Column-Level Data Masking at Scale: Automating Tags Across Thousands of Columns

Imagine a healthcare organization runs an internal HIPAA audit. Their data estate: 847 Iceberg tables and roughly 14,000 columns. The audit finds 340 columns containing Protected Health Information: patient names, diagnosis codes, dates of birth, insurance identifiers. None of them are masked. The masking configuration for their platform was built when they had 30 tables. Nobody updated it as the estate grew.
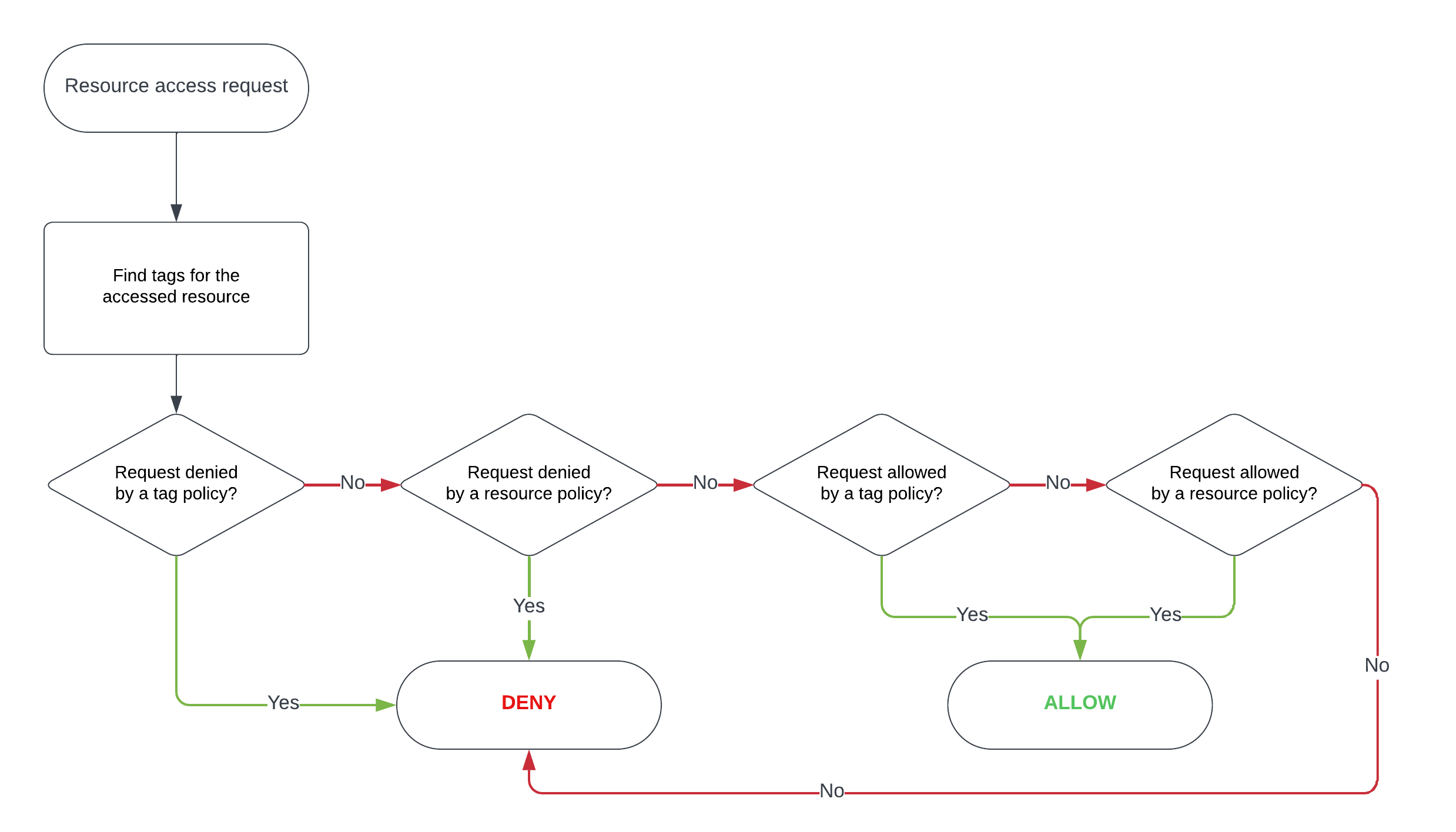
This isn't a governance failure. It's a scaling failure. Manual, column-by-column masking is the only model most platforms expose, and it breaks down around the 50-table mark. The question for regulated industries isn't "can your platform mask a column?" Every platform can do that. The real question is "can your masking policy follow your data as it grows?"
