Evaluating S3-Compatible Object Storage for Your Data Lakehouse

Choosing object storage for a self-hosted lakehouse is one of the hardest decisions to reverse. Every Parquet file, every Iceberg manifest, and every piece of metadata lives in the object store. Spark reads from it and Flink writes to it in real time. If the storage layer fails, stalls, or disappears; everything above it stops.
This is especially true for on-premises and private cloud deployments. Public cloud users get S3, GCS, or ADLS as managed services. Self-hosted teams have to choose, deploy, and operate their own storage layer. For years, that choice was easy: MinIO. It was fast, well-documented, and Kubernetes-friendly, and something most teams could work with.
That changed in late 2025, when MinIO entered maintenance mode and was subsequently archived. If you're running a self-hosted lakehouse or planning to build one, the storage layer question is suddenly wide open again.
This article evaluates the realistic alternatives with a practical assessment of what each option means for teams running lakehouse workloads on their own infrastructure.
The Role of Object Storage in a Data Lakehouse
A data lakehouse decouples compute from storage. This is the core architectural principle that makes it different from traditional data warehouses, where storage and compute are welded together inside a single system.
In a lakehouse, open table formats like Apache Iceberg sit between compute engines and the storage layer. Iceberg handles the hard parts (ACID transactions, schema evolution, time travel, partition pruning) by maintaining metadata that points to data files in object storage. Compute engines like Spark, Flink, and Trino — or lakehouse platforms like IOMETE — read that metadata, then go directly to the object store for the actual data.
This architecture is powerful, but it creates a hard dependency. The object store isn't just "where files go." It's the system of record. Every Parquet file, every manifest, every metadata file lives there. If the object store loses data, Iceberg's ACID guarantees don't help — the data is gone. If the object store is slow, every query is slow. If the object store can't handle concurrent access from dozens of Spark executors, your entire pipeline backs up.
