Federated query: how it works and when to use it

Most enterprise data isn't in one place, and pretending otherwise is what causes ETL bills to run away. A typical setup has transactional data in PostgreSQL or Oracle, historical data in an Iceberg lakehouse, customer records in a CRM, log data sitting in S3, and a few warehouses no one quite has the political capital to retire. When a question comes in that needs all of it, the default answer for the last twenty years has been the same: build a pipeline, copy the data somewhere central, schedule it, monitor it, fix it when it breaks at 3 a.m.
Federated query proposes a different deal. Leave the data where it lives, push the SQL out to it, and assemble the answer at query time. It's not a new idea, but the constraints around it have shifted. Data residency rules now have teeth. Storage and egress costs are no longer rounding errors. AI workloads need access to operational data without a 24-hour lag. So the question of when federation is actually the right tool, and when it's the wrong one, is worth getting right.
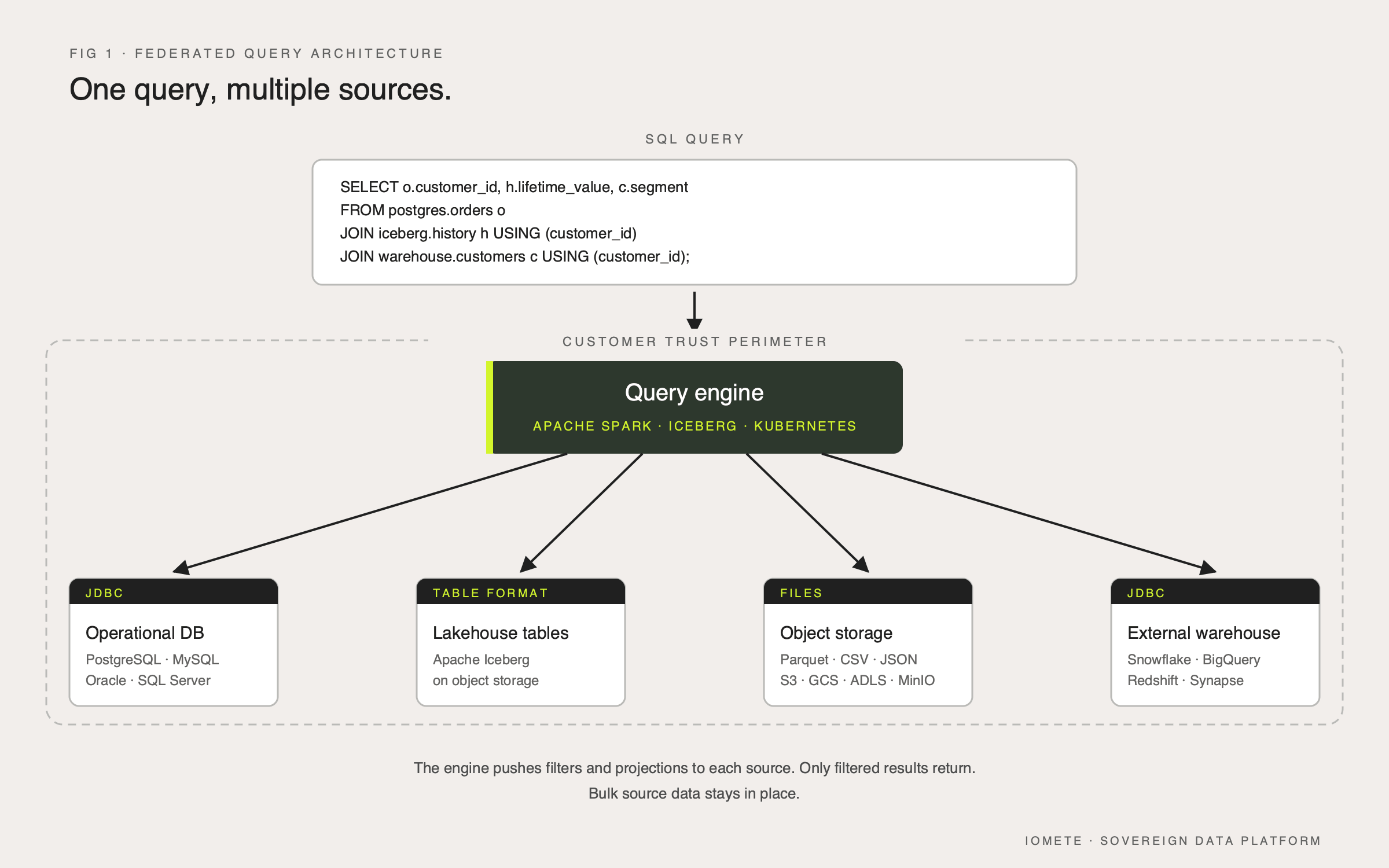
What a federated query actually is
A federated query is a single SQL statement that pulls data from more than one underlying system, joins or aggregates it, and returns a unified result, without first physically copying the source data into a central store. The query engine handles the complexity: parsing the SQL, deciding which clauses can run on each remote system, pulling back the partial results, and stitching them together.
