How to Build a Self-Hosted Data Lakehouse on Kubernetes

Most teams that end up building a self-hosted lakehouse don't start out planning to. They start with a data warehouse that gets expensive, or a data lake that becomes ungovernable, or both. At some point someone asks the question: what would it take to build something that actually works?
This is that guide. It covers the architecture layer by layer — storage, table format, catalog, compute, and access — based on what actually runs in production, not what looks clean in diagrams.
A data lakehouse isn't a single product. It's a stack of components that, when assembled and operated correctly, gives you warehouse-style SQL performance on top of a storage layer you fully control. The open standards that make this possible — Apache Iceberg, Apache Spark, S3-compatible object storage — are mature and widely deployed. The hard part isn't picking the components. It's understanding how they fit together and what breaks when you scale.
The architecture in plain terms
Before getting into implementation, it helps to understand what the stack actually does:
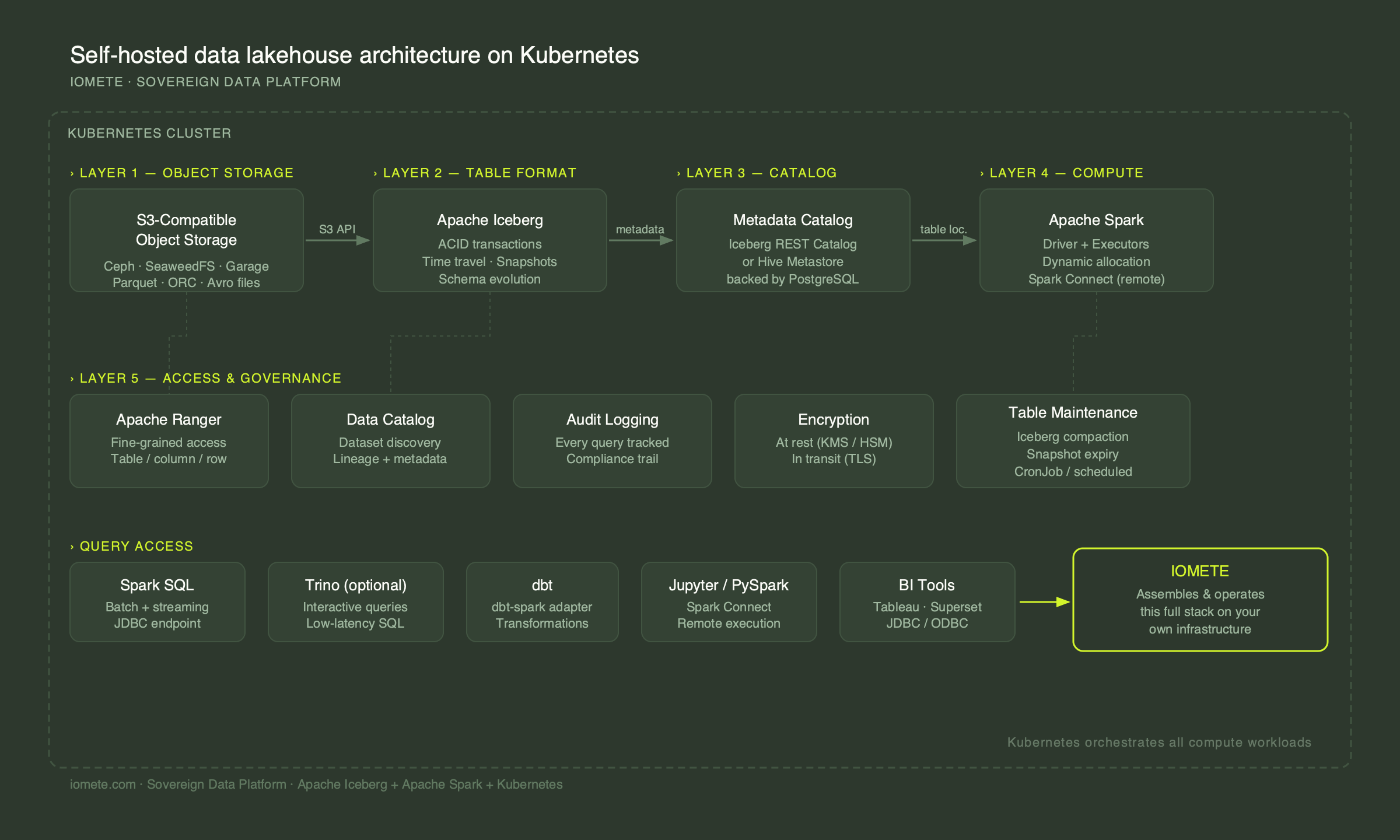
Object storage holds the physical data files — Parquet, ORC, or Avro — plus Iceberg metadata. Nothing is processed here. It's a durable, scalable file system with an S3-compatible API.
