data lakehouse vs data warehouse vs data lake

Data is a key differential in the new era of “Data is the new Oil”. Most people are familiar with data warehouses as a solution. As of today, data lakes & data lakehouses are considered the most popular data warehouse alternatives. Understanding the history, reasons for evolution, and value new solutions provide would allow us to bring information into perspective and the need for them. In this article, let’s explore the journey from warehouse to lakehouses and what are the main differences.
What is a data warehouse?
💡 Data warehouses evolved from the need to be able to use data from disparate operational systems for bringing insights to the decision-making process.
Data warehouses are created for bringing disparate operational data together to support decision-making. Data was scattered across various applications and consistently linking the data is not always possible, and data transformation on the transactional applications is not ideal, as they support key operational activities. So, a data warehouse is created as a repository of data where standardized value can be extracted for driving decision-making. The data warehouse is designed to reduce the workload of the operational database. While data warehouses are an excellent solution for structured data till a certain limit of data, many major enterprises must increasingly deal with unstructured, or semi-structured data. But also, many organizations have multiple data warehouses serving different purposes, which creates lots of complicated setups for fetching value from it. Data is duplicated, re-purposed, and takes different results as the single data warehouse cannot handle or the team cannot handle all the requirements at hand.
Structured data is generated by enterprise applications and information systems like ERP, CRM, and other system or record systems.
Semi-Structured Data is Electronic Data Interchange (EDI) files, spreadsheets, events, RSS feeds, and sensor data.
Unstructured Data is either textual or binary. • A text file may contain the contents of various tweets or blog postings. • Binary files are often media files that contain image, audio, or video data.
Limitations of data warehouses
Data warehouses started to hit their limitations with the data needing to be structured specifically in a specific format to get value, the usage of Inmon, Kimball, Inmon-Kimball, and Data Vault provided much-needed guidance for extracting value from the data. Data warehouses need to look at options to work with the ever-increasing volume of data and also the velocity of data, as the data is available with logs, IoT devices, and other real-time data feeds which were providing new varieties of data in JSON, XML, and other formats. Data variety also originated from the use of case-specific data storage requirements such as graph databases, document databases, key-value stores, etc.
So, there was a need for some innovation to provide alternatives for these limitations, which would smoothly pass into our next section while trying to answer why we need it.
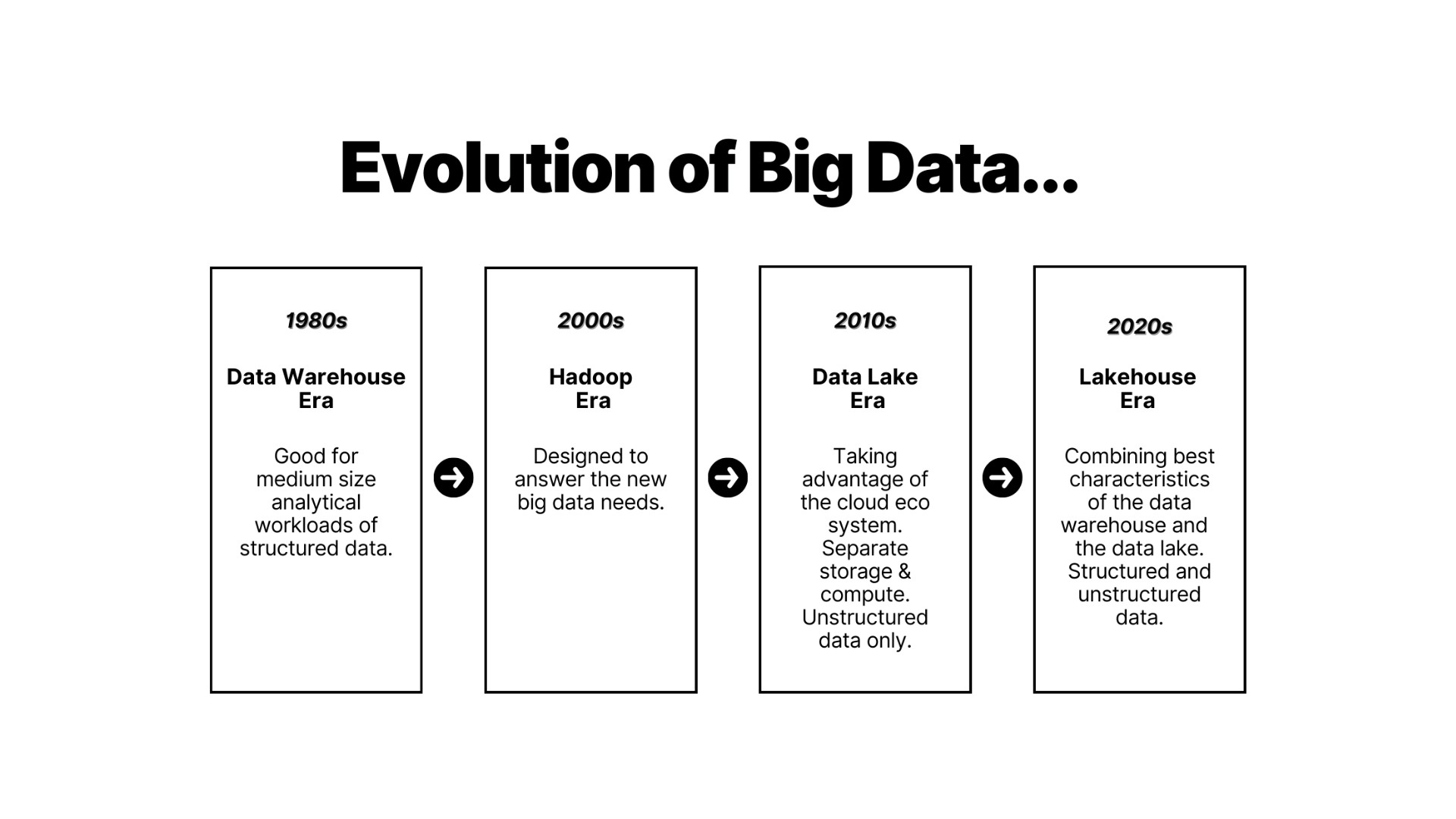
Why did data analytical tools need to change over time?