The Problem With Manual Column Masking
When a data team first implements column-level security, the surface area feels manageable. You have a handful of tables, a list of sensitive columns, and you configure masking policies for each one. An analyst runs a query against patients.contact_info; the email and phone_number columns return masked values. The configuration is correct and the audit passes.
Then three things happen:
New tables get added. A new intake system produces a patient_intake table. It has a social_security_number column. The team building the pipeline knows it's sensitive, but they're not the data security team. The policy doesn't follow the table automatically, so the column sits unmasked until someone notices, or until the next audit.
Schemas evolve. An existing table adds a guardian_contact_number column in a schema migration. The masking policy for that table was created against a specific column list. The new column isn't covered. It doesn't need a separate incident; it just needs a schema change that nobody thought to cross-reference against the policy registry.
Teams proliferate. The original masking configuration covered a single domain's tables. When a new business domain onboards, they bring their own tables, their own naming conventions, and, unless someone explicitly runs them through the security review process, their own ungoverned columns.
At scale, this creates a compliance gap that's structural, not accidental. The right architecture isn't more thorough manual review. It's policies that propagate automatically when data is classified.
The Tag-Based Model: Classify Once, Enforce Everywhere
Tag-based masking inverts the policy relationship. Instead of asking "which columns in this table need masking?" for every table, you ask "which classification does this column belong to?" and the policy for that classification enforces itself.
The model has three parts:
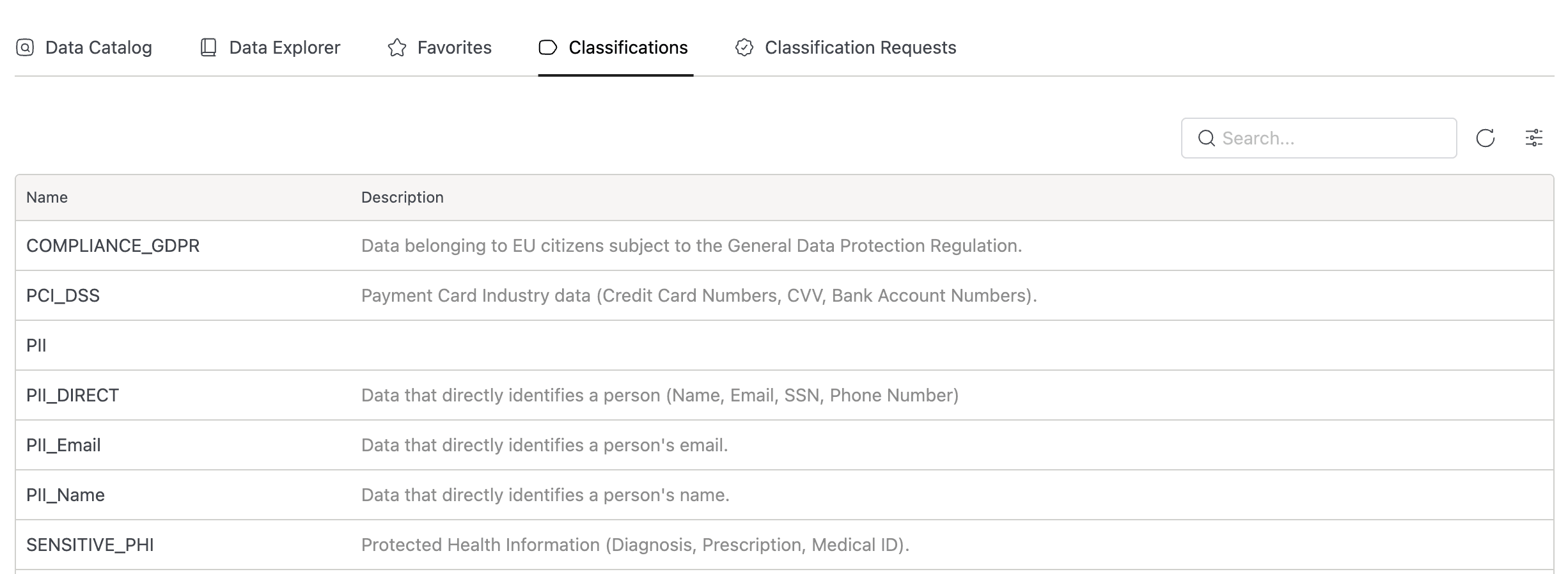
Classifications are tags that describe what the data is: PII, PHI, PCI-DSS, GDPR-Subject, CONFIDENTIAL. They live in your data catalog, attached to columns and tables. They're the semantic layer; they carry meaning about the data's nature and regulatory obligation, not about who can see it.
Tag-based masking policies attach masking behavior to classifications, not to specific tables or columns. A policy that says "mask all columns tagged PHI for users not in the clinical-staff group" covers every PHI-tagged column in your entire data estate, present and future.
