16.0
New Features
- Added Nessie catalog support (Beta)
Performance Improvements
- Updated spark-operator with performance optimizations and bug fixes
- Enhances overall system stability and efficiency
Enhanced Validation
- Implemented stricter validation for Node Types:
- CPU: Minimum 300 milli-cores
- Memory: Minimum 900 MiB
- Ensures compliance with Spark requirements for optimal performance
User Interface Enhancements
- Various UI improvements for better user experience
Bug Fixes
- Resolved issue with "STARTING" status in Spark Jobs
- Improves job status accuracy and monitoring
IOMETE Release 1.15.0
Spark Operator Enhancements:
- Improved performance to handle ~1000 Spark Job submissions per minute
- Fixed conflict issues when submitting Spark jobs via API
- Added comprehensive metrics to Spark run details view
- Implemented Timeline (beta) feature for tracking status changes
- Integrated Kubernetes events for Spark Resources (Run, Lakehouse)
Job Management Improvements:
- Introduced Job retry policy
- Spark run metrics now available during "running" state
- Fixed issue where Spark UI occasionally failed to update
- Resolved Spark History redirection issue (now opens correct page on first load)
- Addressed Spark driver service name conflicts caused by long job names
- Implemented periodic garbage collection for failed jobs in Kubernetes
- Added support for job run tags and filtering by tag
- Introduced option to re-trigger runs with the same configuration
Monitoring and Logging:
- Added support for Splunk logging
- Implemented new System Config in UI Console
- Added "Spark Jobs alive time" to new "System Config" page
- Separated Driver and Executor task durations
- Display summary of total running/complete/pending runs on Spark job page
- Spark job log view now auto-scrolls to bottom when new logs are added
UI/UX Enhancements:
- Added time filter to Job Runs
- Displaying Scheduler Next Run information on UI
- Added ID to Spark Run Details page
Performance Optimizations:
- Fixed long job names causing Spark driver service name conflicts
Additional Features:
- Implemented "Spark Jobs alive time" configuration
IOMETE Release 1.14.0
- Ranger Audit now working as expected. Page added to Data Security section in IOMETE Console.
- Fixed issue with PowerBI integration.
IOMETE Release Patch 1.13.3
- Fixed issue with "Test Connection" in Spark Catalog settings.
- Spark Job names are now limited to 48 symbols, due to kubernetes limitations.
IOMETE Release Patch 1.13.2
- Added TLS support to spark-operator.
IOMETE Release Patch 1.13.1
- Fixed filter in Kubernetes events, when no data is displayed after choosing "Driver pod" filter.
- Fixed issue with Spark UI and Spark History links.
- Fixed issue when spark-operator unable to access startup files from the storage bucket.
- Spark Job arguments now automatically quoted, no need to quote each argument manually.
IOMETE 1.13.0
- Filters / Search improvements on UI:
- Added search to Log Panel.
- Added filters to Job List.
- Added filters to Job Runs.
- Added more internal metrics (time metrics) to spark job endpoints and database operations.
- Kubernetes Events are now displayed in the IOMETE Console for Lakehouse / Spark Connect and Spark Job resource.
- Added
deps.filesto Spark Job configuration. Which will download the files from the given URL and add them to the working directory e.g./opt/spark/work-dir. - Java SDK. Prepared java SDK for working with Spark Job API.
- Improved Error Logging.
- Fixed issue with Timezones.
IOMETE 1.12.0
- Added Audit functionality. You can enable audit during helm installation by modifying property
ranger.audit.enabled. If enabled, audit data will be stored in lakehouse bucket. Audit logs can be viewed from the IOMETE Console by accessing Data Security page and selecting Audit Logs from left sub-menu. - Removed
docker.appVersionfromvalues.yamlfile. Now usingChart.AppVersionproperty to set application version for IOMETE services. - Socket and OpenAPI services now have static image version
1.10.0, they won't be changed with AppVersion.
IOMETE 1.11.1
- Updated CRDs in
iomete-data-plane-basechart to supportsecurityContext.seccompProfile. - Added
securityContext.seccompProfileto all spark containers.
IOMETE 1.11.0
- Iceberg upgraded to 1.5.
- Ranger now operates as non-root with
securityContextconfiguration. - Fixed a deployment issue where a warning was generated due to the
podSecurityContextcontaining an unknown fieldseccompProfilein Spark executor pods. - Fixed issue where
Typesensepod stuck due to PVC not being released by old pod. Changed the deployment strategy toRecreatefor Typesense. - Added Requests and Limits to all IOMETE Kubernetes resources.