For cloud-managed deployments, this is someone else's problem. AWS guarantees 99.999999999% durability on S3. But for self-hosted deployments (on-prem data centers, private clouds, air-gapped environments) you own this problem entirely. The object store you choose determines:
- Durability: Can it survive disk failures, node failures, and rack failures without losing data?
- Throughput: Can it feed hundreds of concurrent readers and writers at the speeds your compute engines demand?
- Scalability: Can it grow from terabytes to petabytes without re-architecture?
- Operability: Can your team deploy, monitor, upgrade, and troubleshoot it without a dedicated storage team?
Getting this wrong is expensive. Migrating petabytes of data between storage systems is a multi-week project that risks downtime and data loss. Choosing a storage layer that can't scale forces a painful re-architecture later.
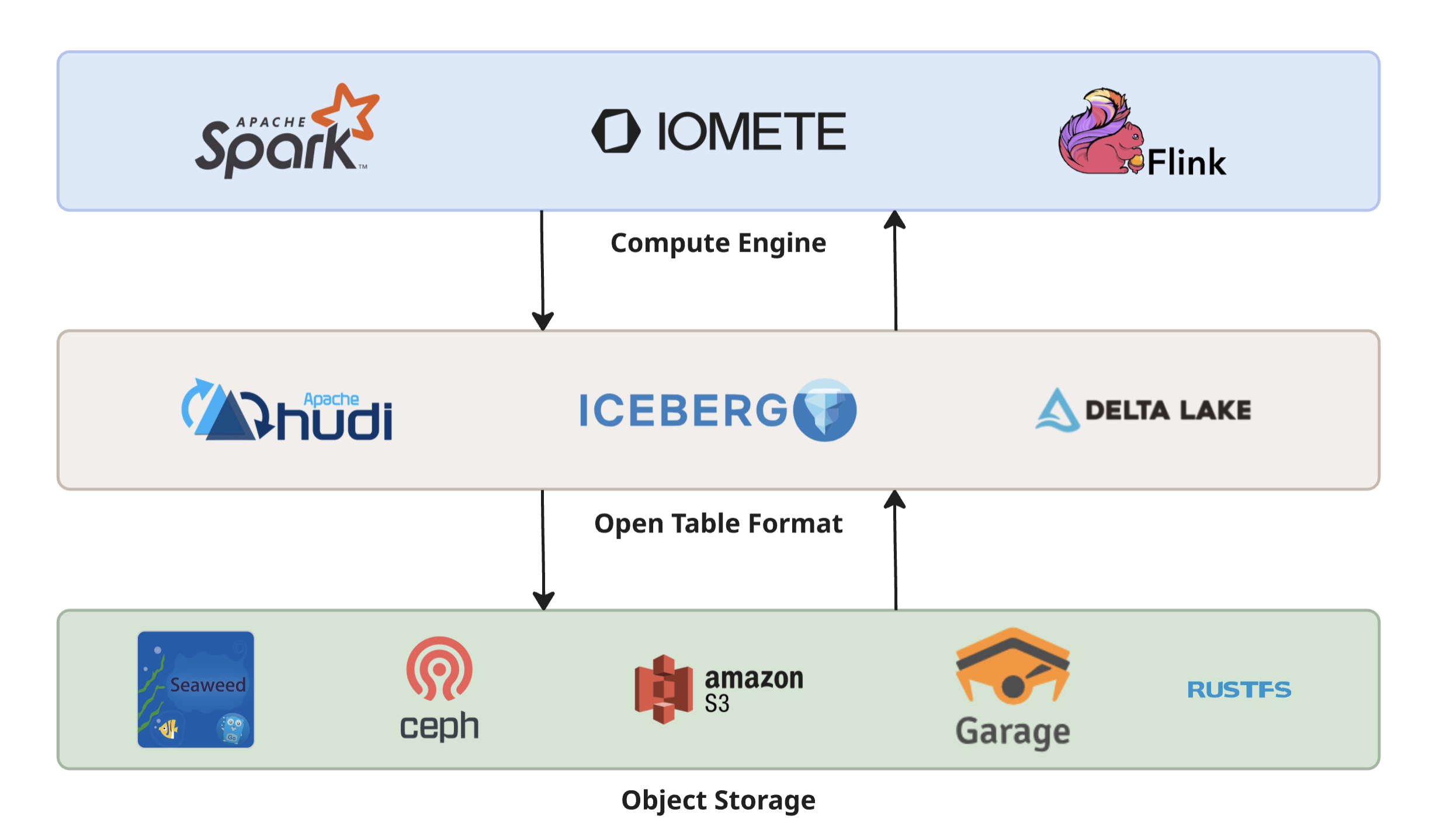
What Makes Object Storage "Lakehouse-Ready"?
Not every S3-compatible object store is suitable for lakehouse workloads. A system that works fine for serving static assets or backing up VMs may fall apart under the access patterns that Iceberg and Spark generate.
Here are the criteria that matter, and why:
S3 API Completeness
Iceberg and the compute engines that sit on top of it use specific S3 API operations. PutObject and GetObject are obvious, but real workloads also depend on:
ListObjectsV2— scanning partitions and listing manifest files- Multipart uploads — writing large Parquet data files
- Conditional writes — atomic commits to the metadata layer
- Versioning — snapshot isolation and time travel
- Server-side encryption (SSE) — data-at-rest encryption for compliance
- Presigned URLs — access delegation without sharing long-lived credentials
An object store that implements 80% of the S3 API will work in demos but will break in production.
Performance Under Lakehouse Access Patterns
Lakehouse workloads are not typical object storage workloads. A Spark job reading an Iceberg table might issue thousands of concurrent GetObject requests across hundreds of executors, each requesting a different byte range of a different Parquet file. Write workloads commit many files atomically. The object store needs to handle high concurrency, mixed read/write loads, and both large sequential reads and small metadata reads efficiently.