Classification assignment is the point of governance control. You need a workflow that ensures columns get classified when they're created or discovered, and that the assignment is reviewed rather than arbitrary. Once a column is classified, masking flows automatically.
The result: an organization with 14,000 columns doesn't need 14,000 masking policy entries. They need a manageable set of classification tags, a clean process for assigning them, and tag-based policies that enforce consistently across everything tagged.
The Infrastructure Control Question
Column-level masking is a solved problem at small scale. The harder question, especially for regulated industries, is where enforcement actually happens.
When masking is enforced at a vendor's managed query layer, it applies to traffic that flows through that layer. Queries that take a different path (a direct storage read, a secondary engine, a batch job outside the managed environment) may not be covered unless additional controls are configured separately. For organizations operating under DORA, GDPR, or HIPAA, this matters: the compliance question isn't just whether masking exists, it's whether masking is enforced consistently regardless of how data is accessed.
Self-hosted deployment changes this. When the policy engine runs inside your own infrastructure, enforcement is tied to the compute cluster itself, not to a specific access path. Any query processed by that cluster goes through the same policy check. There's no vendor control plane involved, which also simplifies the third-party ICT risk picture for DORA-regulated institutions.
IOMETE's Architecture: Tag-Based Masking Inside Your Infrastructure
IOMETE is built on Apache Ranger's policy framework, extended and simplified through an API and UI that makes tag-based governance operationally practical.
The key components work together:
Data Catalog with Classification Tags. The Data Catalog supports column-level and table-level classification tags. Tags are governed: assignment goes through an approval workflow (request, review, approve or reject) that creates an audit trail of every classification decision. When a column is tagged PHI after an admin reviews and approves the request, that decision is documented with justification and timestamp.
