Data Warehouse to Lakehouse Evolution

Introduction
Welcome to the World of Data Lakehouses
Hello, and welcome to a journey through the evolving landscape of data storage and processing!
Today, we're diving into the fascinating world of Data Lakehouses, a revolutionary concept that's reshaping how we handle vast amounts of data.
I'm Vusal, a co-founder at IOMETE, and your guide on this exploration. Distributed Systems and Data engineering isn't just my profession; it's my passion. Over the past four years, while building IOMETE (Data Lakehouse Platform), I've gathered a wealth of experience and insights in this field. And now, I'm thrilled to share these learnings with you.
This blog post is the extraction from our webinar series on how to build an on-premise data lakehouse. If you want to watch the webinar, you can find the link in the end of the blog post. If you wish to register for the next webinar about How to build a Lakehouse Platform, you can drop me an email at vusal@iomete.com.
Why you should read this blog post?
If terms like Data Lake, Data Lakehouse, and Data Warehouse often leave you puzzled, you're not alone. These concepts can be complex, but understanding them is crucial in today's data-driven world.
This blog post (and I highly recommend watching the webinar) will help you understand the differences between these concepts and how they evolved.
Before diving into the history of data lakehouses, let's first understand a data lakehouse on a high level.
What is a data lakehouse?
A data lakehouse is a unified architecture that combines the best elements of data lakes and data warehouses, allowing businesses to manage, govern, and analyze their data across structured and unstructured sources, offering a single source of truth.
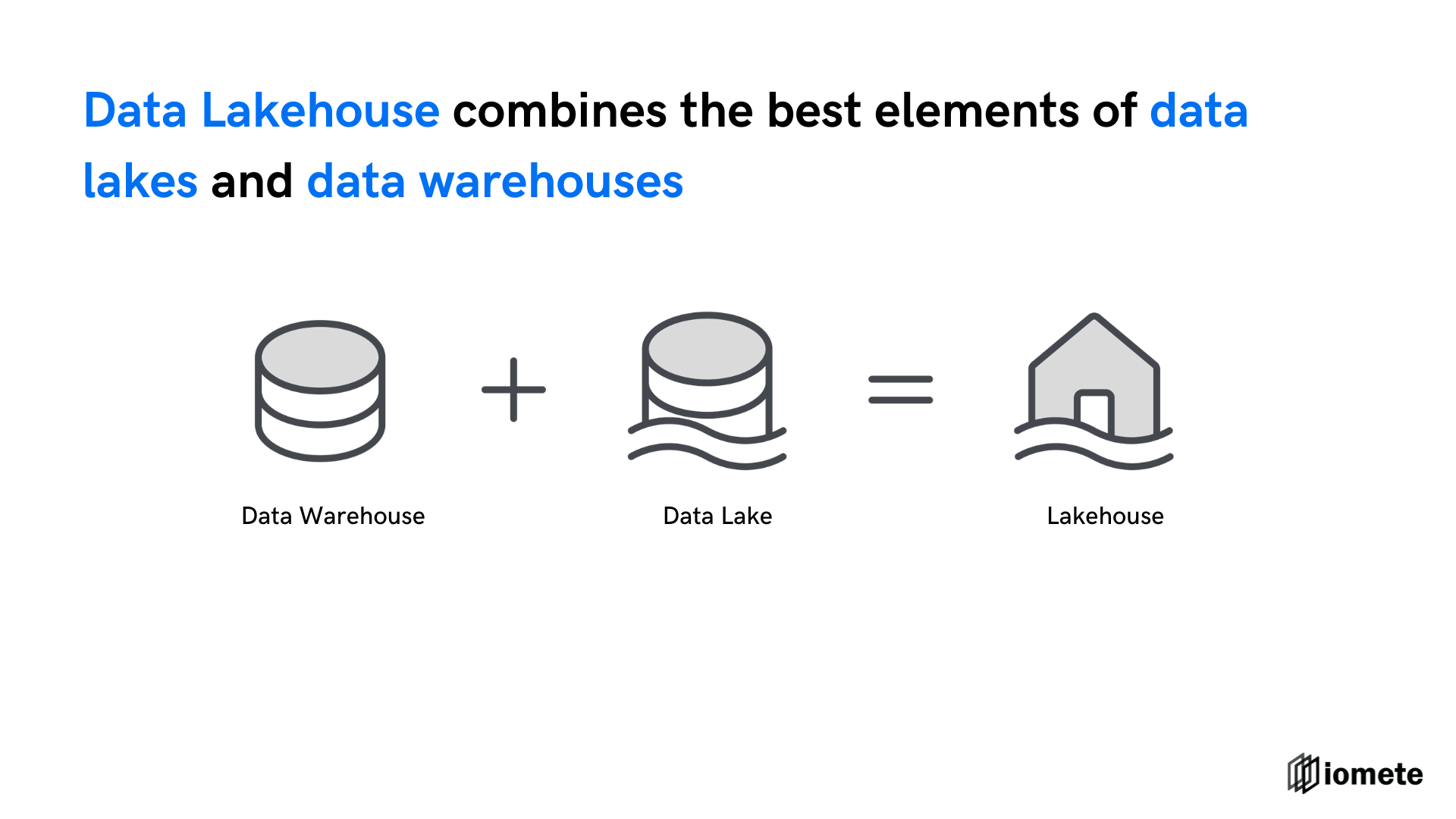
For those new to the concept of a Data Lake, don't worry. Our journey through the history of Data Lakehouses will shed light on how these technologies have evolved. By understanding their origins and the needs they address, we'll gain a clearer picture of why Data Lakehouses are the present and future of data architecture.
Now, let's embark on a voyage through the history and evolution of data warehouses and data lakes, culminating in the birth of the Data Lakehouse. What drove the industry to continually innovate and push the boundaries of technology? That's what we're here to explore.
The Evolutionary Journey: From Data Warehouses to Data Lakehouses
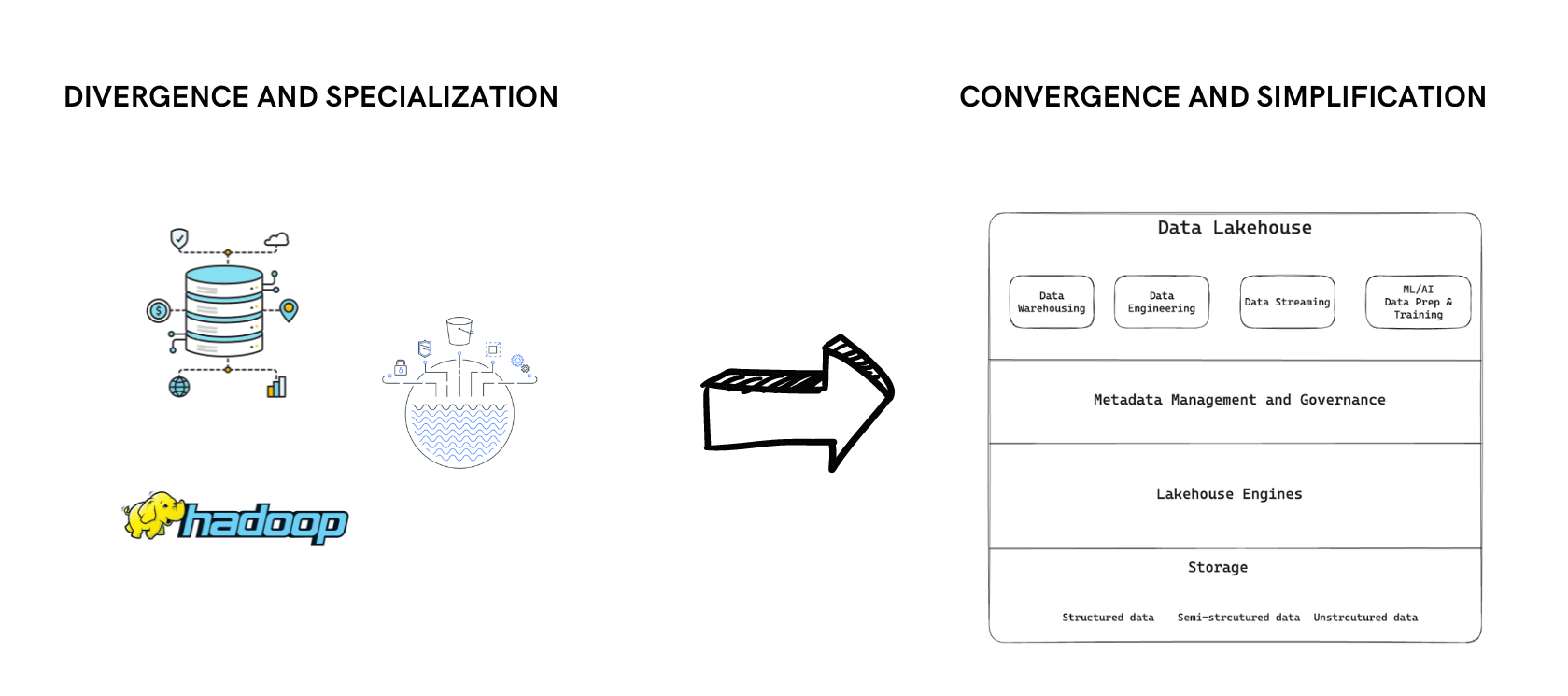
Evolution of Technology: Divergence to Convergence
In technology, we often see a pattern of divergence followed by convergence. This is the case with data storage and processing technologies as well. Let's look at how this pattern has played out in the data space.