Two related ideas often get conflated with federation, and the distinction matters in practice.
Data virtualization is the broader umbrella. It includes federated query but also wraps semantic layers, virtual datasets, caching tiers, and governance. Products in this category tend to position themselves as a permanent abstraction layer over your data estate.
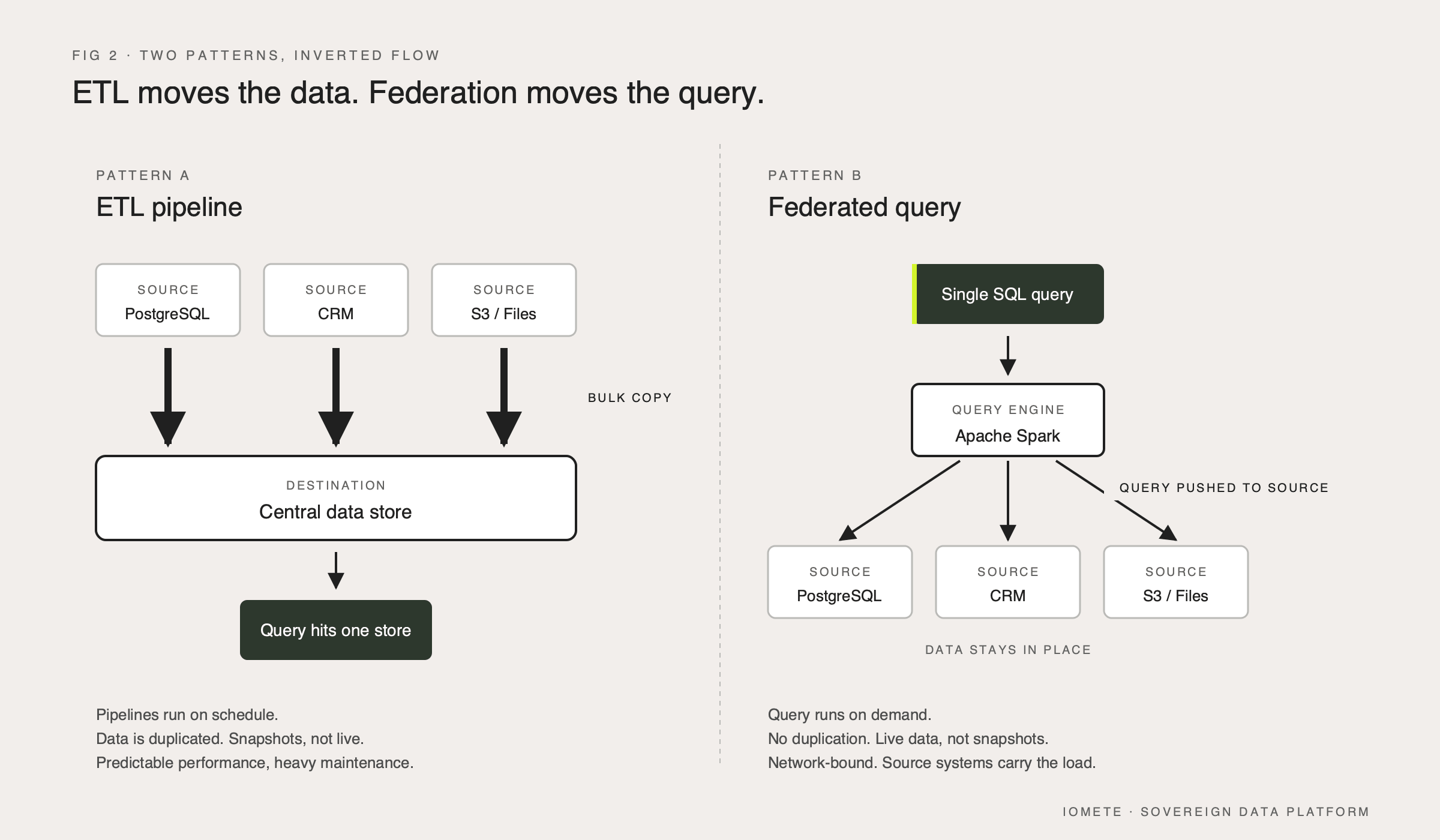
ETL or ELT pipelines physically move data into a target system on a schedule. Once landed, queries hit a single store. This gives you predictable performance and full optimizer control, at the cost of duplication, latency, and the operational burden of the pipelines themselves.