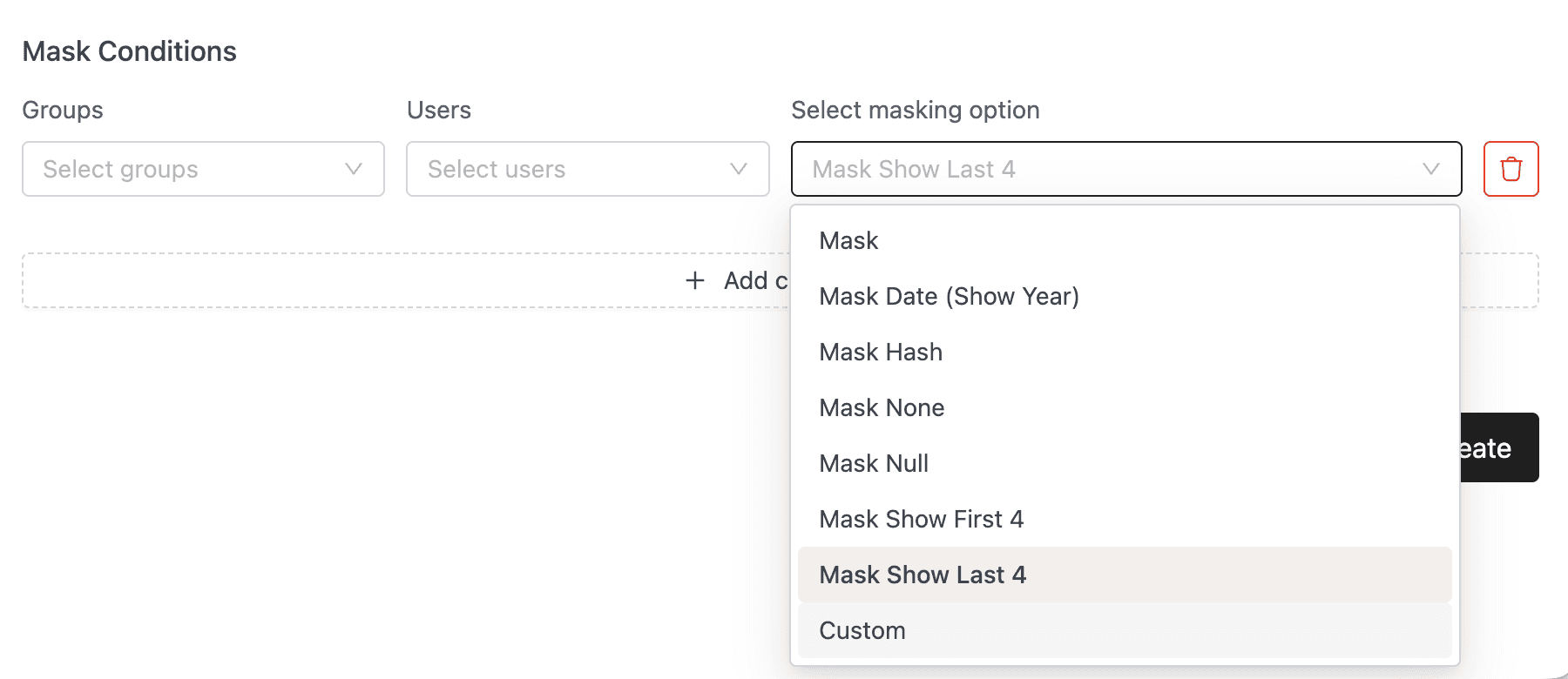
Tag-Based Masking Policies. IOMETE's data security layer has a tag masking policy type (/api/v1/admin/data-security/tag/mask/policy) that applies masking behavior to any column carrying a specific classification tag. The masking functions include standard transformations: full masking, partial masking (showing the last four or first four characters, useful for credit card PANs), hash masking, year-only date masking, and custom masking expressions. Policies are scoped by user groups and roles, so clinical staff querying PHI-tagged columns see real values while analysts outside that group see masked ones.
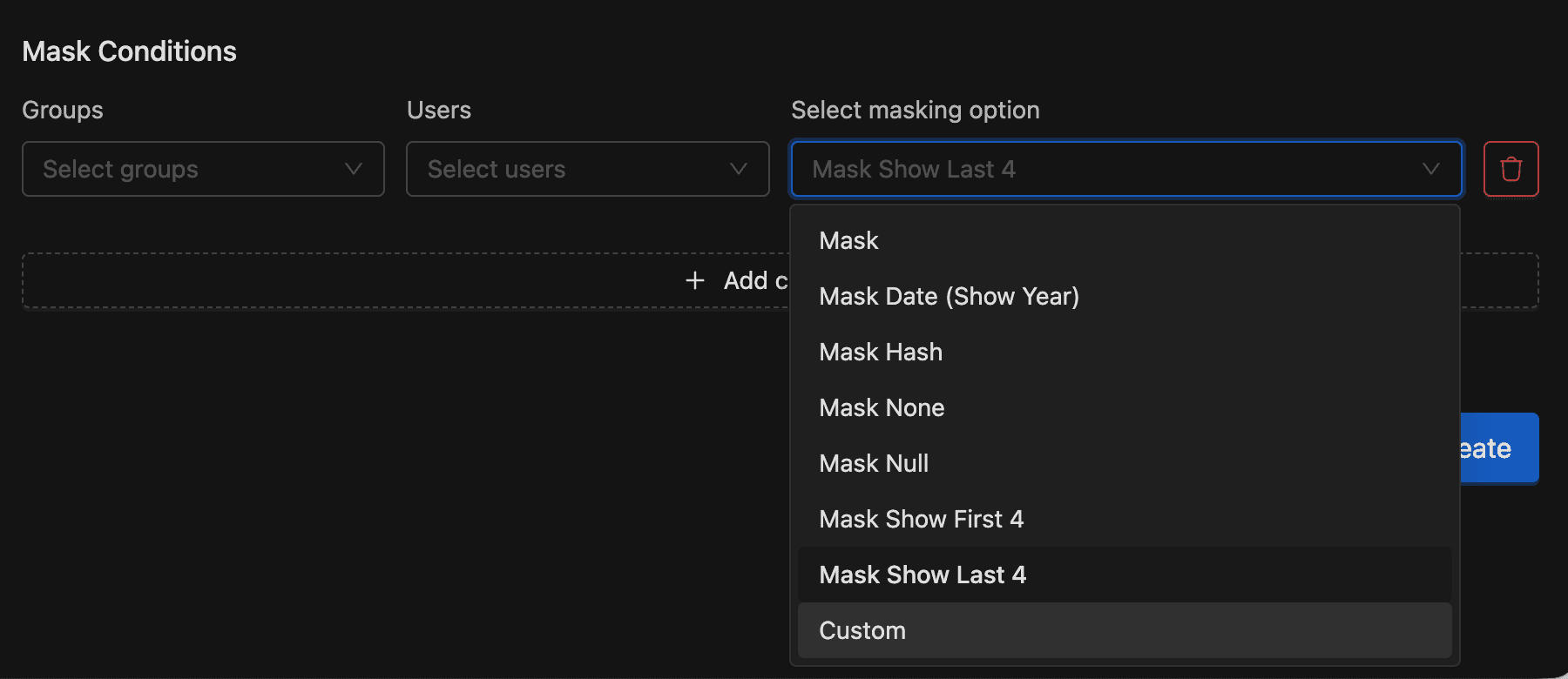
Column-Level Access Policies. Beyond masking (which shows transformed data to users who can query the column), IOMETE also supports column-level access policies that deny access to specific columns entirely for users who shouldn't see even masked values. These can be defined at the column level via the Access Control API or as tag-based exclusions for entire classifications.
Query-Time Enforcement. Masking is enforced at query execution time inside your Spark cluster. The enforcement isn't at an application layer that only covers traffic through a query interface. It applies to any query processed by the IOMETE compute engine, including Spark jobs, external JDBC connections, and programmatic access via Spark Connect. The cluster itself enforces the policy.
Full Deployment Inside Your Infrastructure. The entire stack (data catalog, classification store, policy engine, query enforcement) runs inside your Kubernetes deployment. There's no policy metadata stored on IOMETE's infrastructure, no vendor control plane mediating enforcement. Access logs stay in your environment for your audit tools to consume.
Automating Tag Assignment at Scale
The hardest part of tag-based masking isn't configuring the policies. It's ensuring columns actually get classified. In a data estate with thousands of columns spanning dozens of source systems, waiting for engineers to manually submit classification requests creates the same coverage gaps that manual masking did.
The automation approach combines three mechanisms:
Name-pattern classification. Columns named ssn, social_security_number, patient_dob, credit_card_number, email_address, phone_number, iban, or close variants are strong candidates for automated classification. A discovery script can scan the data catalog API for column names matching known patterns and submit classification requests programmatically via the Data Security API. An admin reviews a batch of proposed classifications rather than individual manual submissions.
Source-system tagging at ingestion. When a source system with known sensitive fields feeds data into the lakehouse, the ingestion pipeline can submit classification requests for new columns as part of the pipeline definition. A source marked as HIPAA-covered produces tables where PHI columns are flagged on arrival. The classification is tied to the pipeline's knowledge of the source, not to post-hoc discovery.
Bulk API operations for migration. For organizations onboarding an existing data estate, IOMETE's REST API supports programmatic policy creation at scale. A migration script can iterate through catalog metadata, apply name-based heuristics, and generate bulk classification requests that get reviewed in batches rather than column by column. The same script pattern works for ongoing governance audits that check whether new columns added in the past 30 days have been classified.
# Example: submit a classification request for a column via the Data Security API
curl -X POST "https://your-iomete.example.com/api/v1/domains/{domainId}/governance/classification-requests" \
-H "Content-Type: application/json" \
-H "X-API-Token: $TOKEN" \
-d '{
"assetType": "COLUMN",
"tableId": "<table-id>",
"columnName": "date_of_birth",
"classificationName": "PHI",
"justification": "Contains HIPAA-covered date of birth identifier; batch discovery run 2026-05-12"
}'
The governance workflow doesn't disappear. It moves to batch review. A data steward reviews 200 proposed PHI classifications and approves or rejects each one, rather than manually initiating 200 individual classification requests. The approval audit trail remains intact; only the discovery work is automated.
Compliance Mapping: What Tag-Based Masking Actually Covers
Regulated industries don't just need masking. They need masking that maps demonstrably to regulatory obligations. The classification model creates a natural structure for this mapping.
GDPR (General Data Protection Regulation). Article 25 (data protection by design and default) requires that privacy controls are built into data processing systems from the outset. Column-level classification of personal data, combined with query-time masking for non-authorized users, is a technical implementation of this principle. The classification tag registry makes it possible to answer the question: "Show us all personal data your systems process." The access logs answer: "Show us who accessed it."
HIPAA (Health Insurance Portability and Accountability Act). PHI identification is both a technical and administrative requirement. A PHI classification tag on columns containing the 18 HIPAA identifiers (names, geographic data, dates, phone numbers, fax numbers, email addresses, SSNs, medical record numbers, and others) creates a queryable record of where PHI lives in the data estate. Tag-based masking ensures that access to PHI columns is limited to workforce members with a legitimate treatment, payment, or operations justification.
DORA (Digital Operational Resilience Act). DORA Article 8 requires ICT risk management frameworks that include documented controls for access to sensitive data. Column-level security with audit logging, all running inside the institution's infrastructure, satisfies the requirement for documented, auditable access controls without creating a new third-party ICT dependency. The enforcement runs inside the institution's Kubernetes cluster; the access logs stay in the institution's SIEM.
PCI DSS (Payment Card Industry Data Security Standard). Requirement 3 (protect stored cardholder data) maps directly to column-level masking of PANs, CVVs, and card expiry dates. A PCI-DSS classification tag applied to these columns, combined with a tag-based masking policy that shows only the last four digits to non-authorized users, produces a configuration that auditors can verify programmatically.
The cross-framework value is significant for institutions that operate under multiple obligations simultaneously. A single column tagged PHI and PII is covered by both the HIPAA masking policy and the GDPR access policy. The classification registry becomes the single source of truth for regulatory exposure.
What Enforcement Failure Actually Looks Like
It's worth being specific about where column-level masking can fail, because the failure modes are architectural, not accidental.