Apache Iceberg sits as a table format layer on top of storage. It tracks which files belong to which table, manages schema evolution, handles ACID transactions, and makes time travel possible. Iceberg doesn't process data — it organizes it.
A metadata catalog tracks where Iceberg tables live and what their current state is. Hive Metastore and the Iceberg REST catalog are the two main options. The catalog is what lets multiple compute engines read the same tables without corrupting each other's writes.
Apache Spark is the compute layer. It reads from the catalog to locate tables, processes data using the Iceberg APIs, and writes results back to object storage. For batch workloads and complex transformations, Spark handles the heavy lifting.
A SQL query engine (Spark SQL, or optionally Trino for lower-latency interactive queries) is what analysts and BI tools actually talk to.
Kubernetes orchestrates everything. It schedules Spark jobs, manages resource allocation across workloads, handles failures, and gives you a consistent operational layer regardless of where the infrastructure lives.
Layer 1: Object storage
Your first decision — and one that's worth getting right — is which S3-compatible object store to run.
For years the answer was MinIO. Fast, Kubernetes-native, easy to operate. That changed in late 2025 when MinIO transitioned to maintenance-only status and was subsequently archived. If you're designing a new self-hosted lakehouse today, you're choosing a replacement.
The realistic production options in 2026:
Ceph RGW is the most mature and most complex. It handles everything from block to object to file storage, has a long production track record, and scales to petabytes. The tradeoff is operational complexity — Ceph has its own learning curve and its own failure modes. For teams with dedicated infrastructure engineers, it's the most capable option.
SeaweedFS runs a middle path. It's significantly simpler than Ceph, has good Kubernetes support, and an O(1) seek architecture that performs well with Iceberg's many-small-files workloads. Apache 2.0 licensed. For teams at mid-scale who need something proven without a full storage engineering practice, SeaweedFS is worth serious evaluation.
Garage is lightweight and straightforward. If your lakehouse is under 50TB, you have multiple sites or edge deployments, and simplicity matters more than maximum throughput, Garage's operational profile is compelling.
See the full evaluation in Evaluating S3-Compatible Object Storage for Your Data Lakehouse.
Whatever you choose, the interface your lakehouse interacts with is the S3 API. The storage layer is pluggable — Iceberg and Spark don't care whether they're talking to AWS S3, a Ceph cluster, or a SeaweedFS deployment, as long as the API is compatible.
Layer 2: Apache Iceberg and the table format
Iceberg is what transforms a directory of Parquet files into something a data platform can work with. Without it, you have a data lake. With it, you have a lakehouse.
The specific capabilities Iceberg provides that matter operationally:
ACID transactions mean that when two Spark jobs write to the same table simultaneously, they don't corrupt each other. This is fundamental for any production workload where multiple pipelines touch the same data.
Schema evolution lets you add, rename, or drop columns without rewriting existing data files. This sounds minor until you've dealt with the operational reality of schema changes in a data warehouse — it becomes a significant operational relief.
Time travel lets you query a table as it existed at any point in its history. The mechanism is snapshot-based: Iceberg writes a new snapshot on every commit, and you can query against any historical snapshot using AS OF syntax. This is how you recover from bad pipeline runs without restoring backups.
Partition evolution allows you to change how a table is partitioned over time without rewriting data. If your initial partition strategy turns out to be wrong (it usually does), you can fix it without a full table migration.
Compaction is the maintenance operation that merges small files into larger ones. Iceberg accumulates small files naturally from streaming writes and frequent updates. Without regular compaction, query performance degrades as the engine has to open thousands of files per scan. Plan for compaction from the start — it's not optional at production scale.
Layer 3: The metadata catalog
The catalog is the component most people underestimate when designing a lakehouse. It's not glamorous, but it's what allows multiple compute engines — Spark jobs, Trino queries, dbt transformations — to coordinate access to the same tables without corrupting each other's state.
Hive Metastore (HMS) is the legacy option. It's been around since the Hadoop era, is widely understood, and has broad compatibility with tools that predate the Iceberg ecosystem. The downsides: it's a stateful service with its own operational overhead, its REST API surface is limited, and it has known scalability ceilings at high table counts.
Iceberg REST Catalog is the modern alternative. It exposes a standardized REST API that any Iceberg-aware compute engine can speak. You can run it as a lightweight stateless service backed by a database (PostgreSQL is common). It's simpler to operate than HMS and has better multi-engine support.