Data analytics started to investigate the value of data that is not being processed enough and started to unearth new opportunities to improve the experience, to have a better strategy, to calculate a model value more accurately, and so the requirement for data analytical tools evolved. Over the years, the volume, velocity, and variety of data increased, and previous technologies ended up with unsolvable data workloads in solutions such as data warehouses. Hadoop along with HDFS revolutionized the opportunities to extract value from data. Hadoop can process massive amounts of data with commodity hardware, without the need for huge server computers which are required for computing in Data warehouses. Data warehouses, on the other hand, are not practical or cost-effective in this situation. But in the 2010s data technology started to move to the public clouds. Clouds enabled the storage of petabytes of data at cheaper prices, which provided new opportunities for working on data and delivering analytics. To enable analytics in multiple ways, data storage, metadata, and computing are decoupled.
What is a data lake?
Data lakes can store massive amounts of data which can serve several purposes such as real lakes. Data lake is a storage repositories that can store large amounts of structured, unstructured, and semi-structured data. On a data lake, data from disparate sources can be stored and processed with appropriate technologies. The ability to access the same data for various purposes as data is stored in its original format provides opportunities to execute Reporting and ETL at the same time, which is a big advantage.
Disadvantages of data lake?
Data lakes were cost-efficient, with no need for hundreds of servers, or storage. But Data lakes had a big problem, data is dumped rather than having structure assigned to data. Data Lakes became Data swamps, which made data usability very challenging. On data warehouse technology data engineers were having specific structures and processes which made data available in a specific format quickly to generate reports, which was not possible immediately in data lakes.
What is data lakehouse?
The data lakehouse concept takes advantage of data lake and data warehouse and brings them together. Data lakehouse provides possibilities to can access the data in the data lake as a table, and we can use SQL for querying data.
Data engineers can organize the data according to enterprise needs. Whoever needs data can access each data set and use it in whatever schema they like. Before data lakehouses, converting all datasets to the same format was challenging. Data lakehouses provided an option to do this consistently. Where does the data lakehouse idea come from?
The data lakehouse idea comes from the requirement of the data needs to be available generically for both Analytics, and reporting in a single location. ETL has been the mainstay for a long time in Data warehouses, but ELT takes a higher stage in Data lakehouses. Large amounts of data can be stored for analytical purposes now and future.
ETL - the process of transforming data while delivering data from source to destination
ELT - the process of loading data in original format for various consumption needs
Data lakehouse was able to provide data using table formats such as Iceberg, which provided a new level of abstraction. Data was decoupled from metadata, where the data structures themselves can keep changing over time. So the data is now stored in more efficient formats such as parquet, Avro, or ORC with table formats such as Iceberg providing the metadata required for IOMETE **(or similar) **to provide analytics on top of data. Now there is a lesser need for some layers such as staging in traditional DWH, as the data itself can be processed only when required through the stages once the data is stored in its original format.
