The Iceberg Table Maintenance Landscape: From Open-Source to Fully Managed

This is Part 3 of our Apache Iceberg Table Maintenance series. Explore the full series:
- Part 1: The Hidden Debt in Your Lakehouse Tables
- Part 2: What Iceberg Gives You for Table Maintenance
- Part 3: The Iceberg Table Maintenance Landscape
- Part 4: How We Built Automated Table Maintenance
- Part 5: Running Iceberg Maintenance in Production
- Part 6: Why We Rebuilt Orphan File Cleanup from Scratch
Most teams assume that once they adopt Iceberg, table maintenance is largely taken care of.
In reality, Iceberg gives you the tools to maintain your tables, but it doesn’t tell you how to run them in production. And that gap shows up quickly in practice. In the previous post, we looked at what Iceberg provides out of the box: compaction, snapshot expiration, orphan file cleanup, and manifest rewrites. These are powerful tools, but they’re not enough for a production system.
A production system has to answer harder questions. Which tables need maintenance, what should run first, and how much resources it should use. It also has to deal with failures, partial runs, and prove that the table actually became healthier afterward.
This is where most teams hit the second wall. The first is realizing that table maintenance is not optional. The second is realizing that running CALL rewrite_data_files(...) from a cron job breaks down quickly.
Once you have hundreds of tables, multiple engines, streaming writes, governance rules, and real users waiting on query performance, that approach just doesn’t hold up.
Now we zoom out.
This post looks at the broader landscape. Open-source projects, cloud-native platforms, on-prem systems, and engine-agnostic orchestrators.
And more importantly, where each of them still falls short.
Open-Source Projects
When teams outgrow raw Iceberg procedures, open source is usually the next step. It offers more automation than cron jobs without locking you into a single vendor, but you now take on the responsibility of running the maintenance layer yourself.
In this space, two projects are worth looking at because they approach the problem from different angles.
Apache Amoro
Apache Amoro is the most ambitious of the two. It treats table maintenance as a continuous system rather than a set of one-off procedures.
At a high level, a central service monitors tables, evaluates them against thresholds, creates optimization plans, and dispatches work to Spark-based workers. It also goes beyond basic compaction, planning work across multiple tiers depending on table state.
Conceptually, this is the right direction. Continuous monitoring, prioritization, and workload isolation are exactly what a production system needs.
In practice, though, the system is still heavy to operate. It's tightly coupled to its mixed Iceberg architecture, which makes it harder to fit into standard setups. Metadata access is expensive, configuration is limited, and common patterns like restricting maintenance to recent partitions are missing. Observability is also weak, with some operations requiring debug logs to understand what actually ran, and even the runtime itself needs attention due to security issues in the default image.
The result is a powerful but operationally demanding system. Teams willing to invest in customization can make it work. For teams looking for something easier to run, it’s not there yet. We’ll share more details from our evaluation in a follow-up post.
Floe
Floe takes a different approach. Instead of a standalone service, it focuses on declarative, policy-driven maintenance across multiple catalogs. You define which tables to target, what operations to run, and under what conditions.
The key idea is moving from schedule-driven to signal-driven maintenance. Floe computes a "debt score" based on factors like small file percentage, delete file count, time since last maintenance, and failure history. Operations trigger when thresholds are crossed, not on fixed schedules.
This aligns closely with how production systems tend to evolve.
The limitation is maturity. Floe is still early, with minimal production adoption. The design is promising, but it's not yet a system most teams can rely on.
Taken together, these projects show where the open-source ecosystem is heading: toward continuous, signal-driven, and catalog-aware maintenance. But they also highlight the gap between good ideas and production-ready systems.
Cloud-Native Platforms
Cloud platforms show us what a better maintenance experience can look like.
You create the table, keep writing data, and the platform quietly handles the messy parts in the background. Compaction runs. Old snapshots expire. Metadata gets cleaned up. Most of the time, you do not even think about it.
That is exactly how maintenance should feel.
But there is an important catch.
This experience only works as long as your tables live inside that platform’s ecosystem. The moment your Iceberg tables sit in an external catalog, or need to work across multiple engines, the magic starts to disappear.
Snowflake
Snowflake's managed Iceberg tables get full automatic maintenance. Compaction, manifest optimization, and snapshot expiry all run by default, with almost no user control.
This is the ideal experience. Maintenance just happens, and you don't have to think about it.