Scalability
A lakehouse that starts at 10TB will grow. Historical data accumulates. New data sources get added. Compliance requirements extend retention periods. The object store needs to scale to petabytes and billions of objects without performance degradation or architectural changes.
Durability and Availability
Data loss in a lakehouse is catastrophic. Unlike a database where you can replay transactions from a log, object storage is the source of truth - there's no upstream to recover from. The storage system must survive disk failures, node failures, and even full site outages without losing data. That means it needs built-in redundancy: spreading copies across independent hardware, and ideally across separate physical locations.
Kubernetes-Native Deployment
Most modern on-prem lakehouse deployments run on Kubernetes. The object store should integrate cleanly - through operators, Helm charts, CSI drivers, or a combination. "Works in Docker" is not the same as "operates well in Kubernetes." You need automated scaling, rolling upgrades, persistent volume management, and monitoring integration.
Operational Complexity
A storage system that requires a dedicated team to operate is a different kind of cost than one a platform engineer can manage part-time. The number of components, configuration surface area, failure modes, and upgrade procedures all matter.
Licensing
AGPL, Apache 2.0, LGPL — these aren't just legal details. They affect whether you can embed the storage system in a commercial product, whether you can modify it without open-sourcing your changes, and whether the license can change under you. For most internal lakehouse deployments, any license works. But if you're building a product or managed service on top, permissive licenses (Apache 2.0) give you significantly more freedom than copyleft ones (AGPL).
Community and Longevity
How many active contributors does the project have? Is development concentrated in a single company? Is there a foundation or governance structure? Projects with diverse contributor bases and foundation-level governance tend to survive leadership changes, funding shifts, and strategic pivots. When choosing infrastructure you'll rely on for years, favor projects where no single entity controls the roadmap.
Why MinIO Is No Longer an Option?
For years, MinIO was the default self-hosted S3-compatible object store. Fast, simple, Kubernetes-friendly, and widely adopted across on-prem lakehouse deployments.
Through 2025, the company behind MinIO gradually shifted its focus toward AIStor, a commercial storage product targeting AI workloads. Features were stripped from the community edition, container images were pulled from public registries, and by early 2026 the open-source repository was archived and made read-only. No new features, no community contributions, no guaranteed security patches. The open-source project that built MinIO's developer community is effectively over.
What If You're Already Running MinIO?
If you're already running MinIO in production and it's stable, there's no emergency. The binary still works. Your data is safe. But you're now running software that will receive no new features, no performance improvements, no compatibility updates for newer S3 API extensions, and no community-driven bug fixes. Security patches are evaluated but not guaranteed.
For new deployments, the open-source MinIO is no longer a viable option. And for existing deployments, it's worth starting to plan a migration timeline.
Note: The MinIO team now offers AIStor, a commercial subscription product built on the same foundation. A free single-node tier exists for development, but any production lakehouse deployment requires the paid enterprise subscription for multi-node distributed storage. If you're open to a commercial license and want to stay in the MinIO ecosystem, AIStor is worth evaluating, but it's no longer an open-source option.
Self-Hosted S3 Storage: The Current Landscape
Several actively maintained S3-compatible storage systems exist today. We evaluated four through the lens of lakehouse workloads - looking at S3 API coverage, performance characteristics, Kubernetes integration, operational complexity, and long-term viability.
Ceph RGW (RADOS Gateway)
Ceph is a unified distributed storage platform that provides object, block, and file storage. The RADOS Gateway (RGW) is its S3-compatible object storage interface, built on top of Ceph's RADOS distributed object store.
Ceph is the heavyweight in this comparison, and that's both its greatest strength and its most significant trade-off.
Strengths
Battle-tested at massive scale. Over 1 exabyte of data deployed globally across more than 2,500 production clusters. This isn't a project that works in benchmarks, it's infrastructure that runs production workloads at organizations including CERN (50+ PB), Bloomberg (100+ PB), and DigitalOcean. When we talk about "production-ready," Ceph RGW is the standard other systems are measured against.
Foundation-backed governance. The Ceph Foundation, hosted under the Linux Foundation, includes members like IBM, Bloomberg, DigitalOcean, Intel, and Samsung. Core development is distributed across multiple companies. This is the governance model that protects against the single-company risk that affected MinIO.
Comprehensive S3 API support. RGW implements a mature subset of the S3 API including multipart uploads, versioning, lifecycle policies, server-side encryption, bucket policies, and multi-site replication. The most recent releases (Tentacle v20.2.0, November 2025) added FastEC (2-3x erasure coding performance) and production-ready RGW deployment via Cephadm.
Multi-site replication. Ceph supports active-active multi-site replication with configurable consistency. For lakehouse deployments that span data centers — disaster recovery, geo-distributed analytics, regulatory data residency — this is a differentiator that most alternatives can't match at the same maturity level.
Kubernetes integration via Rook. Rook is a CNCF graduated project that operates Ceph on Kubernetes. It handles deployment, scaling, upgrades, and monitoring. Rook is one of the most mature storage operators in the Kubernetes ecosystem, with years of production use behind it.
Trade-offs
Operational complexity is real. Ceph is not object storage — it's a distributed storage platform that happens to offer object storage. A minimal deployment involves monitors (MON), object storage daemons (OSD), and the RGW gateway. Understanding failure domains, CRUSH maps, placement groups, and recovery behavior requires genuine expertise. Teams that just need an S3 endpoint may find themselves operating far more infrastructure than necessary.
Resource overhead. Ceph's monitors require dedicated resources for consensus. OSDs consume memory proportional to the data they manage. A small Ceph cluster (3-5 nodes) still demands significant CPU, memory, and network resources compared to lighter alternatives.
Overkill for simple deployments. If you need 50TB of S3-compatible storage and nothing else, deploying Ceph is like buying a datacenter to host a website. The platform's power comes with proportional complexity.
Best For
Enterprise deployments at scale (100+ TB), multi-tenant environments, organizations that need block and file storage alongside object storage, and teams that already have Ceph expertise or are willing to invest in it.
SeaweedFS
A fast distributed storage system designed for billions of files. Originally built for blob storage using Facebook's Haystack architecture, it has grown to include S3 API compatibility, POSIX FUSE mounts, WebDAV, and Hadoop integration.
SeaweedFS is the closest thing to a drop-in MinIO replacement that's both production-ready and permissively licensed.
Strengths
O(1) disk seek architecture. SeaweedFS's core design is based on Facebook's Haystack paper. Instead of storing each file as a separate object on disk (which means one disk seek per read), it packs multiple files into volumes. Reading a file requires exactly one disk seek regardless of how many files exist. For lakehouse workloads that scan thousands of Parquet files, this design translates to consistent read performance even as data grows.
Growing production adoption. Kubeflow Pipelines officially adopted SeaweedFS as its default storage backend, replacing MinIO. SmartMore runs it at petabyte scale for AI training data. An enterprise version exists with commercial support. Public case studies are fewer than Ceph's, but the 30k+ GitHub stars and active development signal broad adoption beyond what's publicly documented.
Apache 2.0 license. No copyleft restrictions. You can embed it, modify it, and distribute it in commercial products without open-sourcing your changes. For organizations building products on top of their lakehouse, this matters.
Rich feature set. S3 API with IAM, cloud tiering (transparent offload to S3/GCS/Azure), erasure coding for warm storage, rack-aware replication, automatic compaction, TTL-based expiry, cross-datacenter async replication. It also supports FUSE mounts and WebDAV, which can be useful for non-S3 workloads that coexist with your lakehouse.
Kubernetes support. Official SeaweedFS Operator for orchestrating clusters, plus a CSI driver for Kubernetes persistent volumes. The operator handles scaling, upgrades, and component lifecycle.
