DATA MESH with IOMETE

What is Data Mesh?
A Data Mesh is an architectural pattern for designing and implementing data infrastructure in a microservices-based architecture. The term “Data Mesh” was first coined by Zhamak Dehgani, a principal technology consultant at ThoughtWorks with a focus on distributed systems architecture and digital platform strategy at Enterprise in 2019. It aims to provide a scalable and resilient way to handle data across multiple teams and services while minimizing dependencies and maximizing autonomy. It divides data into smaller, autonomous data domains, each with its own team and data product, and uses a set of principles, patterns, and practices to ensure that data is accessible, consistent, and secure across the organization. Data Mesh is not a specific product or framework, but rather a set of best practices and patterns to be adopted by the organization.
Why should we use Data Mesh?
A Data Mesh allows users to easily access data without transporting it to a data lake or data warehouse and focuses on decentralization, distributing data ownership among teams who can manage data as a product independently and securely thus reducing bottlenecks and silos in data management and enabling scalability without sacrificing on data governance.
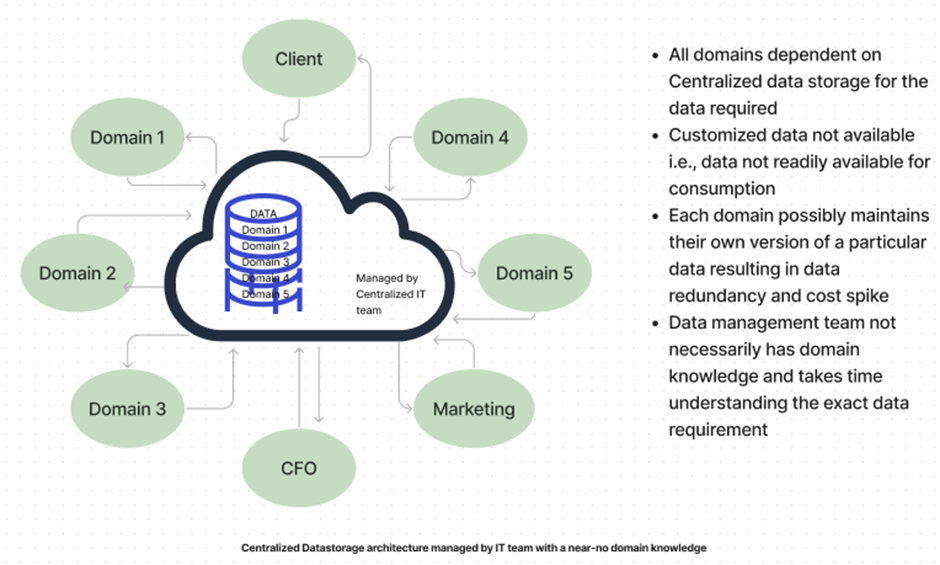
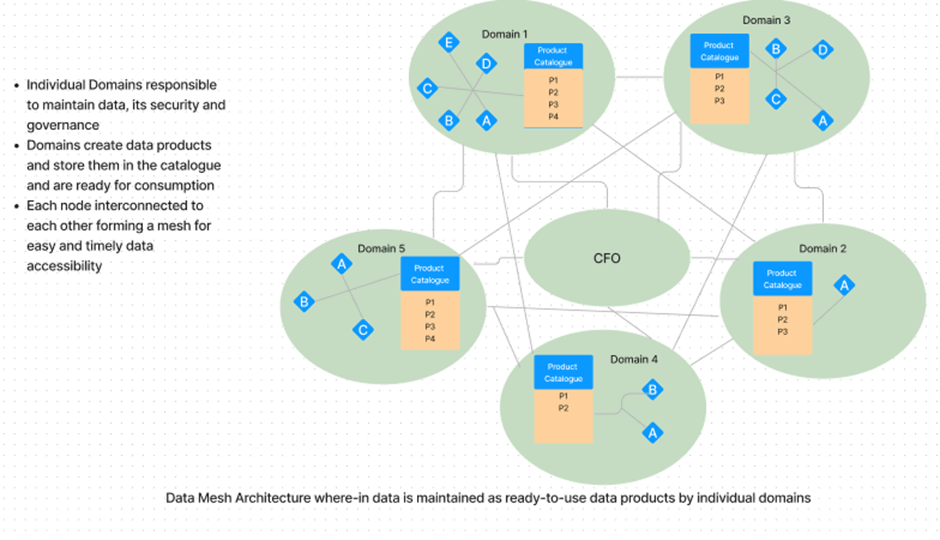
A monolithic data infrastructure stores, processes, and transforms data in one central data lake. Centralized Data teams in the long run cannot handle all the analytical questions of management and product owners quickly enough. This is a massive problem because making timely data-driven decisions is crucial to stay competitive. A data mesh, on the other hand, refers to data as a ‘product’ with each domain handling its own data and presenting it as a ready-to-consume product than simple raw data.