Unity Catalog (open source) is emerging as an option but is still early in terms of community adoption and production track record in self-hosted environments.
For a new deployment in 2026, the REST catalog is the right default unless you have existing tooling that depends heavily on HMS compatibility.
Layer 4: Compute with Apache Spark
Spark runs as Kubernetes workloads — either as long-running clusters for interactive SQL workloads or as ephemeral job clusters that spin up for a specific pipeline and terminate when it completes.
The resource model matters here. Spark on Kubernetes uses dynamic allocation: executors spin up when work is available and release resources when idle. For a multi-tenant environment where different teams are running different workloads, this is critical — you don't want a heavy batch job starving interactive query resources.
Key operational decisions when running Spark on Kubernetes:
Driver vs executor sizing — the driver is the orchestrator (relatively small memory requirement), executors do the work (memory-heavy). Getting the executor memory-to-CPU ratio right for your workload type is worth benchmarking early.
Shuffle storage — Spark shuffles intermediate data during joins and aggregations. In a Kubernetes environment, shuffle data goes to local storage by default. For large jobs, you'll want to configure this explicitly and ensure the nodes have sufficient local disk.
Spark Connect enables remote connections from development environments — data scientists write PySpark locally, execution runs distributed against the lakehouse. This matters practically because it keeps development workflows clean without requiring local Spark installations.
Layer 5: Access and governance
A lakehouse with no access control is a data swamp with ACID transactions. You need:
Fine-grained access control at the table, column, and row level. Apache Ranger is the standard for this in self-hosted environments. It integrates with Spark and enforces permissions before data ever reaches the query engine.
A data catalog for discovery — separate from the Iceberg metadata catalog. This is the layer your data engineers and analysts use to find datasets, understand schemas, and trace lineage. Without it, the lakehouse becomes opaque and teams start building shadow copies.
Audit logging — every query, every access. This is non-negotiable for regulated industries and increasingly expected everywhere else.
Encryption — at rest via your object storage layer or KMS integration, in transit via TLS. For regulated workloads, key management and key isolation (different keys per tenant or dataset) matter beyond just "encryption is on." See Data Lakehouse Encryption: Encrypting Data at Rest in Apache Iceberg for a detailed breakdown.
What people underestimate when building this themselves
The architecture above is sound. Teams have run it in production. But there are a few things that consistently surprise people who build it from scratch:
Iceberg compaction at scale is a job in itself. Small file accumulation is constant and automatic compaction requires careful scheduling to avoid impacting active workloads. You're not setting it up once — you're operating it ongoing.
Catalog availability matters more than you think. If the catalog service goes down, all your compute engines stop dead. HMS and REST catalog both need proper HA configuration. This is often skipped in initial setups and causes production incidents.
Multi-engine catalog conflicts are subtle. If Spark and Trino are both writing to the same tables, their Iceberg client versions need to be compatible. Iceberg is good at handling this, but incompatible client versions can cause silent data issues that show up as mysterious query results.
Kubernetes resource isolation for Spark workloads is not automatic. Without explicit namespace-level resource quotas and priority classes, a single runaway Spark job can saturate your cluster. This is an operational concern, not just a deployment concern.
Upgrades touch every layer simultaneously. Upgrading Spark, Iceberg, and the catalog independently is fine in theory. In practice, maintaining version compatibility across the stack requires careful sequencing and testing. The operational burden compounds with each additional component you manage.
When building it yourself makes sense
Running this stack yourself is the right call when:
- Your organization has a deliberate infrastructure ownership strategy — Kubernetes is already in production for other workloads
- Data sovereignty, compliance, or air-gapped requirements mean SaaS platforms are off the table
- Your team has the engineering capacity to operate distributed systems
- You need the cost predictability of infrastructure you own
For context on the data sovereignty dimension specifically, see Data Residency vs Data Sovereignty: Why Location Alone Doesn't Protect Your Data — it covers the compliance distinction between where data sits and who actually controls it.
The alternative: assembled vs. DIY
Some teams get deep into this build and realize what they're actually operating is more infrastructure than data platform. That's a legitimate discovery — not a failure. The components above, assembled and operated with production-grade reliability, represent a meaningful ongoing engineering investment.
IOMETE is a self-hosted data lakehouse platform that assembles this same stack — Apache Iceberg, Apache Spark, Kubernetes, catalog, access control, data catalog — into a single deployable and operated system. It runs entirely within your infrastructure, which means the data sovereignty and compliance properties are identical to a DIY build. The difference is who operates it.