Application-layer-only enforcement. If masking is applied only in the UI or BI tool layer, and not in the query engine, a user with direct Spark or JDBC access can bypass it entirely. IOMETE's enforcement at the compute layer means the policy applies regardless of access path.
Column exclusion rather than masking. Some access control implementations handle "sensitive columns" by excluding them from query results entirely. This breaks analytics workflows that need sensitive columns to be present but transformed. Proper dynamic masking returns the column with a transformed value, preserving query compatibility while protecting the data.
Static policy lists. If masking policies enumerate specific columns rather than classifications, the policy goes stale as schemas evolve. The tag-based model ensures new columns that receive a classification automatically fall under the existing masking policy with no policy update required.
Missing audit trail. Compliance audits require proof of who accessed sensitive data and when. Query-time masking alone isn't sufficient. It needs to be paired with access logs that capture the column-level events. IOMETE's audit logging covers data access events within your infrastructure, available to your existing log aggregation and SIEM tooling.
Getting Started
For organizations evaluating column-level security at scale, the implementation sequence that works in practice:
-
Define your classification taxonomy. Start with a small set of high-value classifications:
PII,PHI(if in healthcare),PCI-DSS(if handling card data),CONFIDENTIAL. Define what each classification means and which regulatory obligations it triggers. -
Build the tag-based masking policies. Create masking policies for each classification before tagging any columns. This means policies are ready to enforce the moment the first column is classified.
-
Run discovery on your existing estate. Use name-pattern queries against the catalog API to identify candidate columns for each classification. Review the candidates in batches; approve or reject each proposal.
-
Establish classification at ingestion. For new pipelines and source systems, add classification requests to the pipeline definition. PHI-sourced tables tag their sensitive columns on arrival.
-
Audit regularly. Scheduled catalog scans for unclassified columns matching known patterns catch columns that arrive without classification requests. The 30-day review cadence that works well in practice: scan for new columns, run name-pattern heuristics, surface candidates for batch review.
The work of building this system is not trivial for large data estates. But it's fundamentally different in character from the alternative: manual review of every column in every table, repeated every time the schema changes. Tag-based masking scales; manual masking does not.
For organizations in healthcare, banking, or financial services working toward GDPR, HIPAA, or DORA compliance and evaluating whether their current data platform's column-level security story holds up at scale, get in touch. We'd be happy to walk through your specific data estate and compliance requirements.
FAQ
Frequently Asked Questions
What's the key architectural difference between managed cloud lakehouse masking and IOMETE's approach?
The core difference is where enforcement happens: inside your infrastructure or inside a vendor's managed service.
On managed cloud platforms, masking policies are typically enforced at the vendor's query layer. This works well for traffic through that layer, but it means your governance plane sits outside your own infrastructure perimeter. For EU financial institutions under DORA or organizations with strict data residency requirements, that creates a third-party ICT dependency that requires formal risk management.
IOMETE's masking policies are enforced at query execution time inside your own Kubernetes cluster. The policy engine, classification store, and access logs all run within your infrastructure perimeter. There's no vendor control plane involved in enforcement decisions, which simplifies the DORA third-party risk picture and keeps governance metadata under your control.
Can we apply column-level masking to existing tables without rewriting data?
Yes. IOMETE's masking is dynamic. It applies transformations at query execution time, not to the underlying data at rest.
The data in your Iceberg tables remains unchanged. When a query reads a masked column, the compute engine applies the masking function during execution and returns the transformed value. The stored data is never modified. This means you can apply masking policies to existing tables immediately, without reprocessing or rewriting any data, and you can remove or change masking policies without data migration.
How does the classification approval workflow work at scale? Won't reviewing thousands of columns become a bottleneck?
The approval workflow is designed for batch review, not individual approvals. When discovery scripts identify candidate columns matching PHI or PII patterns, those candidates are surfaced to administrators as a batch of pending classification requests.
An administrator with the DATA_SECURITY_AND_AUDIT_MANAGER role reviews the batch, typically grouped by source system or schema, and approves or rejects each proposed classification. For a large initial onboarding, this typically means a few focused review sessions rather than ongoing per-column overhead. The audit trail (who requested, who approved, what justification was provided) remains intact for every classification, regardless of whether discovery was manual or automated.
What happens to masking when downstream tables or derived columns are created from tagged data?
Today, sensitive-data tags and masking rules do not automatically propagate to downstream tables or derived columns created from tagged data. That means a downstream table created from masked or tagged columns will not automatically inherit the same classification or masking behavior.
We are planning and building data lineage capabilities that can track dataset relationships, column-level lineage, and transformations across the platform. The goal is to use that lineage foundation in the future to help identify downstream data derived from sensitive columns and support lineage-assisted classification propagation and governance workflows.
At the moment, though, this propagation is not available automatically.
Does column-level masking apply to Spark jobs, not just SQL queries?
Yes. Enforcement happens at the compute layer, not the SQL Editor or BI tool layer.
When a Spark job reads a table through IOMETE's compute cluster, the masking policies apply to that read just as they would for an interactive SQL query. A data scientist running a PySpark job against a table with PHI-tagged columns will see masked values for those columns unless their group membership grants them unmasked access. The policy applies to all query paths that go through the IOMETE compute engine: SQL Editor, scheduled queries, Spark jobs, JDBC connections, and Spark Connect clients.
What masking functions are available?
IOMETE's masking policies support several masking types that cover the most common regulatory requirements: full masking (replacing the entire value with a null or placeholder), partial masking (exposing the last 4 or first 4 characters, useful for credit card PANs and account numbers), hash masking (one-way transformation useful for pseudonymization), year-only date masking (returning only the year from a date field), and custom masking expressions (SQL expressions that apply arbitrary transformations for any pattern not covered by the built-in types).
Different masking functions can be configured for the same classification tag depending on the user group. Clinical staff querying PHI-tagged columns might see actual values; data analysts working on aggregate reports might see year-only masked birth dates. Both behaviors are configured in a single tag-based policy with group-specific masking rules.
How do we demonstrate DORA compliance for column-level data access controls?
DORA Article 8 ICT risk management requires documented controls for access to sensitive data and audit trails showing those controls are operating correctly.
In IOMETE deployments, the compliance evidence chain includes: the classification registry (which columns are classified and why, with approval history), the tag-based masking policies (which classifications are masked, for which user groups, with which transformations), and the access logs (which users queried which columns, and whether masking was applied). All of this evidence stays within your infrastructure. The audit logs are available to your existing SIEM and log aggregation tooling, and the classification and policy records are queryable through the Data Security API. There's no dependency on a vendor to produce audit evidence on your behalf.
Can we use the API to automate masking policy creation for a large number of tables?
Yes. IOMETE exposes a full REST API for all data security operations. Access policies, masking policies, row-level filters, and tag-based policies are all createable, queryable, and manageable programmatically.
For large migrations or initial onboarding, the typical pattern is: query the catalog API for columns matching classification heuristics, submit classification requests in batch, and create tag-based masking policies that automatically cover all current and future classified columns. Once the tag-based policies exist, individual column tagging doesn't require policy updates. The policy propagates automatically to newly classified columns. The API also supports listing and auditing existing policies, which feeds into periodic compliance reporting workflows.
How does IOMETE handle masking for federated queries across multiple catalogs?
IOMETE supports multiple Spark catalog configurations, and masking policies defined through the IOMETE data security layer apply to tables accessed through those catalogs when queries are processed by the IOMETE compute engine.
For external catalog sources accessed via JDBC federation, masking at the column level depends on whether the data flows through IOMETE's compute layer. Native Iceberg tables stored in your configured storage and accessed through IOMETE's internal or external Iceberg catalog have full masking policy enforcement. For federated queries against external JDBC sources, access control operates at the query routing level, and column-level masking applies to the result set returned to the IOMETE compute layer.