Trade-offs
Master-volume architecture. SeaweedFS uses a centralized master server that manages volume assignments. While masters can be replicated for HA, they're a coordination point. The master tracks all volume locations in memory, which works well at moderate scale but adds an operational concern at very large deployments.
S3 API is a secondary interface. SeaweedFS wasn't designed as an S3-compatible object store — it's a distributed file system that added S3 compatibility. The S3 gateway translates S3 operations to SeaweedFS's native Filer API. This works well for common operations, but edge cases in S3 API behavior (conditional writes, specific header handling, exact error codes) may differ from what AWS S3 returns. For Iceberg and Spark, the core operations are well-supported, but it's worth testing your specific workload.
Documentation is functional but not polished. The project wiki on GitHub is comprehensive but occasionally disorganized. Expect to spend time reading source code for advanced configuration. Community support happens primarily through GitHub issues.
Best For
Teams looking for a production-ready, Apache 2.0 licensed, high-throughput alternative to MinIO. Particularly strong for workloads with many small files and for organizations that want cloud tiering (keeping hot data local, cold data in the cloud).
Garage
A lightweight, geo-distributed object store designed for self-hosting. Built in Rust by the French hosting cooperative Deuxfleurs, which has run it in production since 2020 to power their own services.
Garage occupies a unique niche: it's built for small-to-medium self-hosted deployments where simplicity and geo-distribution matter more than raw performance at petabyte scale.
Strengths
Designed for multi-site from day one. Most distributed storage systems treat multi-site replication as an advanced feature. Garage was designed for it as the primary use case. If you have nodes in three different physical locations (offices, edge sites, small data centers), Garage automatically replicates data across them with configurable placement rules. For lakehouse deployments that need to survive a full site failure, this is compelling.
Operationally simple. A Garage node is a single binary. Configuration is a single TOML file. There's no separate metadata service, no consensus cluster to manage (it uses a Raft-like protocol internally), no complex tuning. A three-node cluster can be set up in under an hour. For teams without dedicated storage engineers, this simplicity has real value.
Minimal resource footprint. Garage is self-contained and lightweight, designed to run on modest hardware, even consumer-grade machines at home. For edge deployments or budget-constrained environments, the resource requirements are significantly lower than Ceph or SeaweedFS.
Production-proven at small scale. Deuxfleurs has run Garage in production since 2020 for their own hosting services, and Triplebit, a non-profit hosting provider, uses it for static site hosting and Mastodon media storage. The user base is small, no large enterprise deployments are publicly documented; but for the self-hosted niche it targets, it's proven and stable.
Kubernetes support. Helm charts for standard deployment, multiple community-developed operators (dimedis-gmbh/garage-operator, rajsinghtech/garage-operator), and experimental COSI (Container Object Storage Interface) driver support.
Trade-offs
Not designed for petabyte scale. Garage is optimized for small-to-medium workloads — think tens of terabytes, not hundreds. If your lakehouse will grow past 50-100TB, you'll likely hit scaling limits. The project documentation is transparent about this.
AGPL-3.0 license. The AGPL requires that if you modify Garage and provide it as a service, you must release your modifications. For organizations that embed storage in their own products, this may be a blocker. For pure internal use, it's typically fine — but check with your legal team.
Smaller community. At 2.8k GitHub stars and a core team at Deuxfleurs, the contributor base is small. Development is active but moves at a pace proportional to team size. If you need a feature that doesn't exist, you're more likely to need to build it yourself.
S3 API coverage is narrower. Garage implements the core S3 operations but doesn't cover the full API surface. Versioning support, lifecycle policies, and some advanced features may be incomplete. For basic Iceberg read/write workloads this is likely sufficient, but test thoroughly before committing.
Best For
Small-to-medium self-hosted deployments (under 50TB), teams with nodes in multiple physical locations, edge computing scenarios, and organizations that prioritize operational simplicity over maximum throughput.