Advantages of Data Lakehouses
Data Lakehouses are cost-efficient work with cloud storage and have functionalities like a data warehouse while enabling data analytics for Data Scientists. The opportunity of hiring servers only when required on cloud technology provides flexibility for companies. For instance, If your company does capacity planning and figures out that you need to get about twice as much data in the next two months. Can your database's infrastructure or hardware be upgraded within the next couple of days? It is also critical to consider modeling your schema whenever there are large volumes of data. That modeling is not an easy task and in 1 server that is expensive but in data lakehouse technology you pay low amounts for cloud storage and pay as you go for computing. How does computing work on the cloud? Let’s have a closer look at computing on cloud storage. On every request for analyzing data, the master node (server) takes the query and plans it, and sends tasks to executors (a group of cluster machines) to process. Then, the outcome is back to the user through the master node.
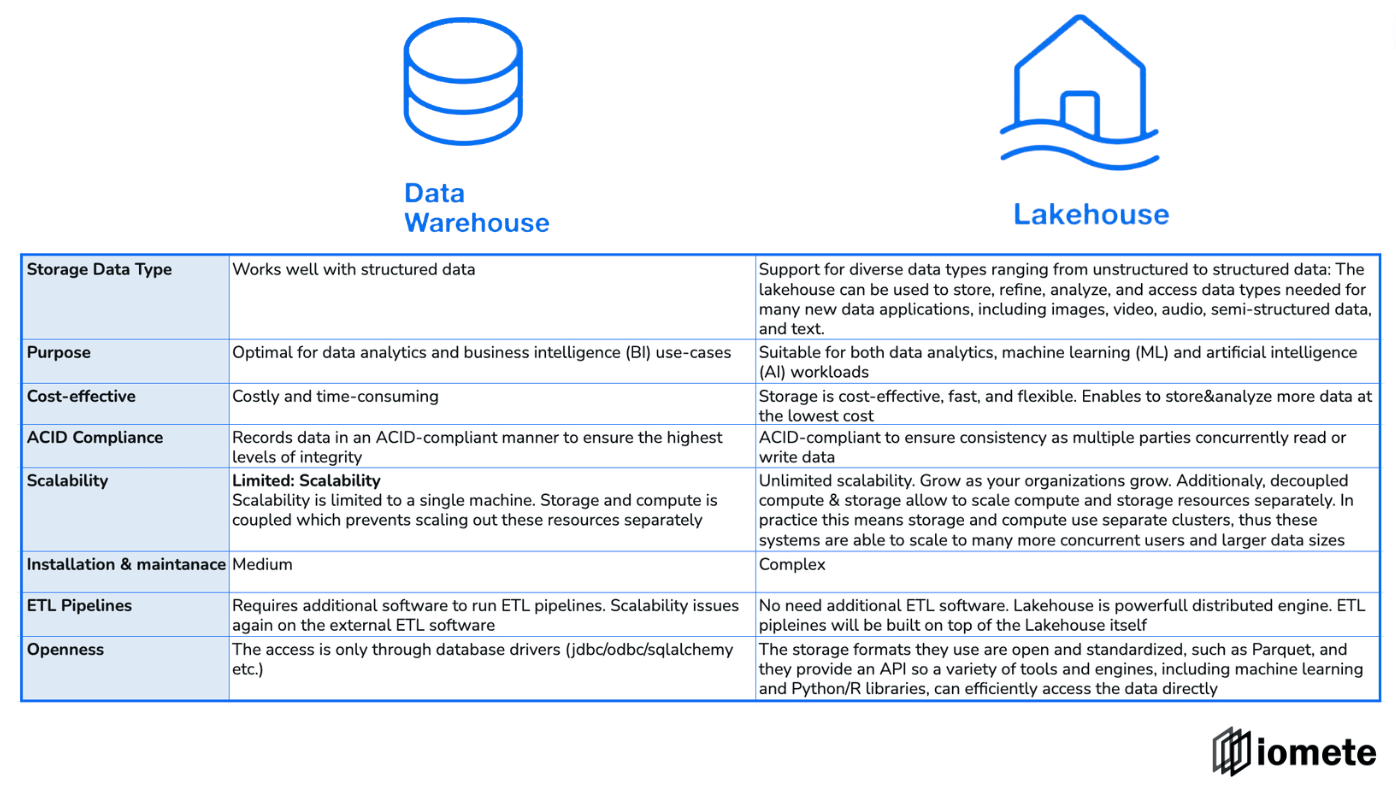
What are the differences between a data lakehouse and a data warehouse?
To sum up, the graph below shows the main differences between data warehouses and data lake houses:
What is an IOMETE Modern Data Platform?
Modern Data Platform can take data from streaming, batch data, and stitch it together for delivering multiple values. We can support you in your endeavor to provide the right setup to bring your raw data (crude oil) into usable oil through data lakehouse implementation at a very affordable price.
Let’s get connected for taking the journey towards enabling your organization for bringing value out of data.