Federated query sits between them. It's lighter than full virtualization, and it gives you live data instead of last night's snapshot. But it pushes work onto remote systems and assumes those systems can keep up.
How it works under the hood
The mechanics are less mysterious than the marketing usually suggests. A federated query engine needs four things to work:
A connector for each source system that knows how to translate SQL into the dialect or API that system understands. JDBC drivers, REST clients, S3 file readers, and Iceberg catalog readers are all examples.
A planner that can decompose an incoming query, work out which predicates and projections can be pushed down to each source, and which operations have to happen in the central engine. Pushing a WHERE clause to PostgreSQL is cheap; pulling 200 million rows back to filter them in the engine is not.
A runtime that can execute the remote calls in parallel, handle retries and timeouts, and assemble the partial results into the final shape.
A metadata layer that knows what tables exist where, what their schemas look like, and how to authenticate against each source.
In Apache Spark, this pattern is implemented through the Spark JDBC data source and a wider set of file format connectors. You register an external table that points to a remote source, and from that point on it behaves like any other table in the catalog. A query that joins it with an Iceberg table becomes a single logical plan, with predicate pushdown happening automatically where the connector supports it.
When federated query is the right tool
Federation earns its place in a few clear scenarios.
Operational analytics over fresh data. A dashboard that needs current order data from PostgreSQL joined with historical purchase patterns from your lakehouse can't wait for an overnight pipeline. Federation gives you live joins without the engineering team building yet another CDC stream.
Avoiding duplication of high-churn or low-value data. If a table is small and queried rarely, copying it into the lakehouse is overhead with no payoff. Federate it.
Data residency constraints. This is the underrated case. If a dataset is legally required to stay inside a specific jurisdiction or a specific tenant's storage, you cannot ETL it out. You can, however, push a query into that environment, run it under that tenant's governance, and pull only the aggregated result back. We covered this pattern in more depth in data lakehouse architecture in 2025, where the control plane question becomes architecturally important.
Migration off legacy systems. A federated query is often the first step before a full migration. You make the legacy data queryable from your modern engine, decommission BI workloads against the old system, and then move the data on a schedule that suits the business rather than the urgency of the cutover.
Where federated query falls apart
It's also worth being honest about the limits, because they're real.
Network is the bottleneck. Every byte that crosses between the engine and the source system has to traverse a network. If a query needs to scan a 500GB Postgres table, federation will not save you. The query will time out, or it will saturate the source database, or both.
Cost-based optimization across systems is weak. A central engine doesn't have full statistics on remote sources. It doesn't know how a Postgres index will behave, or how Snowflake's micro-partitions are laid out today. So join order, partition pruning, and predicate pushdown are best-effort. Complex multi-source joins often run worse than the planner expects.
Connector quality is uneven. A Postgres JDBC driver is mature and well-tested. A connector to a niche SaaS API is probably someone's side project. The weakest connector in your federation graph sets the ceiling for what you can reliably build.
Source systems carry the load. If federation puts production OLTP databases under analytical query pressure, the people who own those databases will eventually have something to say about it. Federation is not free for the source.
The honest framing is this: federation is a precision tool. It works well for surgical queries that touch small slices of remote data, and it works poorly as a substitute for a properly designed data platform.
The lakehouse-as-federation-hub pattern
A pattern that has settled in over the last few years is to use the lakehouse as the federation hub rather than as a destination for everything. The logic runs like this.