Vs
Organizations can spend most of their efforts on people and processes and relatively lesser efforts on technology to enable the future data mesh state, thus helping to cut costs and reduce dependency on technology as compared to data lakes. Tthe thing that data mesh brings into an organization boils down to reducing cost (not as such the cost would be reduced by moving onto mesh architecture itself, but the cost of providing redundant/obsolete/untimely data and the costs around it would come down as it would help increase the productivity of each domain and data consumers as they provide, and are fed with high-quality data and more importantly timely in the form of ready-to-consume data products by the concerned domain teams). A data mesh may not be for all types of businesses, such as smaller businesses with relatively fewer data and data nodes to handle; however, it may still be useful for enterprises that wish to achieve better scalability in their data management efforts.
Centralized data storages like Data Lakes are a cost-effective architecture but come with a few drawbacks and costs. The following table illustrates the drawbacks of the same and how Data mesh overcomes the same.

Data Products:
We are aware of traditional products or services as products created/designed to solve a particular purpose, but can data be designed as a product?
Yes, just as a product or a service provides a solution or serves a particular purpose, Data products solve a particular requirement of data, they are a way of packaging and delivering data services to different teams and consumers based on the requirement and are ready-to-use in most cases. It is a product per-se version of a data service that is owned and operated by the domain to which the data belongs and the domain itself is responsible for the development, operation, and maintenance of the same, and they are also responsible for defining and enforcing the data product's governance policies in consensus with the overall organization’s governance policy.
In Data Mesh architecture, data products are key patterns for building data services that are tailored to the specific needs of different teams and consumers, while still being able to share and reuse data services provided by other teams, leading to more efficient and effective data management. They also provide a way to package and deliver data services to different consumers, such as other teams or external customers. This can help to improve the discoverability and accessibility of data services, as well as improve the security and performance of the system by handling specific types of requests, such as authentication and authorization, at the data product level making it one of the core value of data mesh and thus data products are one of the four principles on which the data mesh stands on and are discussed further below.
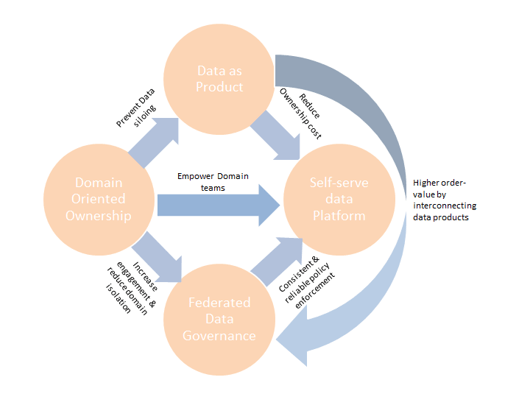
Four Pillars of Data Mesh
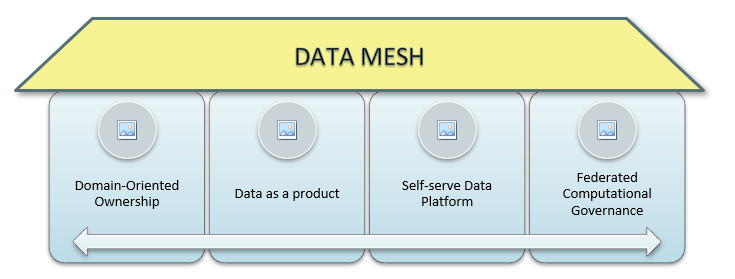
- Domain-Oriented Ownership
We can decentralize the ownership of data to business domains that are closest to it; this means either those who collect data or those who use it. A good way to do this is to decompose the data into its logical parts, based on its relationships with other parts of an organization. By doing this we can make sure that all parts of an organization's data are managed independently from each other. This will mean that if one part becomes more important than another then it can be prioritized for development much faster. The motive is to give the organization a single source of truth with scattered data assets that may not communicate with one another.