The tradeoff shows up quickly. It only applies to tables managed within Snowflake. External catalogs get none of it. And while some history is exposed, visibility is partial. Data compaction is visible, but manifest optimization and snapshot expiry largely remain opaque.
Databricks
Databricks takes a similar approach with Predictive Optimization. It automatically runs OPTIMIZE, VACUUM, and ANALYZE for tables in Unity Catalog, using serverless compute.
The interesting part is not just automation, but timing. The system decides when each operation should run, not just what to run.
The boundaries, however, are the same. It only works within the Databricks ecosystem. External Iceberg tables are excluded, and configuration remains coarse, mostly limited to enable or disable settings and retention policies.
Dremio
Dremio sits slightly differently. It offers OPTIMIZE TABLE as a manual operation, and adds automatic maintenance through its Open Catalog built on Apache Polaris.
The Polaris foundation points toward a more open approach compared to fully proprietary platforms.
But the limitation still holds. Automation only applies to tables inside Dremio's catalog. Outside that boundary, you're back to manual execution.
Across all three, the takeaway is simple. Automatic maintenance works extremely well when the platform owns the table, catalog, and execution layer. The moment you step into multi-engine or multi-cloud setups, that experience starts to break down.
On-Prem and Hybrid Platforms
Now let’s look at the platforms that sit closer to your own infrastructure.
These are the systems teams usually consider when they need Iceberg maintenance in private cloud, on-prem, or hybrid environments. Compared to fully managed cloud platforms, they give you more control over where compute runs and how the stack is deployed.
But the tradeoff is familiar.
The maintenance experience is still tied to the platform around it. You get automation, but only as long as your tables, catalogs, and workloads live inside that ecosystem.
Cloudera
Cloudera builds on top of standard Iceberg procedures with its Lakehouse Optimizer (CLO), a managed service that automates maintenance through policy-based rules.
What stands out is the flexibility. CLO supports both schedule-based execution and event-driven triggers on insert, update, or delete, and uses table metadata to prioritize what actually needs maintenance. This moves closer to a system that reacts to table state rather than blindly following schedules.
The catch is portability. CLO requires Cloudera's platform. The underlying Spark procedures are portable, but the automation layer is not. Tables outside Cloudera's catalog don't benefit.
Starburst
Starburst takes a simpler approach with automated table maintenance in its Galaxy platform, with the same capabilities available in its self-hosted offering. You define maintenance at the table, schema, or catalog level, which is practical when managing large numbers of tables.
It's Trino-native, so there's no need for a separate Spark cluster, and the scope-based scheduling works well for broad coverage.
The limitation is that it remains schedule-driven. If a streaming table suddenly accumulates small files, it waits for the next window. There's no concept of table health driving when operations should run.
The lesson is similar across both platforms. They bring real automation and work well in hybrid environments, but the automation is still tied to their platform layer. If your lakehouse already runs on Cloudera or Starburst, the experience is solid. Outside those ecosystems, the value drops quickly.
Engine-Agnostic Platforms
So far, every option has had the same basic limitation.
Cloud platforms work beautifully inside their own ecosystem. On-prem and hybrid platforms give you more control, but the automation is still tied to the platform around it.
Engine-agnostic platforms try to solve the opposite problem.
Instead of asking you to move your tables, catalogs, or engines into a specific ecosystem, they sit above the stack you already have. Spark, Trino, Flink, Snowflake, Athena, different catalogs, different clouds. The goal is to orchestrate maintenance across all of them without forcing one engine or one platform to become the center of gravity.
That makes this category especially interesting for real-world Iceberg deployments, where the lakehouse is rarely as clean as the architecture diagram.
The tradeoff is maturity. These are newer products with less production history than Snowflake, Databricks, Cloudera, or Starburst. But they are also aiming directly at the gap those platforms leave behind.
Ryft
Ryft is a dedicated Iceberg table management platform focused on the full maintenance lifecycle: compaction, snapshot expiry, orphan cleanup, manifest optimization, and data reordering based on observed query patterns.
The important idea is that maintenance is not just schedule-based.
Ryft watches how tables are actually used. It looks at query and ingestion patterns per table, then adjusts what should run based on that behavior. That puts it closer to workload-aware maintenance than the usual "run compaction every night" model.
Its positioning is also intentionally broad. Ryft is engine-agnostic, catalog-agnostic, and multi-cloud. If your stack spans Spark, Trino, Snowflake, and Athena, Ryft is one of the few options that does not force you to pick a side.
The caveat is that it is still early as a company. The scope is ambitious, and the multi-engine approach addresses a real gap, but teams should validate operational maturity before treating it like established infrastructure.
LakeOps
LakeOps takes a similar engine-agnostic position, but describes itself more as a data lake control plane. It sits above Iceberg catalogs and query engines, and also supports Delta Lake alongside Iceberg.
The technical claim that stands out is its custom Rust-based compaction engine, which LakeOps says can run roughly 20x faster than traditional approaches.
That is worth paying attention to, because compaction is often where maintenance becomes expensive. If every rewrite depends on a heavyweight Spark job, the operational cost adds up quickly. A faster execution engine could matter a lot for high-volume tables.
LakeOps also leans into telemetry-driven maintenance. Instead of only running jobs on a fixed schedule, it can trigger work based on table size changes, query latency degradation, or cost spikes.
Like Ryft, it is multi-engine and multi-cloud, with support across Spark, Trino, Flink, Snowflake, and Databricks. The control-plane framing is the key difference. LakeOps does not try to replace your lakehouse stack. It tries to coordinate and optimize what is already there.
Across both platforms, the pattern is very different from cloud-native and on-prem systems.
Here, the usual platform line is exactly what these systems try to remove. The value comes from working across the messy, multi-engine reality many teams already have.
But the tradeoff is maturity. These products are newer and have less production history than the established platforms. Still, they point to where the market is heading: maintenance as an independent orchestration layer, not just a feature hidden inside one platform.
Choosing Your Path
By this point, the pattern is clear.
There is no single best maintenance model for every Iceberg deployment. The right choice depends on where your tables live, which engines touch them, and how much control you need.
| If your setup looks like this | The practical path |
|---|---|
| You use a single managed platform like Snowflake, Databricks, or Dremio | Use the built-in automation. This is where maintenance feels closest to invisible. |
| You run in an on-prem or hybrid platform like Cloudera or Starburst | Use the platform's maintenance layer, but understand that the automation is tied to that ecosystem. |
| You run Iceberg across multiple engines, catalogs, or clouds | Use an engine-agnostic orchestration layer, or build one that fits your architecture. |
That last category is where we landed.