Most analytical work belongs in the lakehouse, on tables managed in Apache Iceberg or a similar open format. Iceberg gives you ACID transactions, time travel, schema evolution, and the kind of partition-aware metadata that makes large-scale queries fast. That's where the bulk of your processing should live.
But not every dataset belongs there. Operational tables that change every second, third-party SaaS data behind an API, datasets pinned to a specific jurisdiction, files dropped into S3 by an upstream system that you don't fully control. For those, federation from inside the lakehouse engine is the lower-friction option.
This is what makes Apache Spark a useful federation engine specifically. It's already the compute layer for the lakehouse, so you don't need a second tool. It speaks JDBC, it reads Parquet, JSON, CSV, and Avro from object storage natively, and it has Iceberg integration as first-class behavior. A single SQL query can pull from all of them.
How IOMETE approaches federated query
This is where IOMETE's architecture becomes relevant rather than incidental. IOMETE is a sovereign data platform built on Apache Spark, Apache Iceberg, and Kubernetes, deployed inside your own infrastructure. Federated query is part of the platform out of the box, not a bolted-on connector.
The mechanics are straightforward. A JDBC source becomes a queryable table with a single DDL statement:
CREATE TABLE postgres_orders
USING org.apache.spark.sql.jdbc
OPTIONS (
url "jdbc:postgresql://db_host:5432/orders_db",
dbtable "public.orders",
user "service_user",
password "***"
);
From that point on, postgres_orders behaves like any other table in the catalog. You can join it with an Iceberg table that holds three years of historical orders, with a CSV file dropped into S3 by an upstream system, with a JSON file representing reference data, in a single SQL statement. The full reference for this pattern lives in the IOMETE query federation documentation, with concrete examples for MySQL, PostgreSQL, and object storage formats.
The architectural piece that matters more than the SQL itself is where the federation engine runs. In a managed SaaS lakehouse, your federated query is executed inside the vendor's environment, which means your source credentials, your query patterns, and any cached results pass through their control plane. In IOMETE's self-hosted architecture, the engine runs on your Kubernetes cluster, against your network policies, with your audit logs. Federation becomes an architectural pattern that respects the trust perimeter rather than punching a hole through it.
Federation under compliance constraints
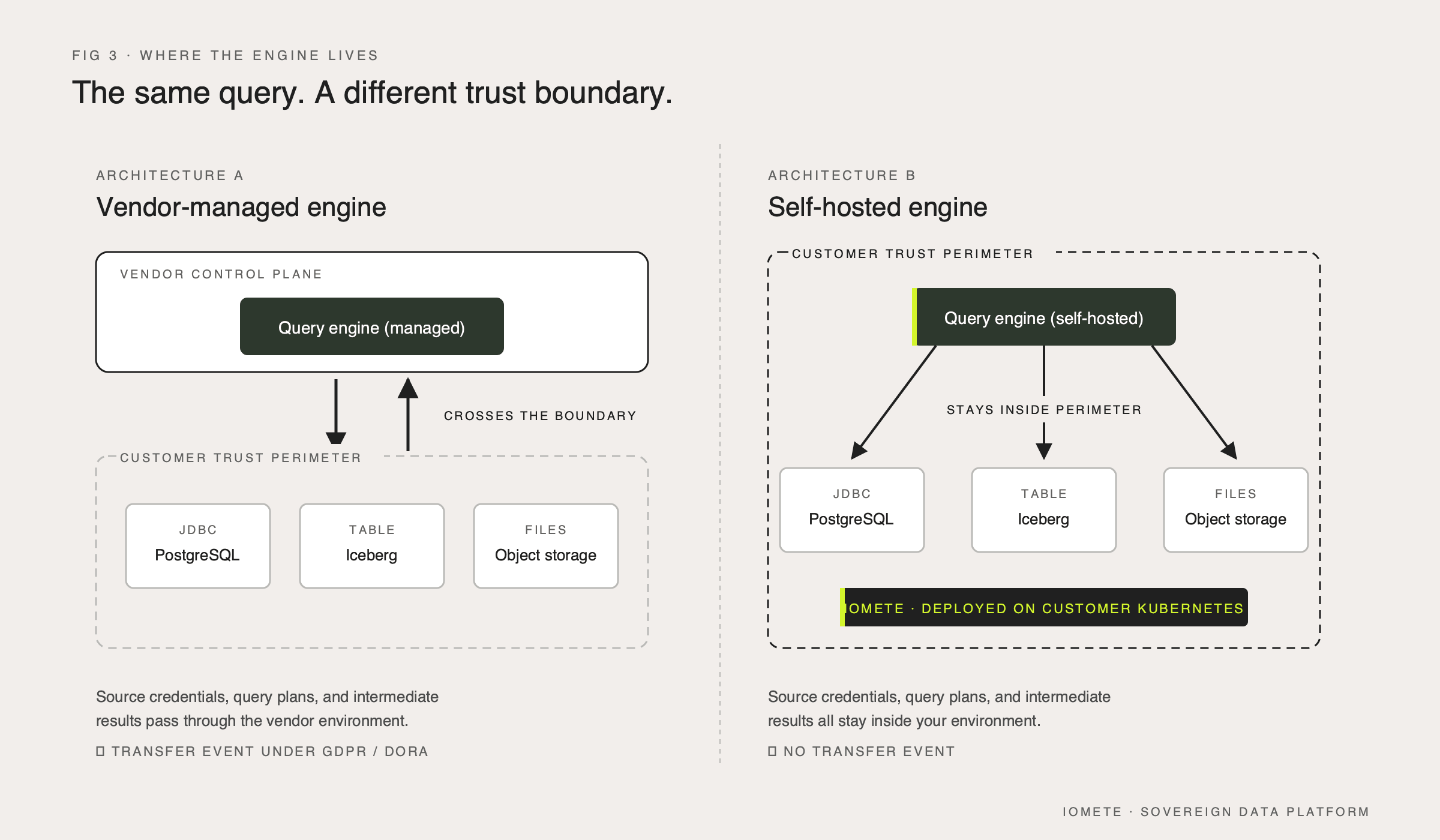