- Data as a product
Business domains will be held accountable for sharing their data as a product. Data products enable multiple users to gain value from data, and they can be used by a wide range of people with different roles, including data analysts and data scientists. By providing ease of usability and understandability, finding, accessing, and sharing high-quality business domain data peer-to-peer is made simpler, while allowing autonomy through the development of clear contracts between the business domain's data products with operational isolation (i.e., changing one business domain product should not destabilize others).
Data as Products or a Product-centric approach to delivering data is the essence of Data Mesh architecture. It involves building data products that are aligned with business capabilities and customer needs. The data products are developed, managed, and operated in the same way as other products, with a clear focus on delivering value to its consumers in alliance with business capabilities and customer needs which include defining clear goals and metrics for data products and aligning data product development with the overall product development process.
Product-centricity also means that teams are empowered to own and operate their own data products, rather than having a centralized team or organization responsible for all data management. This allows teams to make decisions about their data based on their specific needs and business requirements, leading to more efficient and effective data management. Additionally, Product-centricity encourages teams to experiment, innovate and improve their data products and services, as they are not totally constrained by centralized decision-making or limited by a centralized data infrastructure. It also allows teams to have a direct feedback loop with their customers and stakeholders, which leads to more effective data products and services that better meet the needs of the business and its customers.
- Self-serve Data Platform
A modern self-serve data platform is designed to give domain-centered teams the ability to supervise the whole life cycle of their data products, so as to take care of a dependable connected system, this lowers the overall cost of owning data in a decentralized domain-oriented operating system and design. It not only simplifies the data management intricacies but also decreases the cerebral load of domain teams in controlling the full life cycle of their data products. It also allows a wider population of coders, generalist specialists to embark on data product progression and diminishes the necessity for specialization. Moreover, it furnishes the computation abilities needed for governance, such as routinely carrying out regulations at the correct point of time, detecting data products, accessing a data product, and assembling or releasing a data product.
- Federated Computational Governance
A data governance operational model that is established on a federated system of decision-making and accountability, comprised of domains, data platforms, subject matter experts, legal, compliance, security, etc. It generates an incentive and accountability framework that reconciles the autonomy and agility of domains, while still honoring the worldwide congruence, interoperability, and security of the mesh. The model largely depends on encoding and mechanized implementation of policies at a highly-detailed level, for each and every data product.
The governance model offsets the potential adverse effects of domain-oriented decentralizations: incompatibility and detachment of domains. It creates a means of satisfying the governance demands like safety, confidentiality, legal adherence, etc. over a web of dispersed data products and minimizes the corporate overhead of constantly aligning between domains and the governance function, and to keep versatility in the face of regular transformation and growth
Integrating Data Mesh Architecture:
Integrating data mesh into an organizations ecosystem majorly comprises the following three steps:
- Connect Data Sources:
The first and main aim is to connect all the data sources where they reside basically by leveraging the organizations existing investments in data storage i.e., by using Data Lakes/Warehouses, Cloud /On-premise, structured warehouses, or a non-structured lake. Unlike the single-source approach to centralize all your data first, you’re leveraging and querying the data where it resides. The direction of the arrow represents the challenges of the from node and how the to node resolves the same
- Create Logical Domains
The second goal is to create an interface for the business and concerned teams to find their data. It is logical as the data is not simply accessed from a central repository but obtained from the concerned autonomous domain/team as it is made available to the concerned user based on their requirements thus promoting the self-service where data consumers can do more on their own
- Implement autonomy and self-sufficiency:
Give each data team the autonomy and resources they need to manage their own data. Post providing the domain teams with access to the data they need, they should be taught to create directly consumable data products by the data consumers, such data products can be stored in a catalog for the consumers to pick data from.
It's important to note that, implementing a data mesh architecture is not a one-time event, but rather an ongoing process that requires constant adaptation and evolution.
Advantages of data mesh in data management
- Improved Agility and scalability
Data Mesh enables decentralized data operations, improving time-to-market, scalability, and business agility of different areas of a system independently, without having to coordinate changes across multiple teams.
- Flexibility and Independence
Organizations that choose a data mesh architecture to avoid being locked into one data platform or data product.
- Transparency for cross-functional use across teams
Centralized data ownership on traditional data platforms leaves teams of data experts isolated and highly dependent, resulting in a lack of transparency. Data Mesh decentralizes data ownership and distributes it across cross-functional domain teams.