RustFS
A high-performance S3-compatible object store built in Rust, explicitly positioning itself as the open-source successor to MinIO. The project emerged in response to MinIO's maintenance mode announcement.
RustFS is the most direct MinIO replacement on this list. It's also the one that requires the most caution.
Strengths
Purpose-built as a MinIO replacement. RustFS doesn't try to be a general-purpose storage system. It's specifically designed to fill the gap MinIO left: a fast, simple, S3-compatible object store that runs on commodity hardware. It supports MinIO Client compatibility, making migration from MinIO straightforward via standard S3 tools.
Strong small-object performance. Benchmarks show RustFS achieving 2.3x the throughput of MinIO for 4KB objects. For metadata-heavy Iceberg operations (reading manifests, listing partitions), small-object performance matters. Rust's zero-cost abstractions and memory safety make this performance sustainable without the garbage collection pauses you'd see in Go or Java-based systems.
Apache 2.0 license. Permissive licensing with no copyleft obligations. Combined with the MinIO migration path, this makes it attractive for organizations looking for a license-compatible successor.
Growing fast. 21.5k GitHub stars in a short time reflects genuine community interest. The project includes enterprise features like versioning, bucket replication, event notifications, bitrot protection, and observability integration (Prometheus, Grafana, Jaeger).
Kubernetes support. Helm charts available via charts.rustfs.com with multi-architecture container support.
Trade-offs
Not production-ready. Key features including distributed mode, lifecycle management, and KMS are marked "Under Testing" in the project's own README. For any lakehouse deployment beyond a single node, this is a blocker. Distributed mode is under active testing. The project explicitly warns that it has not survived the "thousand edge cases" that production workloads generate. For a lakehouse storage layer where data loss is catastrophic, this is a significant concern.
Large-object performance lags. Community benchmarks show MinIO roughly 2x faster for 20MB+ objects. Optimizations are underway, but lakehouse workloads mix small metadata files with large Parquet files and both need to be fast.
Young project. With 2.3k commits, the codebase is a fraction of the size and maturity of Ceph (158k commits) or SeaweedFS (12.9k commits). Edge cases in S3 API compatibility, failure recovery, data corruption handling, and upgrade procedures are areas where maturity only comes from time and production exposure.
Bus factor risk. As a newer project without foundation backing, the same governance concerns that affected MinIO apply here. The project's long-term trajectory depends on its community and business model evolving sustainably.
Best For
Dev/test environments and evaluation. The closest architectural successor to MinIO, but not production-ready today. Worth revisiting as the project matures over the next 6-12 months.
Side-by-Side Comparison
Here's how the five options compare across the evaluation criteria that matter for lakehouse deployments:
| Criteria | MinIO | Ceph RGW | SeaweedFS | Garage | RustFS |
|---|---|---|---|---|---|
| S3 API completeness | Excellent | Very good | Good | Basic-good | Good |
| Read/write throughput | Excellent | Very good | Excellent | Moderate | Good (small obj), Moderate (large obj) |
| Max practical scale | Petabytes | Exabytes | Petabytes | Tens of TB | Petabytes (claimed, unvalidated) |
| Durability mechanisms | Erasure coding, replication | Erasure coding, multi-site replication | Erasure coding, rack-aware replication | Multi-site replication | Erasure coding, bitrot protection |
| Kubernetes | Operator (legacy) | Rook (CNCF graduated) | Operator + CSI | Helm + community operators | Helm charts |
| Ops complexity | Low | High | Medium | Low | Low |
| License | AGPL-3.0 (archived) | LGPL 2.1/3.0 | Apache 2.0 | AGPL-3.0 | Apache 2.0 |
| Production maturity | Archived | Very high | High | Medium | Not production-ready |
| Governance | Single company (archived) | Linux Foundation | Single maintainer | Cooperative (Deuxfleurs) | Community (early) |
| Active development | No | Yes (very active) | Yes (active) | Yes (active) | Yes (very active) |
Hardware-Based S3-Compatible Storage Appliances
Not every organization wants to run a software-defined storage system. Some prefer to buy storage as an appliance, hardware with S3 compatibility built in, managed by the vendor.