For regulated environments, this distinction is the difference between a legal data flow and a non-compliant one. GDPR Article 32 requires demonstrable control over the systems that process personal data. DORA's ICT risk framework, in force across EU financial institutions since January 2025, requires that critical operational data and the infrastructure it runs on stay under the financial entity's control. We've written more on the architectural implications of this in data lakehouses for regulated enterprises.
A federated query that pulls EU customer data through a US-managed control plane creates a transfer event, regardless of whether the bytes "stay in the EU region." The processing happens elsewhere. A federated query that runs entirely inside a self-hosted engine, against sources inside the same trust boundary, does not.
This is why architecture matters more than feature parity. Most platforms can run a federated query. The question is where the engine sits while it runs one.
What to actually do with this
If you are evaluating federated query for an enterprise data platform, three questions are worth asking before any vendor demo.
First, what proportion of your workloads genuinely benefits from live joins versus what could be solved with a well-designed Iceberg pipeline? Federation gets oversold; most analytical workloads should still land in the lakehouse.
Second, where does the federation engine itself execute, and does that location match your compliance and cost-control posture? A federated query that crosses a trust boundary is a transfer, not a query.
Third, are the connectors you actually need to use mature, or are you depending on something maintained by one engineer somewhere? The weakest connector defines the reliability of the system.
Federation, used surgically, removes a real class of pipeline work. Used as a default architecture, it pushes operational risk into places it doesn't belong.
If you'd like to talk through how this fits a specific environment, our team handles these conversations directly: iomete.com/contact-us.
FAQs
Frequently Asked Questions
What is a federated query?
A federated query is a single SQL statement that pulls data from multiple separate source systems, joins or aggregates it, and returns a unified result without first copying the source data into a central store.
The query engine handles the orchestration: parsing the SQL, pushing supported predicates down to each remote source, executing the remote calls, and stitching the partial results together. Sources can include relational databases, object storage files, lakehouse tables, and SaaS APIs, as long as a connector exists.
In IOMETE deployments, federation runs through Apache Spark against JDBC sources, Iceberg tables, and object storage files in the same SQL statement, with the engine executing on the customer's Kubernetes cluster.
How is federated query different from ETL?
ETL physically copies data from sources into a target system on a schedule, after which queries hit only the target. Federated query leaves the data in place and runs the query against the sources at execution time.