- Faster access to critical data
Data Mesh thrives to improve the accessibility of data, by promoting decentralized data management and ownership, self-service data platforms, and federated data access, that empower teams to access the data they need more quickly, without having to wait for a central data team to make changes or provide access. This can lead to faster feature development and better decision-making
- Failure Isolation :
Using techniques such as service autonomy, isolation of data stores, circuit breaking, load balancing, and monitoring and alerting, data mesh helps to isolate the impact of failures within specific services or components, rather than allowing them to propagate and affect the entire system. This can help to improve the overall availability and resiliency of the system, by reducing the likelihood of cascading failures and improving the ability to quickly detect and respond to failures.
The benefits of turning to an architecture like data mesh would not solely depend on just hopping onto the architecture itself, but would mainly depend on how big the data being handled is, the complexity of hierarchy/domain teams handling data, and how efficiently the mesh is designed and implemented which would help an organization draw an edge in terms of saving time, money, provide better security and quality of data that is fed into the system to achieve the same.
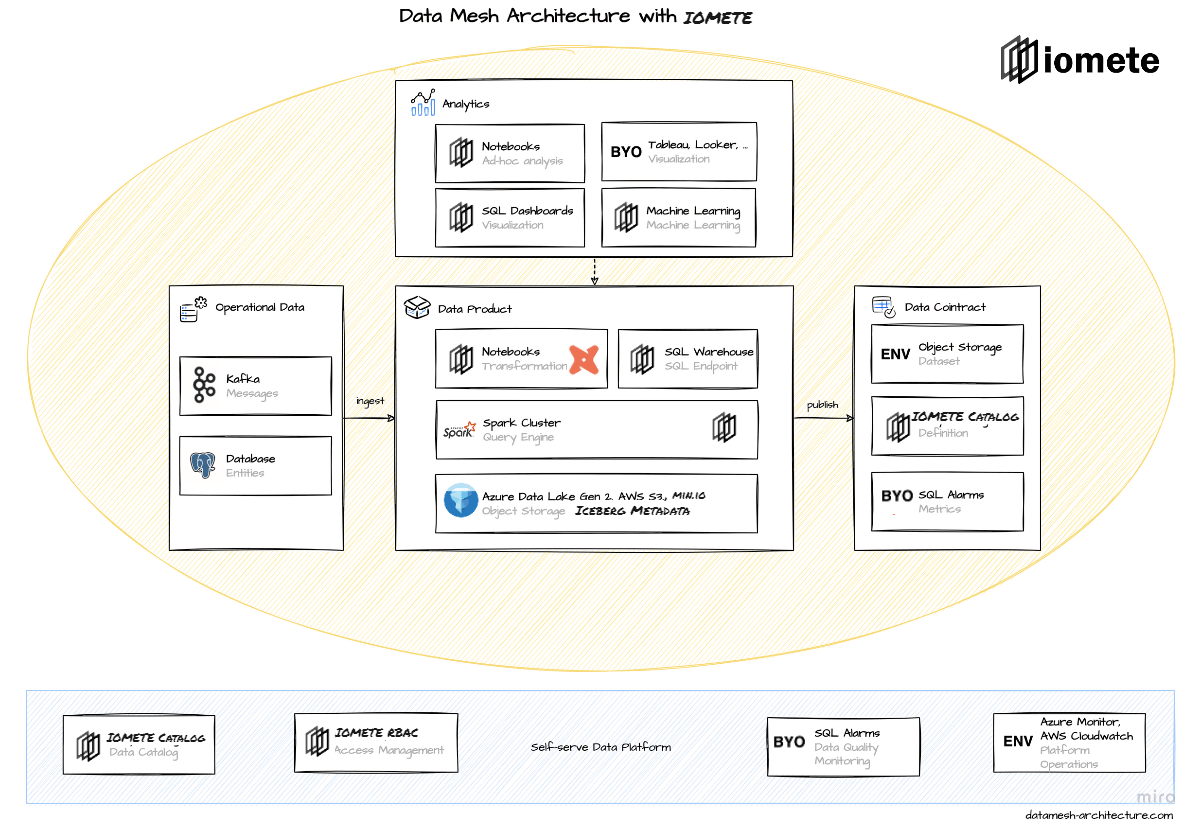
The IOMETE platform provides Data Mesh as below: