How to build secure data processing architecture?

Financial Services, Health Care Services, and Government organizations deal with lots and lots of data on a regular basis. But these industries are highly regulated as well, so they need to be very careful with their data setups. In this blog, I'll share my practices based on my experience in a couple of financial organizations.
Secure data processing architecture
In order to serve the security purposes of the data, the data sometimes doesn’t move from the On-Prem / Private Data centers into the cloud to take advantage of the awesome tools such as Snowflake / Databricks, etc.
Even when they push the data into the cloud, the data goes through a security-first setup with Demilitarized Zone (DMZ) in between before it hits the VNet of the client from the service provider. DMZ is set up as a spoke in a Hub-Spoke architecture for the network. So all communication goes from spoke to Hub to spoke where other resources are going to stay. Hub is used to monitor the data packets coming from the external world and then go through the firewall to review for any abnormal packets.
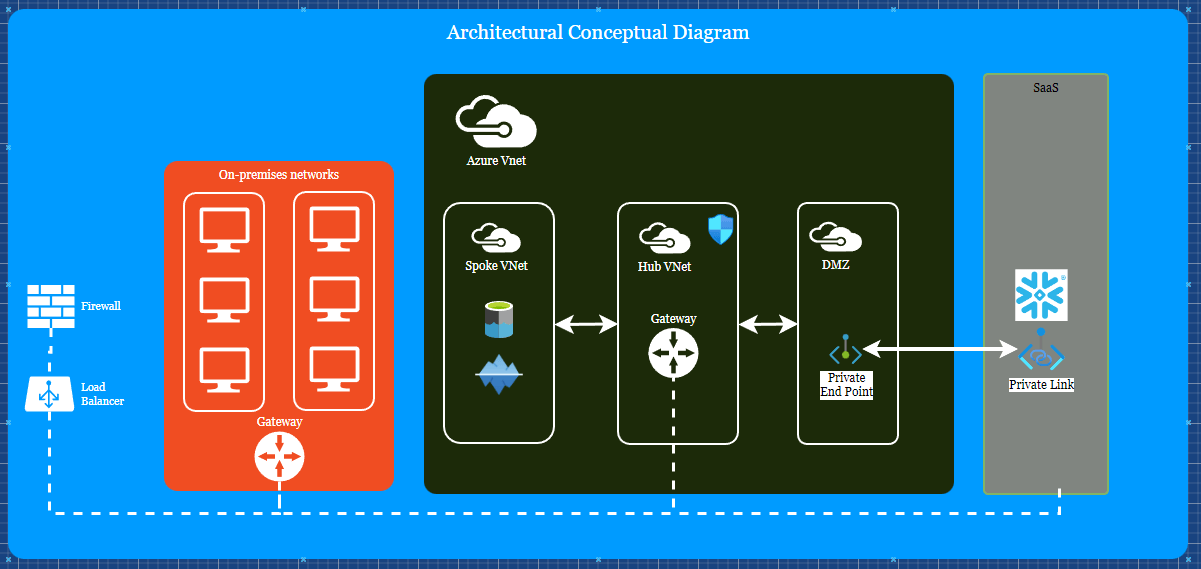
The above architecture is based on real-world scenarios in several financial organizations to which the author has worked and had exposure.
The architecture has three significant impacts:
- Data needs to travel through several Networks before it can be a process
- Adding Latency (albeit minimal due to backbone setups, if done correctly)
- Adding cost for each hop on the network (this can be avoided using a single VNet and subnets, but that won’t provide the required security setup)
- Real decoupling of the data and processing is no longer possible
- No use in storing the data in an Iceberg / Delta format
- Processing layers wait on each other to process data
- On-Prem / Private Datacenter data is not really processed
Ingress/Egress charges on data analysis
The above challenges don’t look immediately in the face when the client is onboarding. But he sees his Snowflake or similar SaaS solution costs are skyrocketing. It’s because of how the network is set up and delivered to create value. This can be a similar situation with Confluent Kafka or any other SaaS storing the data. Confluent Kafka adds one more challenge the data ingress and egress are charged not just egress. Snowflake while it communicates to be open with Iceberg format, is only probably really ready in 2024 - 2025 as its native format.
Secure data processing without migration
IOMETE provides a clean solution to using Open Table Iceberg format while storing the data in your own Data Lake storage for processing the data. Processing is happening on the VMs orchestrated inside your VNet rather than outside. Provides an intuitive interface for querying the data. For making an open, managed, and SUSTAINABLE solution look forward to IOMETE.