It's worth distinguishing this from managed cloud SaaS platforms: IOMETE doesn't run your data on shared infrastructure. It runs on yours. Your object storage, your Kubernetes cluster, your network perimeter. The platform handles the Iceberg compaction, catalog HA, Spark version management, and upgrade sequencing — but the infrastructure ownership stays with you.
For teams evaluating this decision, what is IOMETE covers the platform architecture in detail.
FAQ
Frequently Asked Questions
What do I need to build a self-hosted data lakehouse on Kubernetes?
The core components are: S3-compatible object storage (Ceph, SeaweedFS, or a cloud bucket), Apache Iceberg as the table format, a metadata catalog (Iceberg REST or Hive Metastore), Apache Spark for compute, and an access control layer such as Apache Ranger.
Kubernetes orchestrates the compute layer — Spark clusters run as Kubernetes workloads, with dynamic executor allocation. Each component is independently deployable, but they need to be kept at compatible versions and operated as a coordinated system.
What's the difference between a data lake and a data lakehouse?
A data lake is a storage layer — files in object storage with no enforced structure, schema, or transactional guarantees. A data lakehouse adds Apache Iceberg (or a similar open table format) on top of that storage, which brings ACID transactions, schema enforcement, time travel, and SQL query performance.
In operational terms: a data lake often becomes a data swamp. A lakehouse, when properly maintained, stays queryable and consistent at scale because the table format handles write coordination and metadata management.
Why use Apache Iceberg instead of Delta Lake or Hudi?
Iceberg is the most portable of the three. It has the strongest multi-engine support — Spark, Trino, Flink, Presto, and others all read and write Iceberg tables natively. It's also governed by the Apache Software Foundation, which means no single commercial entity controls the spec.
Delta Lake is controlled primarily by one commercial vendor and has historically lagged in non-Spark engine support. Hudi is strong for streaming upsert workloads but has a steeper operational learning curve than Iceberg for general analytics use cases. For a new self-hosted deployment in 2026, Iceberg is the default unless you have a specific reason to choose otherwise.
What is the Iceberg REST catalog and why does it matter?
The Iceberg REST catalog is a standardized API specification for catalog operations — creating tables, committing snapshots, resolving table locations. Any compute engine that implements the spec can read and write Iceberg tables through a compatible catalog server.
It matters for self-hosted deployments because it decouples the catalog from any specific compute engine. You can run Spark, Trino, and dbt against the same catalog without HMS-specific adapter code. It's also simpler to operate than Hive Metastore — you can run it as a stateless service backed by PostgreSQL with straightforward HA configuration.
How do I handle Iceberg compaction on Kubernetes?
Iceberg compaction merges small data files into larger ones to prevent query performance degradation over time. It runs as a Spark job — either on a schedule (using a Kubernetes CronJob or an orchestration tool like Airflow) or triggered by monitoring small file counts.
The key operational consideration is timing: compaction jobs compete for Spark executor resources with your active workloads. For production deployments, run compaction during low-activity windows or dedicate a separate Spark cluster to maintenance operations. Table-specific compaction strategies (partition pruning, sort order, target file size) significantly affect how often you need to run it.
Can I run a self-hosted data lakehouse on-premises without cloud object storage?
Yes. The lakehouse architecture doesn't require cloud infrastructure. Object storage (the S3 API) can be self-hosted using Ceph RGW, SeaweedFS, Garage, or hardware appliances that expose an S3-compatible API.
The Iceberg and Spark layers above the storage tier are identical whether you're pointing at AWS S3 or a Ceph cluster. The configuration differs (endpoint URL, credentials format) but the architecture and operational behavior are the same. Air-gapped and fully on-premises deployments follow the same design.
What are the main operational challenges of running Iceberg in production?
The three that affect most teams: small file accumulation (requires ongoing compaction), catalog availability (the catalog is a single point of failure for all compute engines if not deployed with HA), and Iceberg client version compatibility across engines.
Beyond those, snapshot expiry management (old snapshots accumulate storage) and partition evolution planning (getting partition strategies right early avoids costly later rewrites) are the other operational disciplines that separate stable production deployments from ones that degrade over time.
When does it make sense to use a self-hosted lakehouse platform instead of building from scratch?
Building from scratch makes sense when your team has the operational capacity to maintain a distributed system stack across multiple Kubernetes workloads, and where full infrastructure control is the primary objective.
A self-hosted platform makes sense when the goal is infrastructure ownership and data sovereignty — but engineering bandwidth is better spent on data pipelines and analytics rather than Iceberg compaction tuning and catalog HA configuration. The distinction matters: a self-hosted platform still runs within your infrastructure. The difference is who operates the stack, not where the data lives.