Common options include:
- Pure Storage FlashBlade — Flash-based storage with S3 API support, designed for high-performance analytics and AI workloads.
- Dell ObjectScale (formerly ECS) — Enterprise object storage with S3 API, multi-site replication, and integrated data protection.
- NetApp StorageGRID — Software-defined object storage that runs on NetApp hardware or commodity servers, with strong S3 compliance and information lifecycle management.
When this makes sense:
- Your organization has an existing hardware vendor relationship with enterprise support contracts.
- You don't have (or want) a team managing storage infrastructure software.
- Budget for capex hardware investment is available and preferred over opex engineering time.
- Regulatory or compliance requirements mandate vendor-supported storage with SLAs.
When it doesn't:
- You need the flexibility to run on commodity hardware or cloud VMs.
- You're building on Kubernetes and want storage that's managed like any other workload.
- You need to scale incrementally rather than in hardware-purchase increments.
- License and vendor lock-in are concerns.
For lakehouse deployments, hardware-based S3 storage works well as the bottom layer — the lakehouse doesn't care whether its S3 endpoint is backed by software or an appliance. The trade-off is purely operational and financial.
Which S3-Compatible Storage Should You Choose?
There's no single best option. The right choice depends on your scale, team, existing infrastructure, and tolerance for operational complexity.
You're already running MinIO and it's stable → No rush to migrate, but start evaluating. SeaweedFS is the closest drop-in replacement in terms of simplicity and feature coverage. Begin testing it alongside your existing MinIO deployment.
Enterprise scale, 100+ TB, multi-tenant, multi-site → Ceph RGW. Nothing else on this list matches its maturity at scale. If you have (or can hire) Ceph expertise, and you need block or file storage alongside object storage, Ceph is the only option that doesn't require running multiple systems.
Mid-scale, Apache 2.0 required, high throughput → SeaweedFS. Production-proven, permissive license, good Kubernetes support, and the O(1) seek architecture is a genuine advantage for file-heavy Iceberg workloads.
Small team, multiple locations, simplicity above all → Garage. If your lakehouse is under 50TB and you value operational simplicity over maximum performance, Garage is the lightest-weight option. Especially compelling for edge or multi-site deployments.
Looking for the "next MinIO" → Watch RustFS. The project has momentum and the right architecture (Rust, Apache 2.0, MinIO migration tooling), but it's not production-ready today. Set a reminder to re-evaluate in 6-12 months. In the meantime, deploy something proven.
No ops team, budget available → Consider hardware appliances (Pure FlashBlade, Dell ObjectScale, NetApp StorageGRID). Let the vendor handle storage operations while your team focuses on the lakehouse itself.
IOMETE and S3-Compatible Storage
IOMETE's lakehouse platform is storage-agnostic. It works with any S3-compatible backend - whether that's Ceph RGW in your data center, SeaweedFS on Kubernetes, a hardware appliance, or a cloud-managed service like AWS S3.
This is by design. The storage layer is the one piece of infrastructure that should outlast any platform decision. By building on the S3 API as the standard interface, IOMETE ensures that your choice of object storage doesn't lock you into a specific compute platform and your choice of compute platform doesn't lock you into specific storage.
Frequently Asked Questions
What is S3-compatible object storage?
Why does object storage matter in a data lakehouse?
What makes object storage lakehouse-ready?
How do you choose self-hosted object storage for an on-premises lakehouse?
What happens to lakehouses that relied on an archived object store?
If you're evaluating object storage for a self-hosted lakehouse deployment, get in touch — we've helped teams navigate this decision across a range of scales and infrastructure constraints.