Not because the existing options are bad. Many of them are excellent inside their target environments. But our customers needed maintenance that worked with the lakehouse architecture they already had: Kubernetes-native infrastructure, external catalogs, and multiple engines like Spark, Trino, and Flink.
Looking across the landscape, a few design principles became hard to ignore.
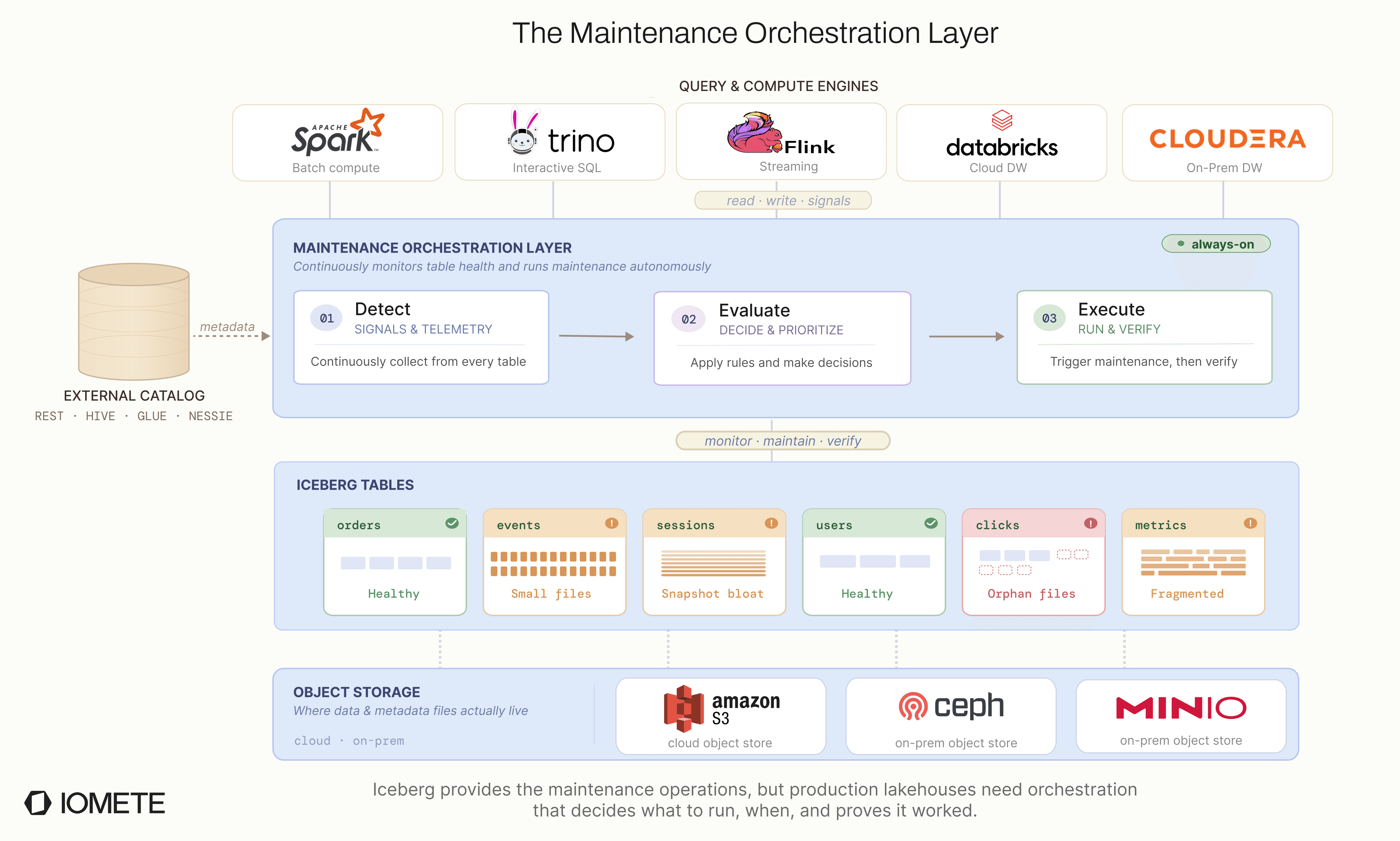
Schedules are not enough. A table that receives constant streaming writes can create thousands of snapshots in a day. Waiting for a nightly cron job is too late. Maintenance has to react to table health, not just time.
Not every operation needs the same execution path. Snapshot expiration is mostly a metadata operation. Compaction rewrites data files. Treating both as Spark jobs wastes compute and makes lightweight maintenance heavier than it needs to be.
Configuration needs inheritance. Platform teams need safe defaults. Catalog owners need broader controls. Table owners need fine-tuning when specific workloads behave differently. A single layer of configuration is not enough.
Observability has to be built in from the start. If maintenance runs automatically, users still need to know what happened. Which operation ran, why it ran, what changed, how long it took, and what it cost. Without that visibility, automation becomes another black box.
Those lessons shaped the system we built at IOMETE.
We needed maintenance that felt invisible like the best cloud platforms, reacted to table health like the strongest hybrid systems, worked across real multi-engine lakehouse environments, and stayed native to IOMETE's Kubernetes-based architecture.
That led us toward a detect, evaluate, execute pipeline with event-based detection, threshold-based triggering, separate execution paths for heavy and lightweight operations, inherited configuration, and full run-level observability.
We will go deeper into the engineering behind that system in our next post.
Resources & Further Reading
Open-Source Projects
- Apache Amoro: incubating project for self-optimizing Iceberg tables with continuous monitoring
- Floe: declarative, policy-driven Iceberg maintenance with signal-based triggers
Cloud-Native Platforms
- Snowflake Managed Iceberg Tables: automatic compaction, manifest optimization, and snapshot expiry
- Snowflake ICEBERG_STORAGE_OPTIMIZATION_HISTORY: Account Usage view for compaction history
- Databricks Predictive Optimization: automatic OPTIMIZE, VACUUM, and ANALYZE for Unity Catalog tables
- Dremio Automated Maintenance: automatic optimization via Enterprise Catalog
On-Prem and Hybrid Platforms
- Cloudera Lakehouse Optimizer (CLO): policy-based automation with schedule and event triggers
- Starburst Galaxy Automated Table Maintenance: scheduled Iceberg maintenance at table, schema, or catalog scope
- Starburst Enterprise Data Maintenance: self-hosted scheduled maintenance with cron expressions