80's, 90's: The Era of Data Warehouses
Data Warehouses: The Foundations of Modern Analytics
Let's start with good old technologies and data warehouses that have been well-known for decades.
Data warehouses are similar to traditional databases or RDBMS systems but specifically designed to handle wide-column analytical systems.
They focus heavily on querying large datasets, which differs from traditional RDBMS systems optimized for pinpoint, ID-based lookups.
This distinction led to the development of ETL (Extract, Transform, Load) processes, as the data models in data warehousing needed to be different from those in traditional databases.
Summarizing the critical characteristics of data warehouses:
- Similar to operational RDMS systems but optimized for analytical workloads
- Focus on querying large datasets
- Wide column tables
- Model differences between operational and analytical systems necessitate ETL processes
2000's: Hadoop Era
Enter the 2000s, and the landscape began to change dramatically with the introduction of Hadoop, inspired by Google's MapReduce paper. Hadoop was designed to answer the new Big Data needs:
Variety of Data
The rise of unstructured data presented unique challenges. Traditional RDBMS systems were well-equipped for structured data but fell short when it came to the new forms of data flooding the digital space. The volume of data skyrocketed, driven by the internet and digital technologies. Videos, images, logs, and signals from IoT devices – the diversity and quantity of data were unprecedented.
Unstructured Data Management
The need to store and process unstructured data was one of the most significant drivers for this new technology to emerge. Traditional RDBMS systems were primarily designed for structured data.
Volume of Data
Specifically, unstructured data is often generated in large volumes. Think about videos, images, logs, signals from IoT devices, etc. Another factor is the rise of the internet and digital technologies, which led to an explosion of data volumes.
Machine Learning and AI Demands:
Data Analysts and Data scientists needed to experiment faster. With the traditional systems, only some of the organization's data is available. Sometimes, they might need to get access to the raw form of data to find the correlations and patterns.
Speed of Data Access and Processing
With the old architecture, every time when they need a new data they have to go through the ETL process. This is time-consuming and not efficient. ML and AI require processing large datasets, often unstructured, for training and analysis. These fields need systems that can store all types of data and allow for rapid experimentation and analysis. Traditional ETL processes and data modeling were too slow for the dynamic needs.
Cost and Scalability
With data volumes increasing, the cost of storage and processing became a critical factor. Technologies like Hadoop offered more scalable and cost-effective solutions for handling large datasets compared to traditional data warehouses. Especially with its horizontally distributed nature and allowing to use commodity hardware.
Hadoop's Limitations
Hard to work with structured data
Hadoop addressed these challenges by offering a framework that could handle both structured and unstructured data. It was a leap forward, particularly in managing unstructured data, which was often generated in massive volumes. However, Hadoop was not without its complexities. While it enabled the handling of large datasets, traditional Data Warehouses remained the go-to solution for structured data due to their efficiency and ease of use in dealing with such data types.
Coupled storage and compute
One of the most significant downsides of Hadoop is that couples storage &compute. Why is this a problem?
Coupling storage and compute means that the same nodes are used for both storage and processing. There are two main issues with this:
- It's difficult to maintain and manage
- Un-flexible scaling. You have to scale both storage and compute together.