The trade-off is direct. ETL gives you predictable performance, full optimizer control, and snapshot consistency, at the cost of pipeline maintenance, storage duplication, and data latency. Federation gives you live data and no duplication, at the cost of network dependency, weaker cross-system optimization, and load on the source systems.
Organizations running IOMETE on Kubernetes typically use federation for live operational joins against transactional databases, while the bulk of analytical work runs on Iceberg tables managed inside the lakehouse.
Does a federated query move data?
Yes, but selectively. A federated query moves only the rows and columns the source returns after applying any pushed-down filters. The bulk of the source dataset stays in place.
Network transfer volume depends on how well the engine can push predicates and projections down to the source. A poorly-pushed query that returns millions of unfiltered rows defeats the point of federation. Connector quality and source-system optimizer behavior both matter here.
In IOMETE-hosted environments, predicate pushdown is handled by Spark's data source API, and the query plan is visible in the SQL editor so engineers can confirm what actually gets pushed before running large jobs.
What does data sovereignty actually mean in practice?
Data sovereignty is not the same as data residency. Residency is about where the bytes are stored. Sovereignty is about who controls the infrastructure that stores and processes them.
In practice, sovereignty requires three conditions: the data lives on storage the organization controls; the compute engine that processes it runs in an environment the organization controls; and encryption keys, IAM, and audit logs all stay inside that environment. A managed cloud service can satisfy residency through region pinning while still violating sovereignty if the control plane sits in another jurisdiction.
Organizations running IOMETE on their own Kubernetes clusters keep both the storage and the processing engine inside the controlled environment, which is the operational baseline that most sovereignty mandates assume.
Can self-hosted lakehouses handle the same scale as managed cloud warehouses?
Yes. The engines underneath managed cloud warehouses and self-hosted lakehouses share most of the same open-source primitives: Apache Spark for compute, Apache Iceberg for table format, object storage for data. The difference is operational responsibility, not scale ceiling.
Multi-petabyte Iceberg tables run on the same Spark execution model whether the cluster is hosted by a vendor or operated on customer infrastructure. The trade-off is real, but it sits in who runs the platform rather than in what the platform can handle.
IOMETE deployments run production analytical workloads on customer-operated Kubernetes clusters at multi-petabyte scale using the same Spark and Iceberg components, with field engineering support available for organizations that prefer not to operate Kubernetes themselves.
How do you handle compliance in a self-hosted environment?
Compliance in a self-hosted lakehouse uses the same controls as compliance for any other internal system: IAM integration with the organization's identity provider, audit logging into a customer-owned log store, network policies that restrict egress, and encryption keys held in a customer-managed KMS or HSM.
The audit advantage compared to a managed cloud service is direct evidence. Every component runs inside the regulated environment, so compliance teams can demonstrate processing-infrastructure control to auditors from systems the organization already operates, rather than depending on vendor SOC reports or sub-processor disclosures.
In IOMETE deployments, audit logs, encryption keys, and IAM integration all run inside the customer's Kubernetes namespace, which is how DORA, GDPR Article 32, NIS2, and EU AI Act evidence requirements are typically met.
Can a data platform run in air-gapped environments?
Yes, if it was architected for it. Air-gapped operation requires container images mirrored to a customer-controlled registry, no outbound telemetry or license-check traffic, an offline catalog and metadata store, and a deployment path that does not depend on public package repositories at runtime.
This is a structural property of the platform, not a configuration toggle. Platforms whose control plane runs in a vendor's cloud cannot operate air-gapped by definition. Platforms whose components all deploy from customer-controlled registries can.
IOMETE supports air-gapped Kubernetes deployments where container images, catalog state, and storage credentials all stay inside the customer's disconnected environment, which is the operational pattern used in government, defense, and critical-infrastructure deployments.
What are the performance limits of federated query?
Federated query performance is bounded by the network between the engine and each source, the optimizer's ability to push predicates and projections down to the source, and the throughput of the source system itself.
Queries that scan large remote tables, perform aggregations the source cannot push down, or join multiple high-volume remote sources tend to run poorly. Federation works best for surgical queries that touch small filtered slices of remote data and join them against locally optimized lakehouse tables. For bulk analytical work, loading into the lakehouse is almost always the better answer.
In IOMETE production deployments, federation is typically reserved for operational joins against transactional databases and reference data lookups, while the heavy analytical workload runs on Iceberg tables inside the lakehouse.