- Added property
dataCatalog.piiDetectionin thevalues.yamldeployment file.- If enabled, the
Presidio(docker)PII analyzer will be installed. It is disabled by default due to the large Docker image size, which exceeds 6GB. - If enabled,
PII_DETECTION_ENABLEDenvironment variable or-DpiiDetectionEnabled=truejava options must be set to true in Catalog Sync spark job.
- If enabled, the
- Iceberg: Fixed the issue with reading parquet time_micros fields defined as bigint in the schema by adding BigIntVector allocation in VectorizedArrowReader.
IOMETE 1.10.0
New Features
Register Iceberg Table from S3 Location
Enables the creation of a catalog entry for an existing Iceberg table located in S3 that does not currently have a catalog identifier. Important Note: Avoid registering the same Iceberg table in more than one catalog to prevent data inconsistencies and potential corruption. Utilizes the Register Table procedure from the Iceberg system.
Snapshot Parquet Table
Allows the creation of a lightweight Iceberg table over an existing Parquet table folder without modifying the original source table. The snapshot table can be altered or written to independently of the source table while using the original data files. Employs the snapshot procedure from the Iceberg system.
Configurable Logging Sources
Users now have the flexibility to choose their logging source. Previously, only Loki was supported. Now, users can choose between Kubernetes, Loki, and Elasticsearch.
- Kubernetes: Displays logs only for active/current resources and does not include historical data (e.g., logs for terminated resources are not available).
- Elasticsearch: Requires an SSL connection and an API key for authentication.
Enhancements
Pod Security Context
Added securityContext settings to all pods, ensuring that all resources are running as non-root users.
- Note that Spark images requires root user only if using default hostPath volumes, which can be adjusted from Volume Settings in the IOMETE Console by choosing Dynamic PVC.
- Currently, only Apache Ranger requires root user permissions, which will be addressed in a future release.
Eliminated Assets Bucket
We have eliminated additional bucket created/used for assets, which was previously required for storing assets like 'sql query results', 'spark history data', etc. Now, assets are stored in the same bucket as the default lakehouse bucket.
Role/Permissions Settings
Redesigned and improved role/permissions settings for better user management and access control.
- Updated permissions page design for better user experience.
- IAM Settings now controlled by two permissions: View and Manage. Previously each component of IAM settings (Users / Groups / Roles) managed by separate permissions.
- Data Security / Data Catalog: List and View actions combined into a single
Viewpermission. Create and Manage actions combined into a singleManagepermission. - Added new permission for Spark Settings.
- Added new permission for Data Plane Settings.
IOMETE 1.9.2
New Features
- Volume Settings: Users can now adjust volume settings directly from the IOMETE Console. This includes selecting volume configurations for each Spark resource, with options for hostpath, dynamic PVC, and size specifications on a per-resource basis.
Enhancements
- Spark Connect Clusters - Connection Stability: Issues affecting Spark Connect Cluster connections, particularly from Jupyter notebooks and Windows environments, have been addressed.
- Spark Operator Webhook Configuration: This can now be deployed separately. This also enabled removing ClusterRole requirements from the base Helm chart.
- Removed Cluster Role: The Cluster Role previously required (to control MutatingAdmissionWebhookConfiguration) for the spark-operator is removed from the base Helm chart.
- User Permissions: Spark clusters previously running under root user permissions are now configured to operate under non-root user permissions.
- Grafana Metrics: The hardcoded namespace issue in the Grafana monitoring dashboard has been resolved.
- Bug Fixes: Various minor issues from the last release, including Spark URL problems, have been resolved.
IOMETE 1.9.0
Enhanced Connectivity and Compatibility
- SQL Client Integration: Users can now seamlessly integrate with SQL clients like DBeaver and DataGrip to list catalogs and Iceberg tables.
- BI Tool Support: Enhanced connectivity with BI tools such as Tableau and PowerBI allows for direct connection to catalogs, making it easier to list and interact with Iceberg tables.
Improved Configuration and Management
- LDAP Configuration: The IOMETE Console now supports LDAP configuration, offering a more streamlined and secure way to manage user access and authentication.
- Advanced Spark Catalog Options: Additional configuration capabilities have been introduced for Spark Catalog registration, providing more flexibility and control to users.
- Custom Node Pool Configuration: Users can now tailor node pool settings to their specific needs, allowing for optimized resource allocation and usage.
- Resource Tagging: The ability to add tags to various resources within the IOMETE Console improves resource management, making it easier to categorize and track Lakehouse, Spark Connect, Spark Jobs, etc.
Enhanced User Experience
- Jupyter Notebook Integration: Jupyter Notebooks now support authentication using a username and API token, enhancing security and user convenience.