For example, having a PB of data doesn't mean you always need high-powered processing.
So, there was a need for a new architecture to simplify the management and scaling of data storage and processing.
2010's: Data Lakes
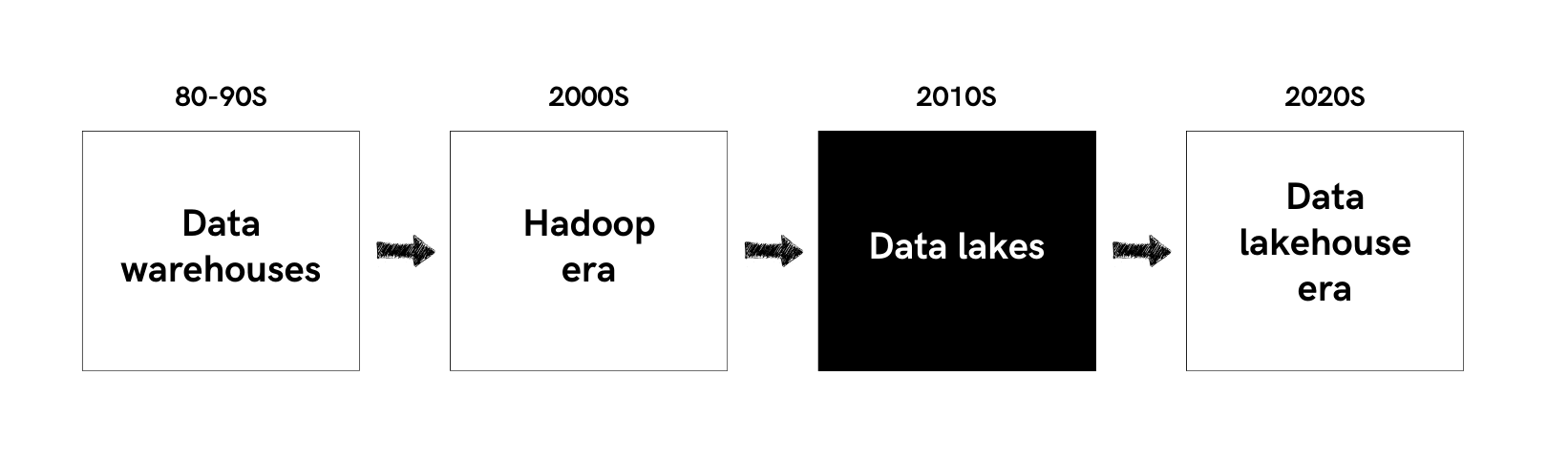
Data Lakes represented this new architectural approach.
- By decoupling storage and compute, Data Lakes allowed for independent scaling of each, paving the way for more specialized tools for storage and processing.
- And, making it easy to work with structured data by introducing new file formats like Parquet, ORC, and Avro
Decoupling storage and compute
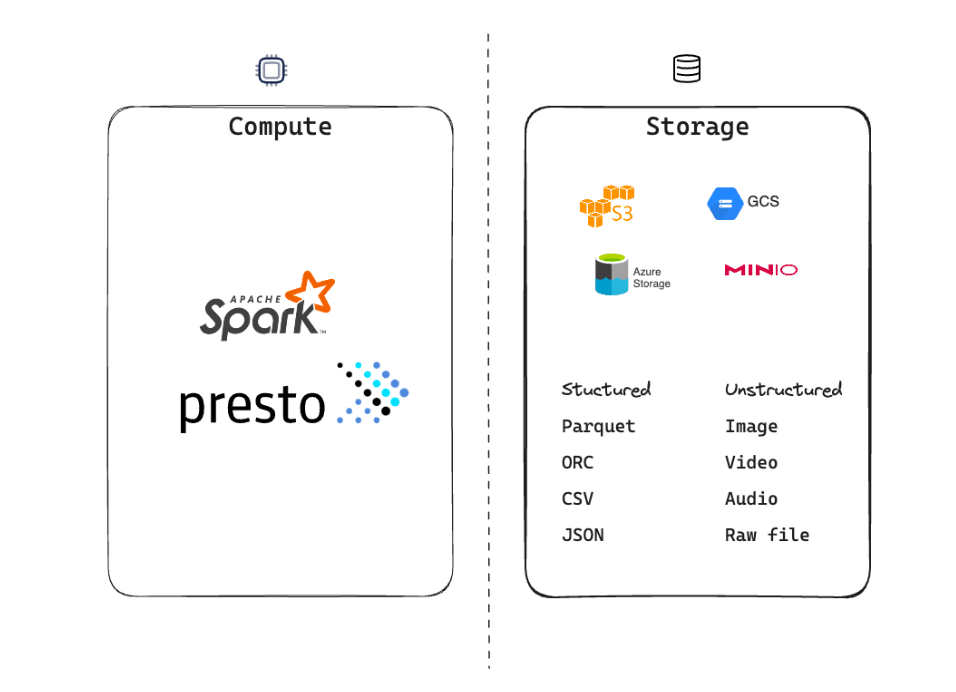
Decoupling of storage and compute was a game changer. It allowed companies to scale their storage and compute independently. Also, it made the industry to create highly specialized tools for each of these responsibilities.
On the storage side, cloud object storages such as AWS S3, Azure Blob Storage, and Google Cloud Storage became popular. These object storages are highly scalable, and specialized for storing large amounts of data in a cost-effective way.
And on the other hand, compute side, processing engines such as Apache Spark, Apache Presto, and others began to gain traction.
On the maintenance front, having decoupled responsibilities meant that object storage and computing sides could be managed separately.
How to make it easy to work with structured data?
To recap and jog your memory from our discussion about Hadoop, Hadoop initially tackled semi-structured and unstructured data. However, structured data was also growing enormously, and companies were striving to centralize their architecture. Given the opportunity to store and process data on a single platform, it would naturally be more efficient than maintaining two distinct systems.
Remember, Data Lakes, as new iterations of Hadoop, excel at processing unstructured and semi-structured data. The challenge lies in making it easy to work with structured data types.
Columnar file formats - Faster structured data processing
Despite the advancements, a significant challenge remained: making it easier to work with structured data within Data Lakes. The traditional file formats like CSV, while simple, were not efficient for large-scale processing. This led to the development of more sophisticated file formats like Apache Parquet, which offered a column-based storage layout, more suited to analytical processing.
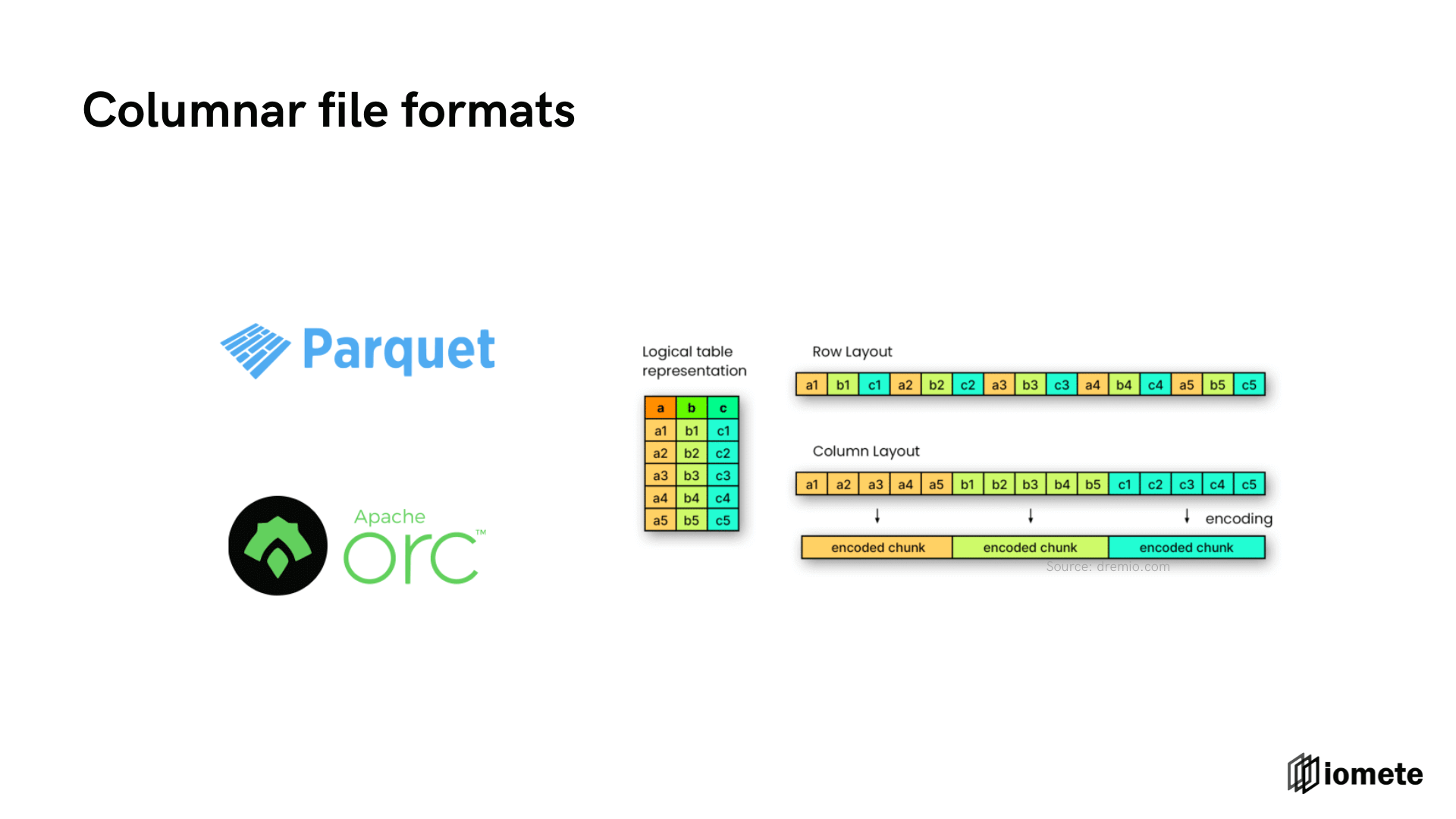
Column-based storage layout is more efficient for analytical processing. It's because analytical systems are typically wide column tables, containing many columns. Generally, only a few specific columns are queried, so in a row-based layout, even when querying only a couple of columns, the entire data would have to be retrieved.
Improved metadata management
New tools and services were also developed to improve metadata management. Such as Hive Metastore. These tools allowed for the creation of tables on top of files in the data lake, making it easier to work with structured data.
ELT (Extract - Load - Transform) vs ETL (Extract - Transform - Load)

Source: airbyte.com
ELT was an interesting side effect of the Data Lake architecture.
Traditional data warehouses lacked the processing power, necessitating complementary tools specifically handling the transformation part. The pattern was to extract and transform outside the data warehouse before loading it in. This practice had its drawbacks, primarily that any issue in the transformation layer could result in data loss, as data from operational databases or other sources doesn't remain static. In contrast, data lakes provide a cost-effective storage layer and open up a new way to extract, load into your data lake, and treat it as your historical source of truth. Then, you handle the transformation later. Furthermore, these platforms aren't just competent storage options, they're also powerful processing engines. Consequently, you can execute transformations directly inside your platform, effectively bypassing the need for an additional transformation layer outside your data warehouse.
Data Lake Limitations
So, what were the issues with data lakes? What prompted the industry to invent a new architecture?
- Data lakes predominantly operated on an insert and query basis!
- Lacking features like update, delete, merge operations and ACID transactions.
Data lakes were efficient and have since received numerous enhancements including columnar files like the parquet file format. Additional services were also incorporated to store metadata and subsequently expose the files in the data lake as tables, a concept we're familiar with from data warehouses. However, these engines predominantly operated on an 'insert and query' basis, lacking features like 'update delete' operations and ACID transactions.
The absence of these capabilities led some companies to develop in-house solutions. Third-party tools attempted to address this problem as well, especially the transactional aspect. Implementing a transactional system in such platforms proves challenging, given that any changes to files necessitate updates, and these files were immutable. Suppose your process broke down halfway through your changes. How do you revert all modifications? This requires some form of versioning and is further complicated when consumers view the edited files, seeing only partial results.
The goal was to evolve toward a state similar to the one we're familiar with from data warehouse technologies. This includes transactional updates, insert deletes, superior schema management and governance, and improved security. Achieving this necessitated new developments on top of data lakes.
2020s: The Emergence of Data Lakehouses
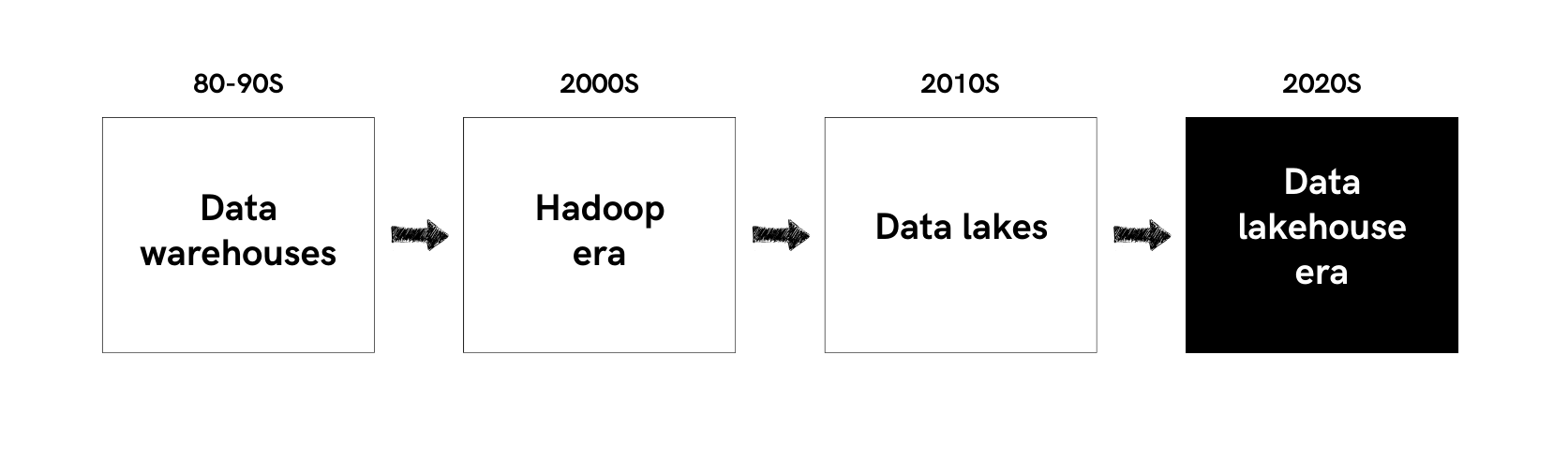
Data Lake limitations around transactional update/delete/merge operations, ACID transactions, and schema management led to a new architecture known as a Data Lakehouse.
A data lakehouse incorporates ACID transactions with update delete merge operations, improved data governance and schema management, and various other features like time travel versioning. Additionally, it provides enhanced metadata management. As the volumes of data are significant, its metadata storage also transitioned to object storage. These changes have brought data lake technology substantially closer to the level of data warehousing technology we're familiar with in terms of structured data processing.
Such technologies efficiently processed unstructured and semi-structured data, but the new data processing also made structured data processing more user-friendly. This is why we now see data lakehouses as a combined environment of data lakes and data warehousing.
Data Lakehouse- Architecture High-Level Overview

This is a high-level overview of the Data Lakehouse architecture. Certain components can be different depending on the platform, but the general idea is the same.
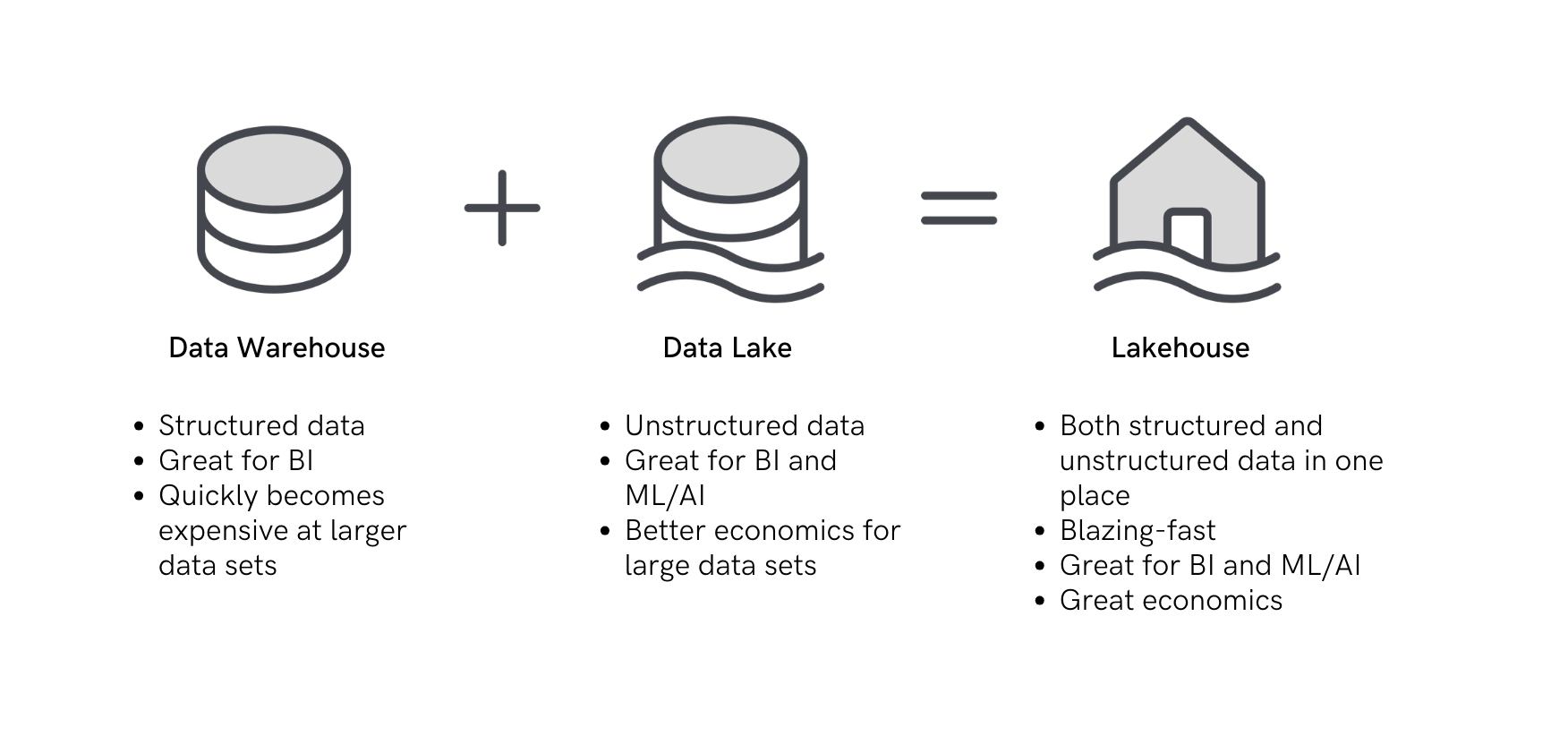
Wrap up - Data Lakehouse Summary
Embracing the Future with Data Lakehouses
As we reach the end of our exploration into the world of Data Lakehouses, it's clear that the journey through data storage and processing technology has been both dynamic and transformative. From the early days of Data Warehouses to the Big Data challenges tackled by Hadoop, and through the evolution of Data Lakes, each step has been a response to the growing and changing needs of data management.
Why Data Lakehouses Matter
Data Lakehouses represent the latest milestone in this journey. They offer a sophisticated, unified architecture that combines the vast, unstructured capabilities of Data Lakes with the structured efficiency of Data Warehouses. This fusion brings several key advantages:
- A Single System for Analytics and AI: Data Lakehouses provide a comprehensive platform for both data analytics and machine learning, streamlining various processes and offering a more cohesive data strategy.
- A Single Source of Truth: By eliminating data silos, Data Lakehouses ensure consistency and reliability across the data spectrum, from raw inputs to refined insights.
- Cost-Efficiency and Scalability: The architecture of Data Lakehouses allows for more cost-effective data storage and processing, facilitating data democratization for businesses of all sizes.
Looking Ahead
Thank you for joining me on this enlightening journey. As we continue to push the boundaries of what's possible in data architecture, I invite you to stay tuned for more insights and explorations in our upcoming webinars.
Webinar video where I talk about the history of data lakehouses:

Feel free to reach out to me on vusal@iomete.com if you have any questions or feedback. If you want to attend our next webinar about How to build a Lakehouse Platform, you can drop me an email.